哪位大佬能从mdx文件中提取出txt目录(或详细词条书签)文件?需要这个文本目录进行统计,有没有什么软件能反向提取呢?或者提供该文件的目录(词条-页码)txt也可以,非常感谢!
没看明白你需要的是什么。如果你对 mdx 不熟悉,请配图说明你需要的是什么,哪些内容。图越详细越好。
谢谢回复,是需要这个mdx中的书签索引(含词条-页码)txt文件(一般制作词典mdx都需要扫描文件和书签索引),我需要的是那个单独的书签索引文件,主要用来做统计。请问怎么提取出来呢?
文件在这里:链接:百度网盘 请输入提取码
提取码:cn2a
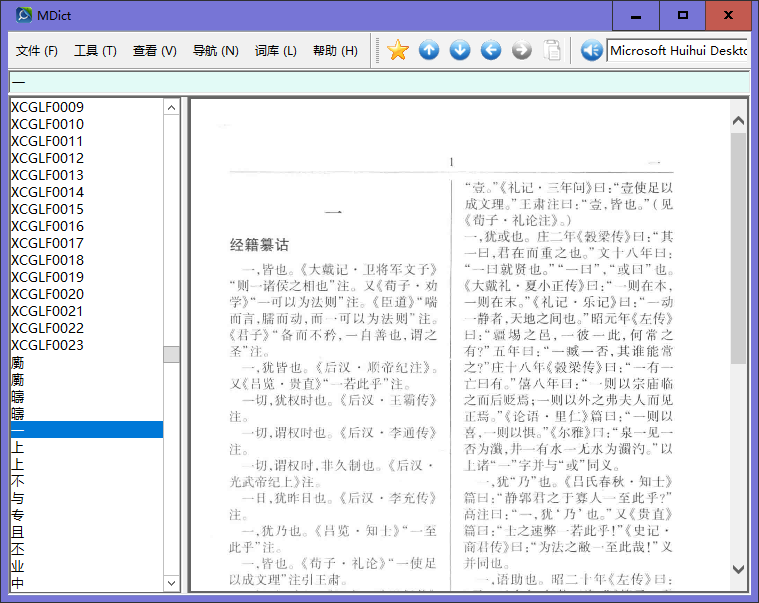
就是左边的这个,哪里有解包软件呀?有具体的名称么?
虛詞詁林_keywords.zip (3.4 KB)
我最近在做mdict解析库和程序,帮楼主提取出来了。另外mdict是没有分页的概念的,所以也不存在页号,我只能提取所有关键字。
1 个赞
看了下这个mdx的结构是
词条的内容只有@@@LINK=XCGL0702之类的,后面的数字应该是页码,看楼上发的词条“一”对应页码1,应该是没有偏移的,而像XCGL0702这种词条则是<img …… html
提取出的内容:
一 0001
上 0037
上 0445
不 0109
……共720个
entryList.txt (6.3 KB)
1 个赞
拜读一下,你就知道。信息教程这些都很多。如这个有详细介绍:https://m.php.cn/faq/1987047.html
1 个赞
SourceEditor,里面有个headword 功能可以直接导出目录的,非常方便。
SourceEditor.rar (4.3 MB)
1 个赞
请教大侠是怎么推算出来的词条和页码的对应关系的呢?我看楼上提供的目录文件,中文汉字有1400个左右,而带数字页码的行只有一半(700左右),无法一一对应呀。但大侠提供的索引文件却是一一对应的,我查了原目录,词条和页码对应是非常准确的,没有错误。这是怎么做到的呢?能详细说一下么?
非常感谢,能够提取出来数字和词条的原始数据,但不知道如何能自动对应起来(一个词条对应一个页码,比如“一”对应“1”)
这个mdx里的内容比较特殊,比如词条“一”的内容是"@@@LINK=XCGL0001",这在mdx是指转到“XCGL0001”这个词条,而“XCGLxxxx”这些词条是真正用来显示图片的,这些词条内容像这样
<img src="/XCGL0740.jpg" width="100%"><br><center> <a href="entry://XCGL0739">上一页</a> <a href="entry://XCGL0741">下一页</a> <br><br><center> <a href="entry://XCGLF0004">再版说明</a> <a href="entry://XCGLF0006">原版序</a> <a href="entry://XCGLF0008">凡例</a>
<img …是图片 <a…是可点击的链接,不难看出XCGLxxxx后面的数字表示页码,得益于这种结构,提取很简单还不会出错