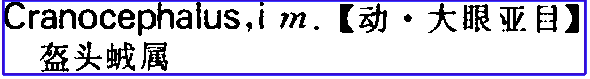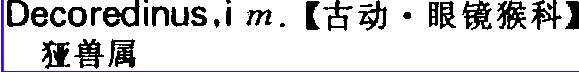之前的帖子在这里,虽然讨论了很多文本化方案,但过了两年都没制作完成。
我开发了校对工具后就准备用这个试试,之前已经用夸克识别了一遍,然后又用gemini识别了文本,配合paddleocr vl1.5提供位置信息,周末用了两天时间以夸克为主文本进行了粗校,修复了大部分错字问题,不过如果两个ocr版本错的一样就不容易发现。
当前版本是词组放在主词条后面,添加了词组跳转链接,然后因为格式很简单,没有加任何样式。
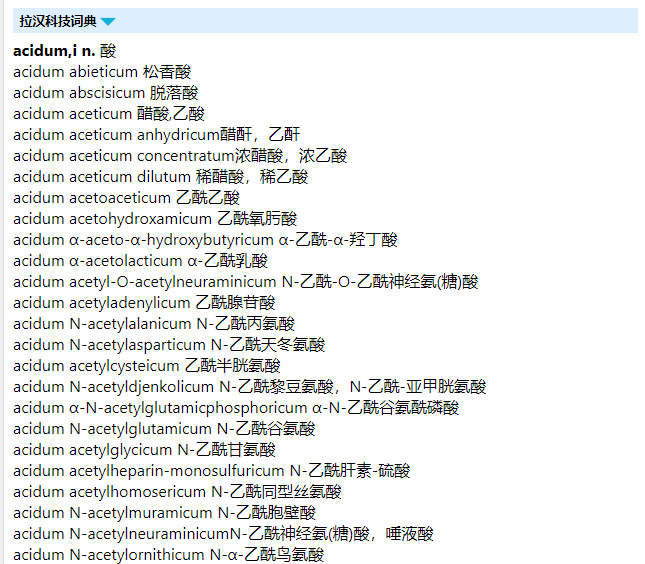
效果如图:
mdx:
拉汉科技词典.mdx (2.4 MB)
如果有人想改样式直接下载python脚本然后修改就行
生成mdx源文件的脚本:
parse_files.py (3.4 KB)
当前版本文本:
拉汉科技词典_quark.txt (4.5 MB)
其他对比文本:
ocr_results.zip (17.0 MB)
拉汉科技词典_gemini.txt (4.5 MB)