u3842
1
mdx 格式并不规范,无论是外在的文件结构还是内在的内容,即使现在mdx已经被逆向或研究透了,但读取并不顺利。
目前通行的是mdx 2.0,内容被分块压缩存储,有定义标题 描述 编码 加密……,内容是HTML,也可以是@@@LINK= 文本来链接到其他词条,明确写道sound://只支持wav和spx,但实际是想用啥就用啥,把说明当摆设了,官方的builder里描述的也是寥寥草草,还有很多细节并没有细讲,比如词条名不能有哪些字符、重复词条的处理、link的是完整的词条名还是像a#p2这种能定位到某个位置、不合法的编码,更不用说文件结构了。
说到文件结构,更是一坨屎山,mdx 2.0仅支持UTF-8、GBK、UTF-16编码,重点是后面,有人能给你造出其他编码的;任何一个mdx 2.0都加密()索引的索引,解密还用到ripemd128;支持加密但几乎是个摆设,只额外加密索文件中表示哪哪的字节数啥的,内容一个字也不加密
上面提到的只是众多坑的一部分,后面又会遇到多少坑也无法预知,继续使用这个格式,屎山只会越堆越高,所以有必要采用新的词典格式,开放、规范,至少解决上面这些乱七八糟的,废掉无意义的加密
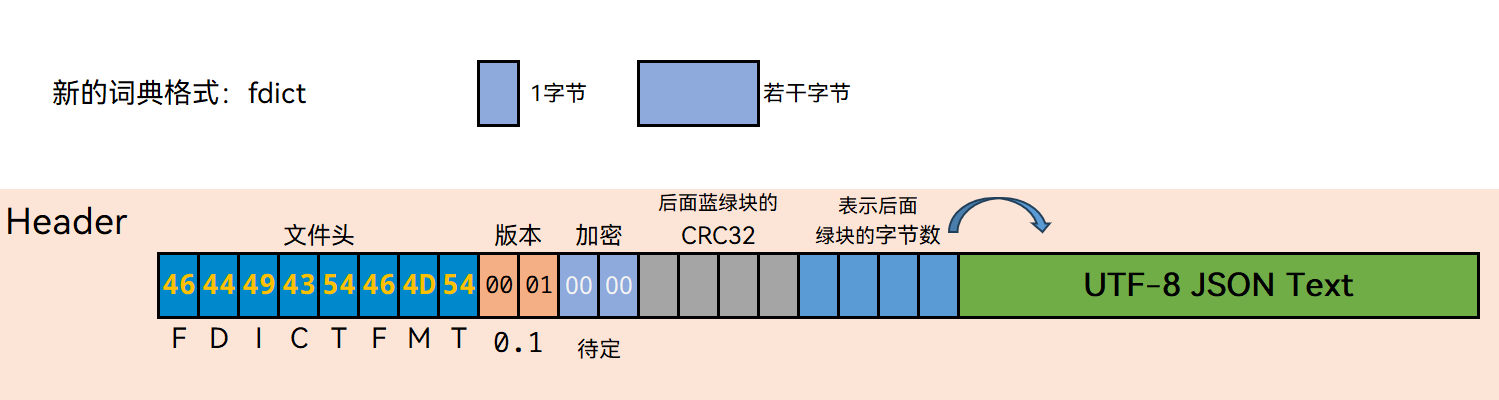
新格式尚未定下,随时可能有改动,如有建议,欢迎跟帖,目前计划的是一个新的文件格式,大体上是 头部、索引、主数据,数都为无符号大端序。
2026-1-28 暂定了文件头
- 固定的8字节文件头
- 接着版本号2字节,n.n
- 加密,2字节,待定
- CRC32,4字节,由5、6生成
- 表示后面JSON块的字节数,4字节
- JSON块:编码为UTF-8的JSON,有说明字典的 标题 描述 创建日期 词条数 等,待定
winn
5
mdx并非完美,但能达到99%吧。完美的系统不存在。windows不完美,linux也不完美,不影响其流行和使用。mdx比其他格式好得多,这是它成为主流词典格式的原因。适应它的一些不足,可便利使用。当然如果能推出一种更好的格式,一定会喜闻乐见,普大喜奔。
说明旧路线的潜力基本被挖尽了,继续在同一条路线上优化收益很小。与其追求一个完美的 MDict,不如从头设计一个面向未来的新体系,从零开始的重构,挖掘用户真正需要的东西。
mdx 虽然不完美,这个就和 latex 一样,能覆盖很多情况。新的东西需要能覆盖最起码的情况,然后逐步扩充,latex 对应的新的东西就是 typst。
seid
9
我觉得吧,能顺利制定一个更好的格式的人,至少是一个不依赖AI而只使用C语言独立编写一个比mdict更好的软件的人。
xmg123
11
有时候不一定非要只能有我不能有你或者有你没我的状态
winn
12
我的想法是不一定非得从格式方面入手。不如考虑从功能入手,推出一个集合几种主流词典软件优点的应用。有词头正则(通配符)搜索、正文正则(通配符)搜索,加上目前Mdict的功能,有这些足矣。词典软件无需太复杂,能查词找词就够用了。全部词头的列表显示这点必须有,你不能让用户去猜测这个有还是没有,去搜索才显示出来。
新格式的困境在于不仅要打败 MDX,还要和 MDX 成熟的生态竞争,它的词典软件需要支持所有平台,这样才有可能推广开来,而这个工作只能格式作者自己来完成,所有工作都压在一个人身上,这实在是太困难了,还不如直接挖掘新的需求,开辟新的战线,吸引新的用户。
感觉 mdx 像是早期的 markdown,
不是很严谨,也缺些功能。
但就是很多人的选择。
是的,主流英汉词典已经满足了绝大多数用户的核心查词需求,小语种所剩的生态位相对有限。类似不区分音调的查询、后缀查询、正则查询等功能都属于典型的长尾需求,用户规模和使用频率都不足以支撑一款新的独立词典软件的开发。
要想找到真正的新机会,就必须跳出传统词典软件的框架,从更广的语言工具与知识应用场景中重新定位词典的价值。
瞎喷个啥,完全不知所谓的在那儿乱喷,不知道楼主是不是开发者,如果是的话反而应该会觉得mdx采用html反而是优点,如果不是开发者的话你说这些的是想其它开发都专门给你开发一个新的格式和词典软件之类?哦,你要是词典制作的话,那多少也应该懂些开发技术的吧。
mdx格式如何其实最终还是要看运行软件是怎么解析的,现在基本差不多都是 webview之类的来解析,所以可以不受你说的 明确写道sound://只支持wav和spx,但实际是想用啥就用啥 的约束,可以用其它媒体文件,因为现代web的前端也就是html5、javascript、css3 技术已经非常成熟且强大了,也是现在目前最主流的跨平台方案,自身就支持mp4, mp3, ogg之类的解析,不行还可以用其它js库解决,甚至可以调用外部播放器什么的,这难道还不是一种优势么。还有什么 被分块压缩存储,UTF-8、GBK、UTF-16编码 什么什么之类的有啥问题么,只要能解析不就行了。还有说道索引加密那个,你自己都在说废掉,那你不加密就是了不就行了。
至于你说的 名不能有哪些字符、重复词条的处理、link的是完整的词条名还是像a#p2这种能定位到某个位置、不合法的编码 这些问题其实最主要还是看 词典软件的实现,说到底与其说mdx格式本身问题还不说现在因为解析mdx的词典众多,它们的对mdx的一些规则实现不一致导致了一些mdx词典在不能平台或者不同的词典软件上出现差异的问题。这个确实和mdx本身规则相关,感觉规则格式之类的其实应该由词典软件开发者来共同制定才行,可惜这个领域不像国外有专门的 rfc 什么的,专门制定规则,每年都有更新,开发都有个方向。
话说,mdx词典的一个痛点的话,感觉估计是 不是原作者的话不太好修改,之前想改一个词典完善下啥的,结果解包后 看那原始文本 真要改的话不晓得要死好多个脑细胞,别说这个真有点儿像去改已经编译打包好的bundle.js文件一样,懂前端的应该知道说的啥。
感觉其实制作 mdx之前可以先定义一个 词典词条的元数据文件 再用这个元数据文件编译成 mdx文件就好了, 比如一个json的元数据文件
[
{
"wordhead": "条目1的词头",
"phonetic ": "条目2的音标",
"其它属性名": "其它属性值"
},
{
"wordhead": "条目2的词头",
"phonetic ": "条目3的音标",
"...": "..."
}
]
发布时把 元数据文件,生成的mdx和生成的脚本之类的一块儿发出来,以后自己或者给其它人维护修改就简单得多了。
我之前制作词典就是这么干的,提供了json文件和生成脚本。不过json字段只有词头,扩展词条和xml三个字段,其他属性很难处理的,因为可能结构非常复杂。
u3842
21
你先写个mdx的reader再找茬吧,看看是不是会像你以为的容易,其次,我也没说HTML哪不好了,别以为你随便造个其他编码的就能随便读,索引部分涉及到单位编码的长度还有终止符,这是你想造啥就造啥的?合着能跑就行?就非得这出bug了加个elseif那出bug了加个else那蹦出个这个再打个补丁?还搁这把说明当摆设,MIME对不上能放得了?还不得额外给你装的其他格式打个补丁?
mdx的reader不是现成的有python的脚本么,新写个有啥意义。我只是想说现在mdx其实没那么不堪感觉你说的问题不是mdx的问题,有些问题是词典软件本身实现造成的。我也没想想造其它编码、格式之类的,只是提了个制作 mdx的一个方式优化下生成成品的mdx流程而已。因为我之前是想去修改个mdx词典,发现解包后想改里面的内容太恼火了。至于索引啥的我对这个也不熟。
真有开发者会认为html好用?去适配一遍就知道了,无数坑点等你踩。每个webview兼容性不一样,词典软件开发者用的也不是同一个webview,词库制作者还得一个个匹配市面上的词典软件,就算真有新格式出来还是相同的局面。反而是索引机制没什么人提,可能有人认为逆序搜索、带符号拉丁字母搜索是小众需求,但需求再小也要上,这是影响词典查得率的东西,哪怕你用html渲染出再好看的页面也没用,查不到就是查不到。