以下可能并不详尽,描述可能不准确或有错
mdx 2.0和mdd 2.0结构几乎一样,下面有说明
Header
mdx文件并没有固定的文件头,其开头4字节表示后面紧跟着的UTF-16编码的XML的字节数,解析XML时要去掉末尾的0x0000终止符,后面跟着Adler32校验和,其中校验和为小端序,文件中其他Adler32都为大端序,没额外说类型的按大端序处理。
竖小方块表示1字节。横大方块表示若干字节并且看起来长度一样不能说明大小一样。
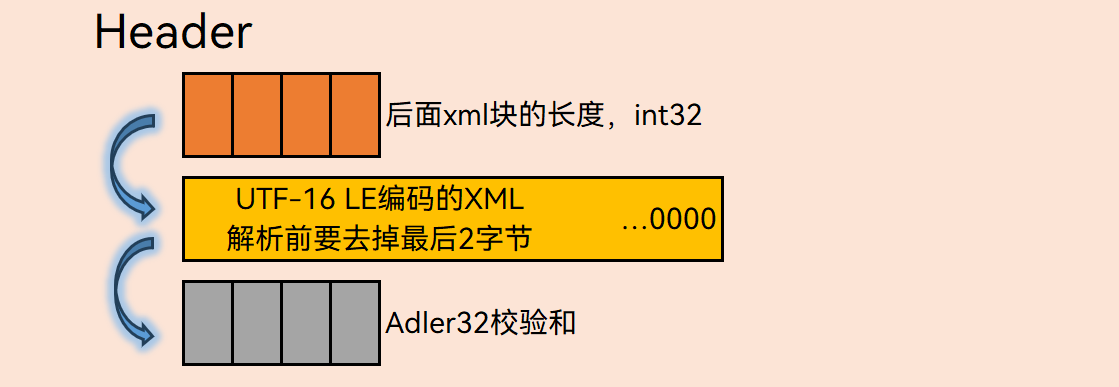
XML解析后看起来是下面这样的(添加了换行和说明)
<Dictionary
GeneratedByEngineVersion="2.0" 文件版本,2.0。
RequiredEngineVersion="2.0" 似乎是最低兼容的reader。
Format="Html" 内容的格式,可能的值是"Html"或"Text",在mdd中,为""。
KeyCaseSensitive="No" 告诉reader要不要区分词条名的大小写。
StripKey="Yes" 未知。
Encrypted="2" 加密,转到二进制,高位为1表示index’s index block被加密;低位为1表示index部分前40字节被加密。2转到二进制为10,高位为1,表示只加密索引的索引。这里不细讲低位为1的加密。
RegisterBy="EMail" 为"EMail"或"DeviceID",只有Encrypted的低位为1才会用到,用于解密时识别。
Description="描述" 描述。
Title="标题" 标题。
Encoding="UTF-8" indexIndex、 index 和record 里字符的编码方式。在mdd中为“”,indexIndex和index里字符按UTF-16 LE 编码。
CreationDate="2026-1-1" 创建日期。
Compact="Yes" "Yes"表示其中某些字符串将根据StyleSheet中指定的方案进行替换,具体官方bulider文档里有说明。
Compat="Yes" 同上。
Left2Right="Yes" 未知。
DataSourceFormat="106" 未知。
StyleSheet="" 参考compact。
RegCode="0102030405060708090A0B0C0D0E0F" 注册码,或位于mdx同目录下的dictionary.key文件中。
/>
Index Section
这里先说明一下“block”,不同“block”虽然原始数据不同,但这些block外在格式都一样,都有相同的头,数据都可以被压缩并存进block内。

前4字节:0x0?000000,?=0表示数据不压缩,1表示lzo压缩,2表示zlib压缩
继续4字节:解压后的数据的Adler32,大端序
再继续若干字节就是这个block的(被压缩的)数据了
特别地,当Encrypted的高位为1时,index’s index block内有加密(不加密block内前8字节)。具体加密算法是按照字节
- 异或当前字节在这段的位置i(0开始的十六进制,取位置的最后一字节)
- 再异或key的第i%16个字节(0开始,0-15),%取余
- 再异或上一个加密完毕后的字节,起初没有上一个的,异或0x36
- 最后互换前4位和后四位,这字节加密完毕
接下来是Index(索引)部分了,8字节表示index block的数量
接下来8字节表示这个mdx里的词条总数
接下来8字节表示index’ index block内数据的解压后(如需要)的大小
接下来8字节表示index’ index block的字节数
接下来8字节表示所有index block字节数的总和
再往下4字节就是上面这40字节的Adler32了,小端序。这4字节+(表示拼接而不是相加)0x95360000的Ripemd128(一种哈希算法)的结果为上面的key,16字节。
如果Encrypted属性的低位为1,前40字节被Salsa20/8加密。这里不深入探究。
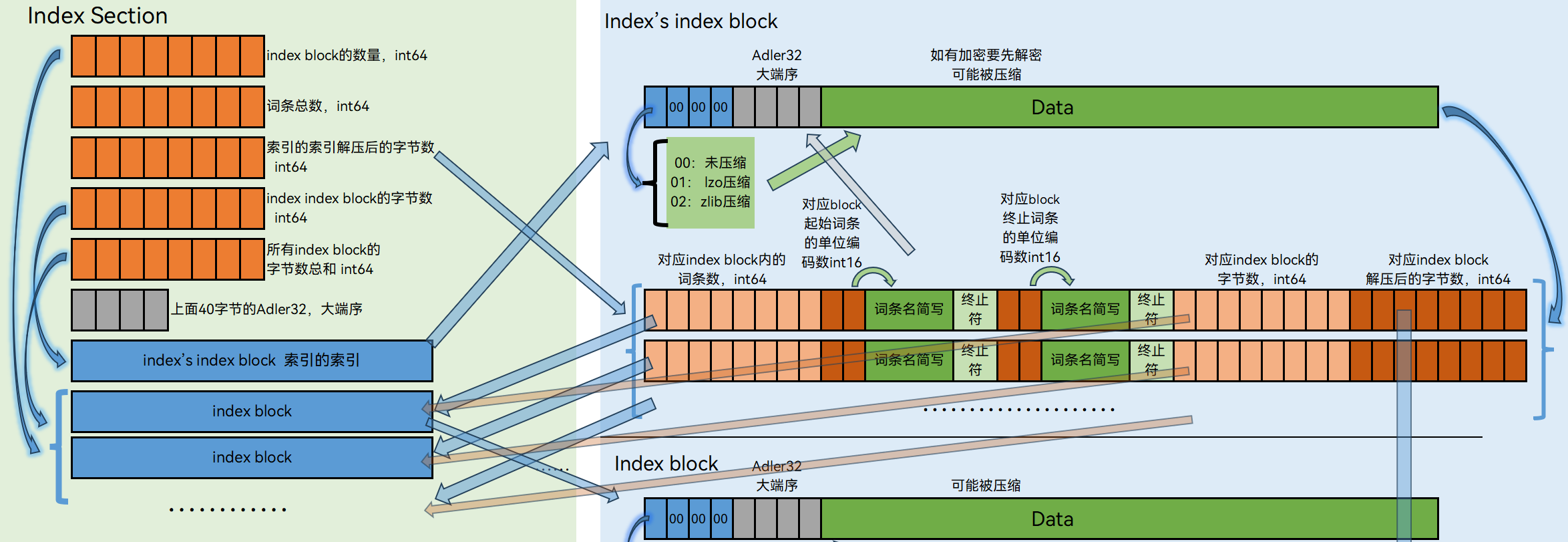
接下来就是index’ index block,只有一个,这个可以称为“索引的索引”,循环记录了相对应的index block内的
第1个index block的词条数(8字节)
第1个index block的起始词条的单位编码数,可能这么说不准确,如果是头部xml的Encoding=UTF-8或GBK,则直接是后面的长度,如果为UTF-16或为空,则后面的长度要*2,(2字节)
……起始词条名(长度不定,不完全等同于正式的词条名,在mdx内:至少没空格,没符号,全小写,比如activoperateavehicle;在mdd内:有额外的\来表示子目录,比如\media\english\ameprons\abrade.mp3)
……终止符,如果编码为UTF-16则为2字节的0x0000,否则为1字节的0x00
……终止词条的单位编码数…(2字节,同上)
……终止词条名(长度不定,同上)
……终止符,同上
……字节数(8字节)
……数据解压后的字节数(8字节)
第2个index block的词条数(8字节)
第2个index block的起始词条的单位编码数…(2字节)
……
第2个index block的数据解压后的字节数(8字节)
第3个index block的词条数(8字节)
……
紧跟着index’s index block后是index block,有多个,其解压后是这样的
第1个词条 对应在record部分累计解压后的开始位置 (8字节)
第1个词条的词条名,若干字节,以终止符结尾
第2个词条 对应在record部分累计解压后的开始位置 (8字节)
第2个词条……
第3个……
……
Record Section
这里面就是数据占比最多的部分了,主要内容都在这,结构如图。
深棕色的表示对应单个block数据解压后的大小,而上面获取到的累计解压后的开始位置(记为offset)并不能直接定位到相应的block,而是要根据offset算出在哪个block以及在这个block解压后的开始位置,还要有紧接着下一个词条的offset来判断这个词条的结束位置,内容可能在多个block内,mdd直接返回原数据,如果这是mdx,还要去掉末尾的终止符(编码为UTF-16则为2字节的0x0000,否则为1字节的0x00)。
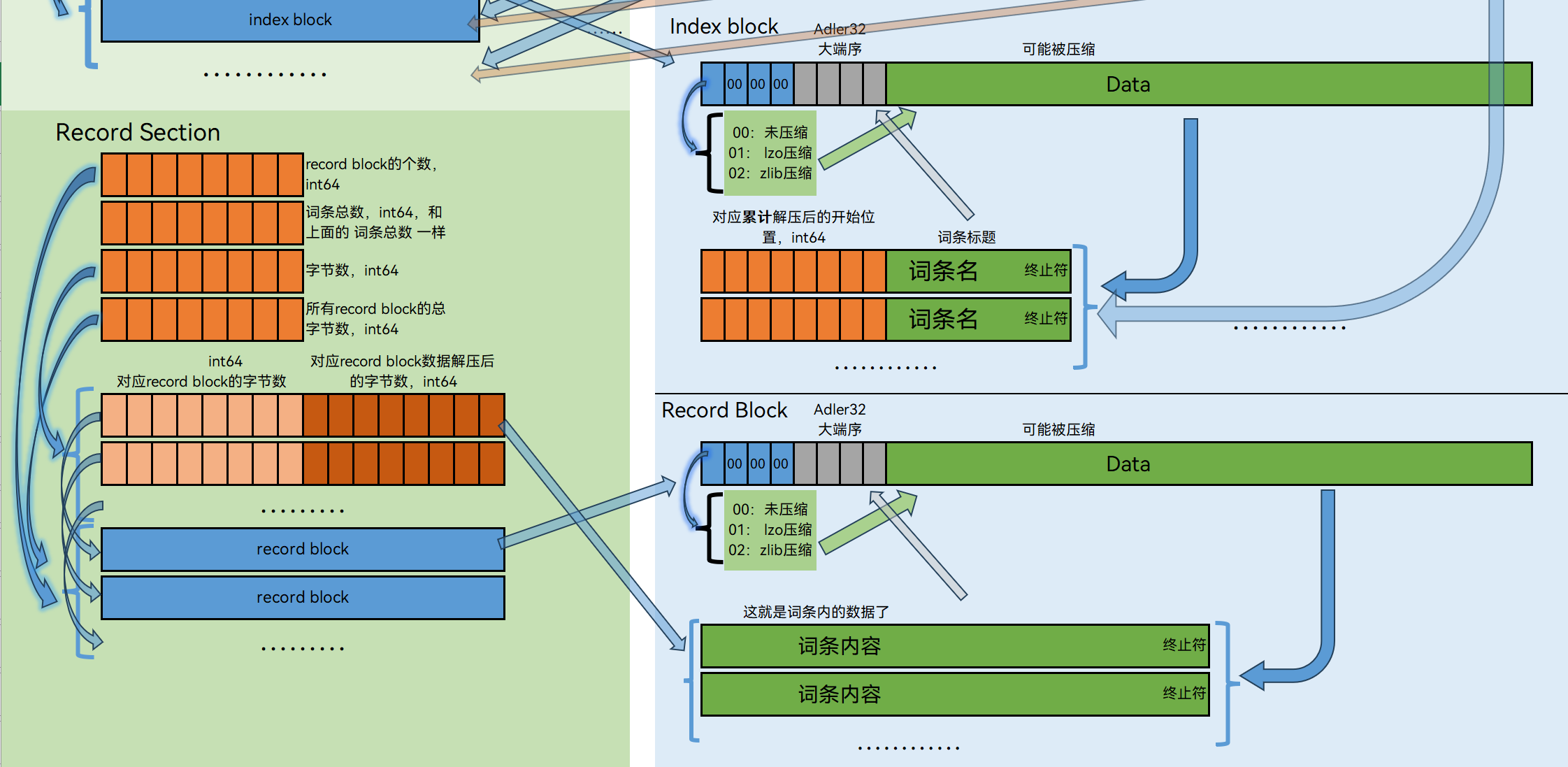
依靠这些已经可以读出Encrypted=2或0 的mdx 及 mdd 2.0
来源: File format specification — mdict4j 文档 GitHub - hehonghui/mdict-analysis