词表来源
离线保存 Oxford 3000/5000 官方网页,解析生成 oxford_uk_wordlist.tsv,包含词形、CEFR 等级,仅作为词汇范围与分级依据。
主词典来源(权威)
使用本地 OALD(oald.mdx),通过 mdict-utils 解包为 oald.db 及音频资源;数据库结构为
mdx(entry, paraphrase),其中 paraphrase 为完整 HTML(释义、词性、例句、音标、音频引用)。
补充词典来源(仅兜底)
使用 Longman 6(long6.mdx → long6.db),只在 OALD 缺失例句时补充,不覆盖定义、不影响主数据。
提取与筛选流程
仅处理 存在于 Oxford 5000 的词条,只保留 UK 发音与 UK 例句;每词生成 1 张卡片,选择最常用词性,中文释义按词性整理,最多保留 2 个核心义项。
例句策略(严格)
每词最多 2 条例句:
优先 OALD → 若缺失则使用 long6;
需通过质量过滤(短句优先、无怪符号、非标题体、必须有音频),否则放弃。
音频处理策略
复制 UK 单词音频与 UK 例句音频到 Anki collection.media;
保留原始字段,同时新增 ukWordAudio / exAudio1 / exAudio2 仅用于播放控制。
Anki 模板设计原则
- 正面:使用 Anki 原生
[sound:]自动播放一次单词音频 - 背面:全部 HTML5
<audio>手动播放(单词 + 例句),绝不自动播放 - 不使用 JS 模拟点击,确保 iOS / 桌面稳定兼容
标签与结构
仅保留必要标签:CEFR_A1–C2、no_example;
牌组结构为 Oxford 5000::A1 … C1,不引入功能性牌组与冗余标签。
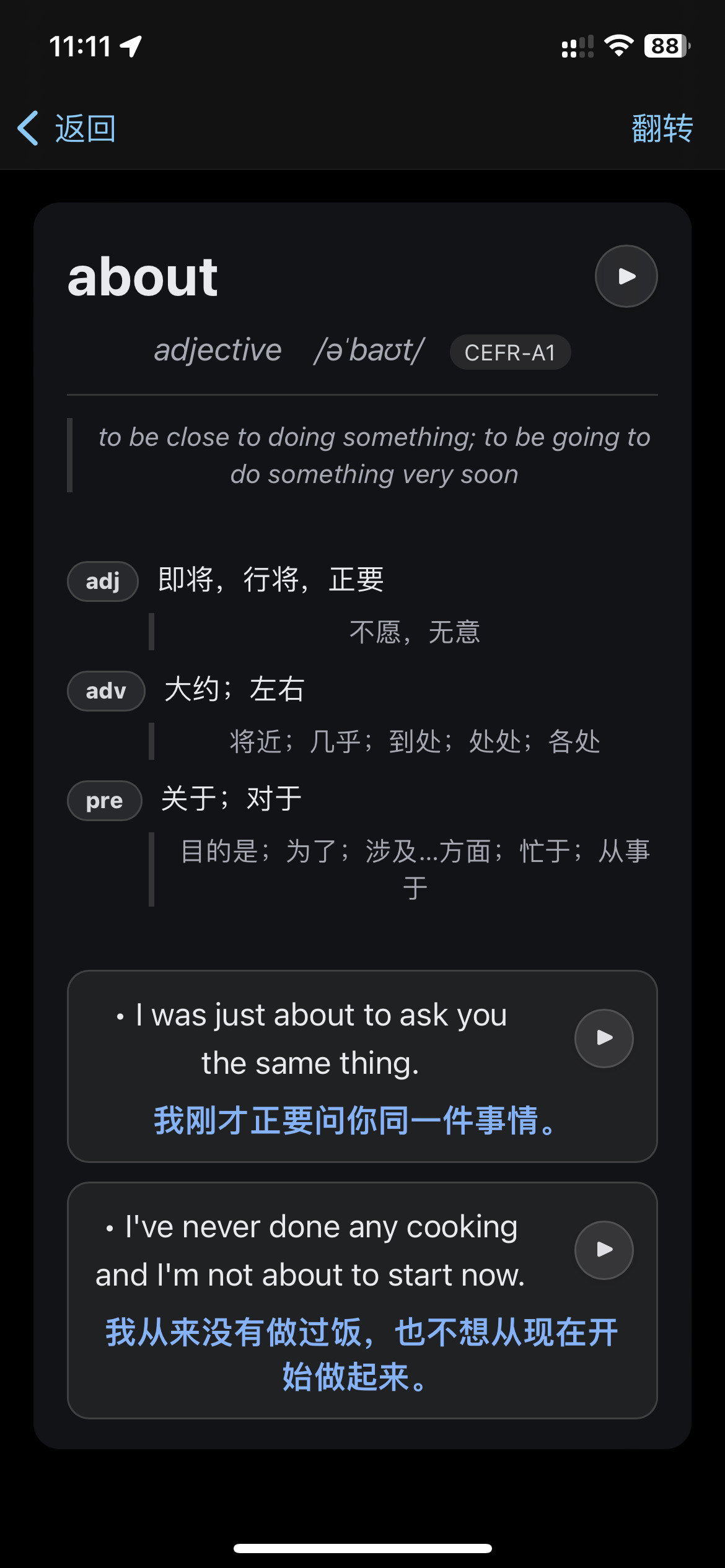

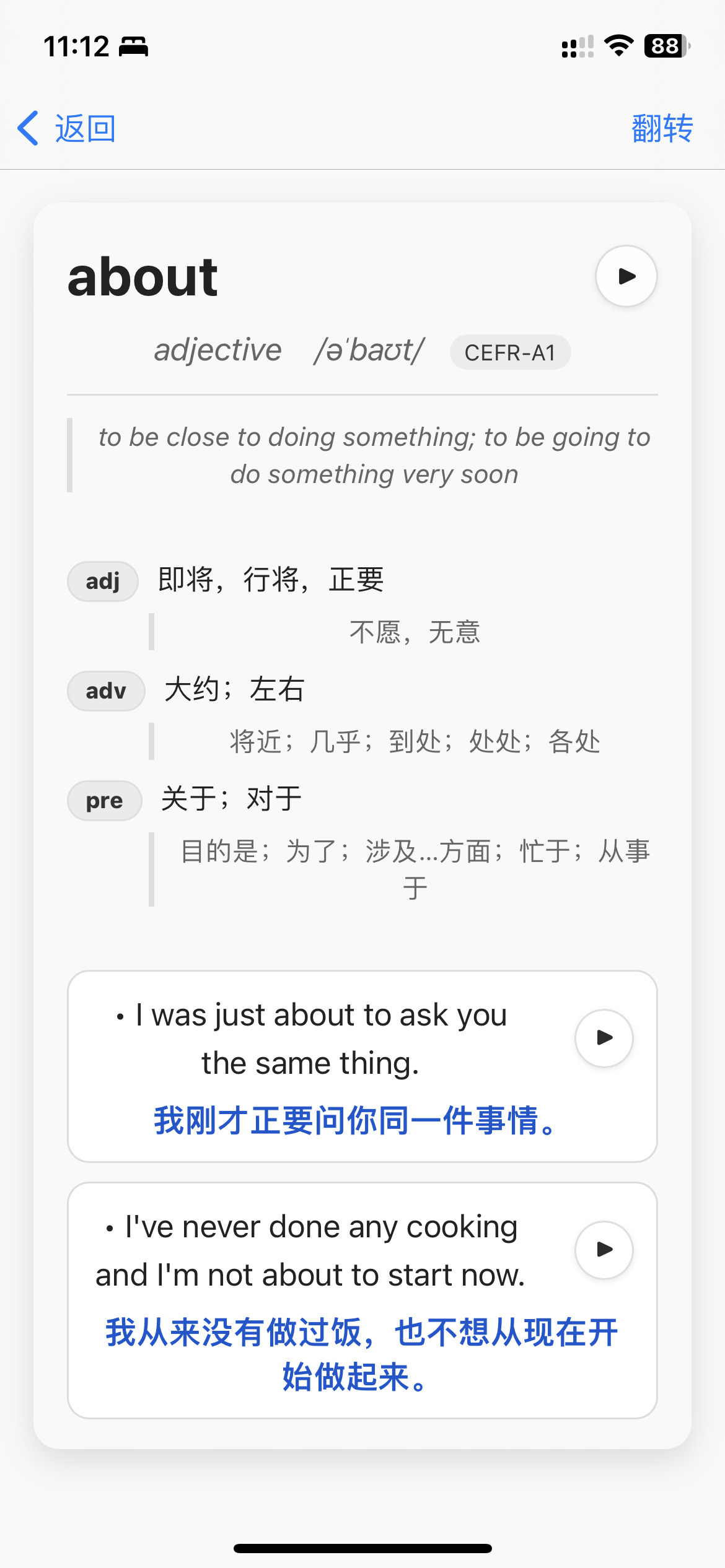
这周刚开始使用anki 之前并不了解 所以结合chatgpt 好帮手!!! 做出来的牌组 导出后分享一下 如果有哪些问题欢迎提出~
百度网盘 对我来说并不友好