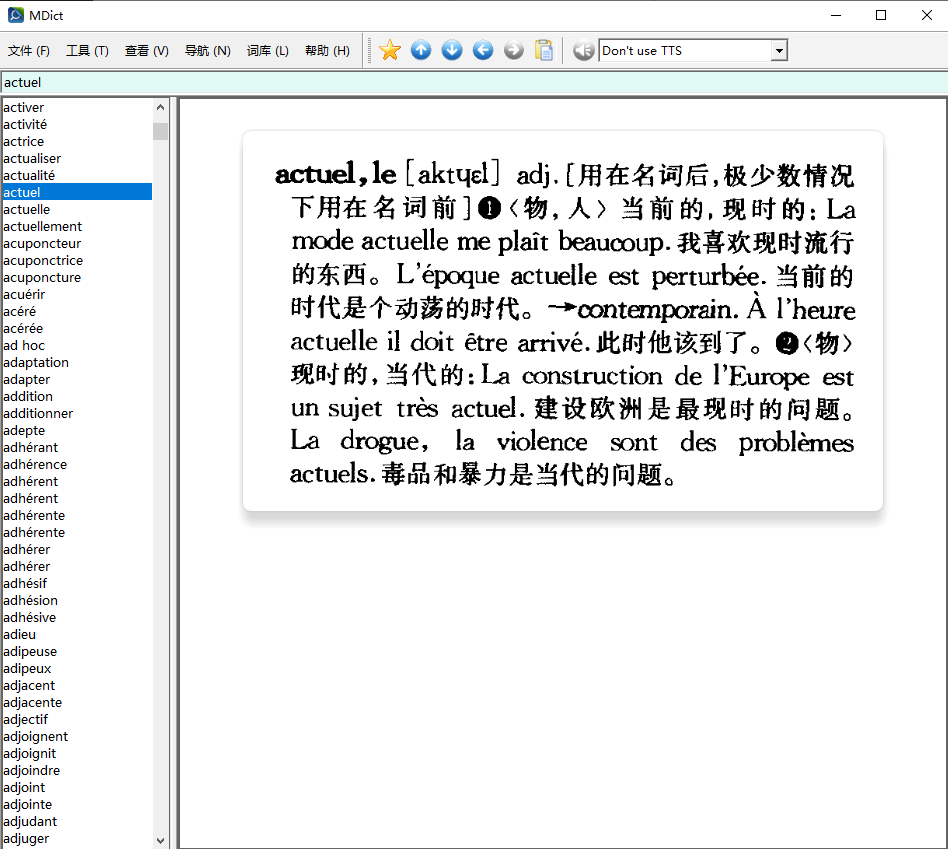
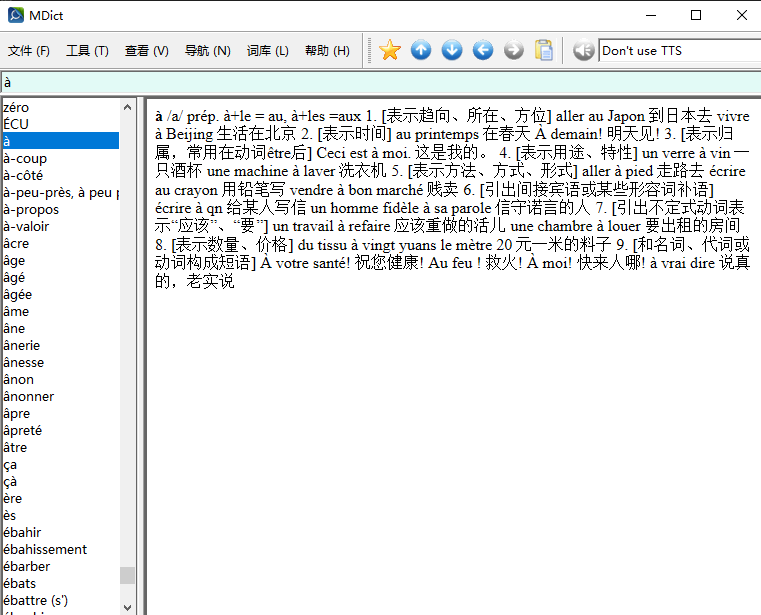
原始文件来自 Index of /尚未整理/集合/Other language Dictionaries/French/法语111/一些法语mdx词典/ ,好像是 @xliley 制作的,谢谢他付出的辛劳。
我稍微修改了mdx,添加了css文件,使图片的呈现或许更美观一些。mdd文件用原来的即可,没有改动。
——更新,词头索引已进一步提取,未全面检查,不担保无误。生成前txt源文件也传到这里,如有错误,可自行修改重新打包。
词头索引有点问题,没有进一步提取。@wynick27 可以用提取拉鲁斯词典词头的程序再处理一遍。
罗贝尔法汉词典(一词一图).mdx (257.3 KB)
robert.css (528 字节)
罗贝尔法汉词典(一词一图).txt (2.1 MB)
2 个赞
这个词的后缀表示方法不一致,要改程序才行,可能要单独指定规则处理。
罗贝尔法汉词典不如拉鲁斯重要,收词量少,特色是直接用中文释义,简明,例句多且完整。在不多的法汉词典里,也算佼佼者了。
因为图像底本算不上很清晰,文本化可能没必要也麻烦,不过在现成的切图版mdx基础上,倒是可以继续改造完善,跟拉鲁斯、新法汉等形成高中低搭配。
这个是不是也有法文版,我准备解决加标签格式化后接下来研究html去格式化和txt文本比较插入的问题,应该可以同时解决日汉和朗氏德语词典的问题。
它有法文版,文本pdf,Dictionnaire du Français - Josette Rey-Debove - Le Robert & Cle International。
朗氏德汉不容易插入处理,文本切得很碎,且德文并不完全一致,德文版把代字符“-”都给还原成原始单词了。
Dictionnaire du Français - Le Robert & Cle International这个文本pdf实际已经把词头给提取好了,需要设法从它里面抽取相关数据。
这个不难,fitz库可以查字体和颜色的,也可以直接输出xml。
我用 BeautifulSoup 处理文本pdf转换出来的html,试了各种方法,都是没名堂,因为转换成的html很随意,标签是乱加的,并没有严格的一致性。
索性换了办法,用 ai 处理,初步浏览,效果貌似不错。
罗贝尔词头 待处理.txt (46.1 KB)
罗贝尔词头 扩充.txt (77.5 KB)
1 个赞
词头索引已进一步提取,未全面检查,不担保无误。生成前txt源文件也传到主帖,如有错误,可自行修改重新打包。
pdf转换我来试试吧,pdf是zlib上4800多页那个吗
提取了法文版的文本,转成了json,没有做精细标签化,只给词头,序号和注释加了标签。不过要做也不难,法文版词头是完整的,可以直接用,转换下大小写就好了。
法语版词条数20980,比现在的图片少,不知道是哪边有错。
robert.zip (2.8 MB)
补一个夸克识别的中文版:
罗贝尔法汉词典_quark.docx (7.5 MB)
1 个赞
你是用fitz直接转的吗?我试了转html再提取词头不好用,就没试别的方案了。
pdf这种文件格式可谓不思进取,也落后于时代了,它只保证最终视觉呈现的正确和一致,并不维护原始的文本flow、layout和结构,把这些信息也存储下来,并不会增加多少数据量,却无疑会大大方便数据进一步的转换和利用。
是的,代码这么写的,用的dict模式:
import fitz
import os
import json
def process_page(page):
words = []
dict_text = page.get_text("dict")
for block in dict_text["blocks"]:
word = {'head':[], 'xml': '', 'type': 'text'}
if block["type"] == 0: # text block
for i,line in enumerate(block["lines"]):
for j,span in enumerate(line["spans"]):
if span['size'] > 20:
print('Large letter found:', span['text'])
word['type'] = 'letter'
elif span['color'] == 0xff:
if span['text'].endswith('.'):
word['xml'] += '<num>' + span['text'] + '</num>'
continue
elif span['text'] == '■':
pass
elif span['text'].strip() == '':
pass
else:
word['head'].append(span['text'])
word['type'] = 'word'
word['xml'] += '<word>' + span['text'] + '</word>'
continue
elif block['bbox'][0] >= 90:
word['xml'] += span['text']
word['type'] = 'rem'
continue
if j == 0 and word['xml'] != '':
word['xml'] += ' '
word['xml'] += span['text']
words.append(word)
return words
def export_pdf_pages_to_html(pdf_path, output_file, start_page):
doc = fitz.open(pdf_path)
words = []
for page_number in range(start_page - 1, len(doc)):
page = doc[page_number]
result = process_page(page)
for word in result:
if word['type'] == 'rem':
words[-1]['xml'] += '<rem>' + word['xml'] + '</rem>'
elif word['type'] == 'word':
words.append(word)
elif word['type'] == 'letter':
continue
else:
words[-1]['xml'] += word['xml']
del word['type']
with open(output_file, "w", encoding="utf-8") as f:
json.dump(words, f, ensure_ascii=False, indent=2)
print(f"已导出所有页面内容到 {output_file}")
# 使用方法
export_pdf_pages_to_html(
pdf_path="Dictionnaire du Français (Josette Rey-Debove) (Z-Library).pdf",
output_file="robert.json",
start_page=536
)
1 个赞
在这个帖子里发现了商务印书馆《法汉小词典》的xml数据:
法汉小词典xml.zip (1.3 MB)
不知道具体来源是什么,但文字质量好像比较高。我把它提取成了纯文本,且做了一个扩充过索引词头的mdx词典。
有xml数据,转制成加了标签的html文本也不难,可以用css美化一下形式,但这个工作就留待他人了。
法汉小词典 文本.txt (2.5 MB)
法汉小词典.mdx (1.2 MB)
法汉小词典_mdx_source.txt (3.0 MB)
1 个赞
补充一个gemini识别的版本:
罗贝尔法汉词典_gemini.txt (7.3 MB)
3 个赞