根据论坛分享的json数据,变成static html
离线图像比较大,104GB,52个rar,上传中
内容平平,比较晦涩。

下载
根据论坛分享的json数据,变成static html
离线图像比较大,104GB,52个rar,上传中
内容平平,比较晦涩。
下载
说文解字注呢,json应该有吧
好像漏了?有空修补一下
又是大工程!请问离线数据是图片吗?
此字典只有图像,巨量,无语音。
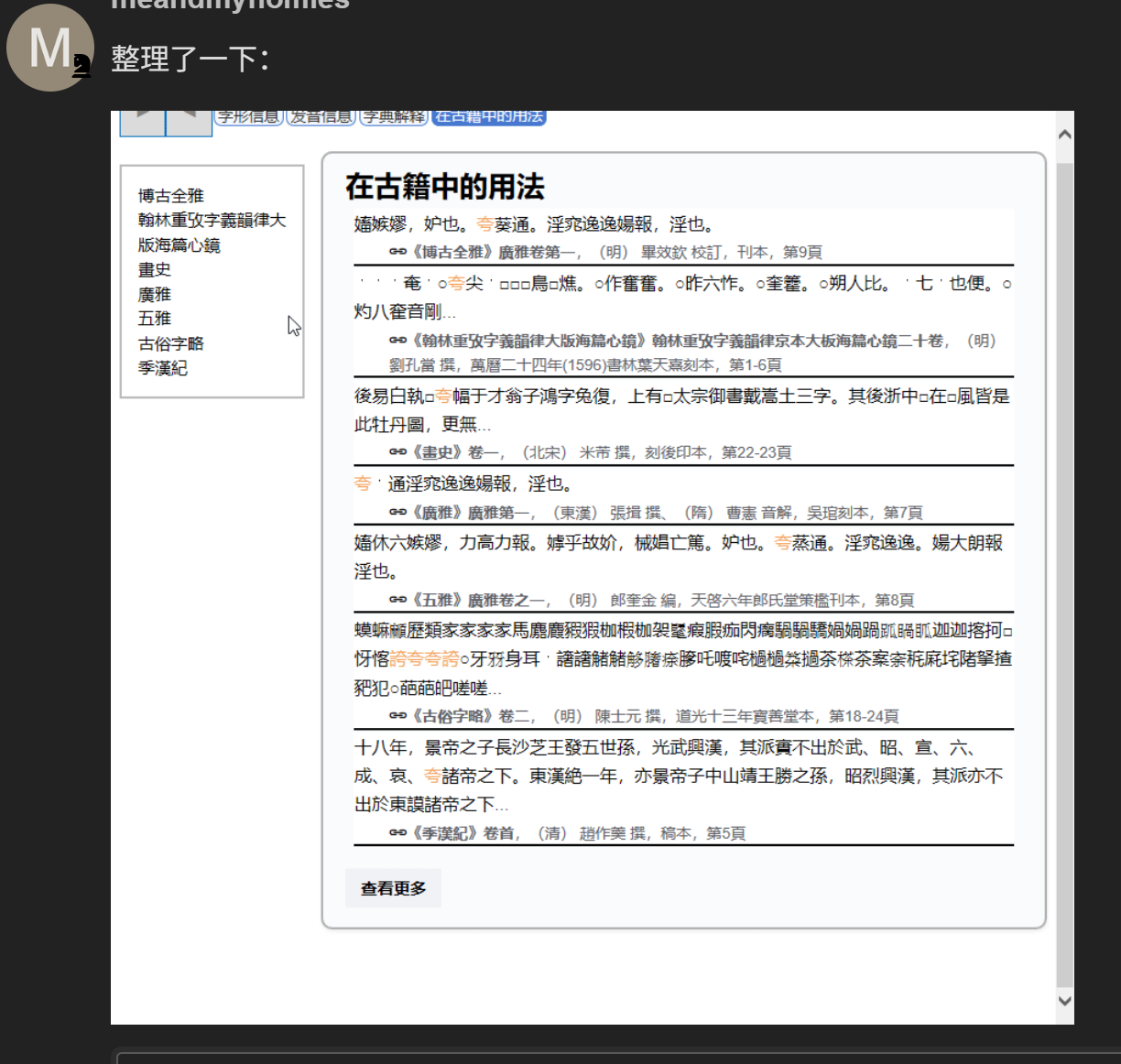
我下载的有《说文解字注》。此前的《识典古籍字典》的“在古籍中的用法”可以跳转到网页上,现在不能跳转,而且也不知道是什么古籍,这一项还有必要吗?另外,“相关古籍”那一栏不知有啥用处?好像只是介绍一些常用的古籍,这两项应该占了很大空间啊。这一版本显然还太粗糙。
书和用法分离了,我会合并。里面没有原文链接,毕竟数据不一样。这个字典就是里面有巨量字体图像,尽管是挤压在很少的一些用法和词条下。
这么大,我滴个乖乖,我还是只下mdx文件吧。图像就不用了。
【在古籍中的用法】和【相关古籍】其实放在mdx里意义不大,【在古籍中的用法】,原来的网站是让你知道这个词在哪本古籍中出现过,它会跳转到相应的古籍页面。这个目前做成mdx后没有跳转了,也没有出自哪本古籍(如果下载文档里有这个信息,那它就有用了。能知道引文出处。)
能整理出这么大的规模的词典也真是厉害了。 ![]()
刚刚发现自己没有仔细查看,原来,【在古籍中的用法】和【相关古籍】是有关联顺序的,相关古籍就是前者的出处,只不过因为排版或者其他原因无法直接衔接起来,以为是互不相干的。目前能确定前后是顺序关系,但不能和例句一一对应起来,不知道是排版问题,还是源数据就存在问题。
是数据处理问题,会出新mdx修复,不过不肯定是不是有链接,尽量保持完整。目前出处和例句割裂了。
所谓“在古籍中的用法”意义不大,我觉得还是此前发布的“《识典古籍字典》”好用,如果需要查古籍用法,直接引导跳转到识典古籍网页上也挺好。辞典做太大了没有必要,能在线查找最好。
我只是把数据原封不动的转换成mdx,离线,内容如何在于源数据,不是转换可以控制的
这个也是M大制作,好用!实际上,这个《字典》比新发的《古籍》,仅仅是《汉语大词典》前者为简编(无例句),后者为全编。而前者与《抖音汉语》正好匹配不重复,我建议可以将两种词典合并为一。但《字典》仅300多M,而《古籍》则增加了几乎1G,反而不能像《字典》这样跳转。我的意思是,恐怕《古籍》的原始数据就没有多大意义,不必费这个时间制作。当然,100G的图像文件没有下载,或者精华在图像吧,但100太吓人了,我是不会使用的。
貌似词头不是很完整,比如三监。如果没有抖音汉大的数据毛病,我是可以合并,就是把汉大那部分替换进去。体积庞大的主要是历史引用,图像除了25mb的字体,都是引用里面的。
这版是HTML内容。没仔细对比
能让它显示这个信息不?大佬
![]() ,对于核对引文出处很有用。
,对于核对引文出处很有用。
数据里面没有,如果你能找出url的固定规则,看看能不能加进去。