打算重新收集一次,从877一直到2570,
实际获得词典目录1525本,目录中的词条链接部分有纰漏,需要转换,实际获得词条122w条
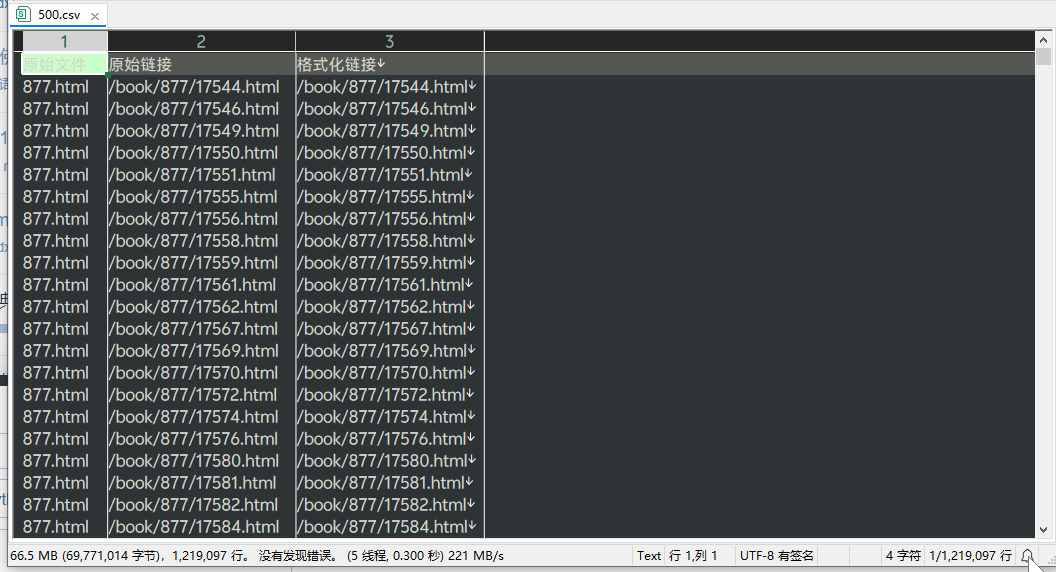
下载前10000条实际得到9979条,
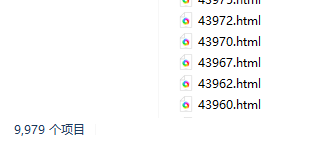

1w条大概需要1.3小时,
有没有大佬帮忙爬或者指点一下能加快进度的方法
排查了一下,佛爷的版本只是缺877到1178,满打满算也就缺92943条,之后的词典和词条我现在爬取只会比佛爷的更少,
保存路径直接照抄,应该不成问题了
pyhton的多线程 或多进程 或异步能提高爬取速度,供参考。我刚接触python,还不会用。
鸿篇巨制!老师辛苦了!
保存的目录也是个问题,我自定义了1w个页面一个目录,html目录和jpg目录
之前爬国学大师,9.8w个html放一个文件夹,jpg放jpg/zi或者jpg/ytzi
这122w个html放一个文件夹那不得炸膛了,或者1w个html洗版为一个txt,然后122个txt洗版成一个txt,jpg打包成mdd,因为保存html时jpg的地址做了修改,那不得打包成122个mdd
不好搞,没经验,没思路
···············
看了一下之前的版本,
网络图片地址ttp://202.106.125.14:8000/ApaDownLoadRef/m.20081027-m300-w001-258/images/Image5/m.20081027-m300-w001-258002206.jpg
本地图片地址img src=“/202.106.125.14_3A8000/ApaDownLoadRef/m.20081027-m300-w001-258/images/Image5/m.20081027-m300-w001-258002206.jpg”>
html保存本地文件夹地址估计也是类似,图片本地保存文件夹结构基本不变,利于洗版,到时候跨文件夹遍历html写成txt就行了
ps网页目录词条删除了好多,到时候还得交叉对比一下阿弥陀佛的版本
我会一些基本的数据处理,有什么能帮忙的吗?
感谢留意,这个辞典已出货 ![]()