
老兄这个问题我看不懂。
首先定义一下行、列?或者用电脑笔划一下范围?
行、列是什么意思?
1.直的叫行,横的叫列。
《现代汉语规范词典》
行列
人或物排列起来,直的叫行,横的叫列,统称行列。
《国语辞典》
行列
直的称行,横的称列。
《现代汉语常用词词典》
行列 hanglie
人或物排列的总称(直排叫行,横排叫列)。
2.横的叫“行”,直的叫“列”。
《古今词义辨析词典》
行列
人或物排列起来,横的叫“行”,直的叫“列”。《礼记·乐记》:“~得正焉。”引申为行伍,军队的行列。
3.行、列,这两个字的本意,是跟随着书籍的排版方式来定义的。
问:为什么台湾与大陆关于线性代数中「行」与「列」的定义截然不同?
线性代数中的column指纵向排列,在大陆称为「列」;row指横向排列,大陆称为「行」。但是在台湾的教材和资料中「列」指的是row,「行」指的是column。
答:在几乎所有领域,row在大陆叫行,在台湾叫列。column
在大陆叫列,在台湾叫行。所以涉台的时候不能用行列,只能用row、column,或者强调横行、竖列。
答:行、列,这两个字的本意,是跟随着书籍的排版方式来定义的。直排时,纵向为行,横向为列。横排时,横向为行,纵向为列。在这些成语、诗词、俗语中,“行”指的都是纵向,因为在成文时,默认就是直排,横排还未传入我国。(知乎)
https://www.zhihu.com/question/32199138
1 个赞
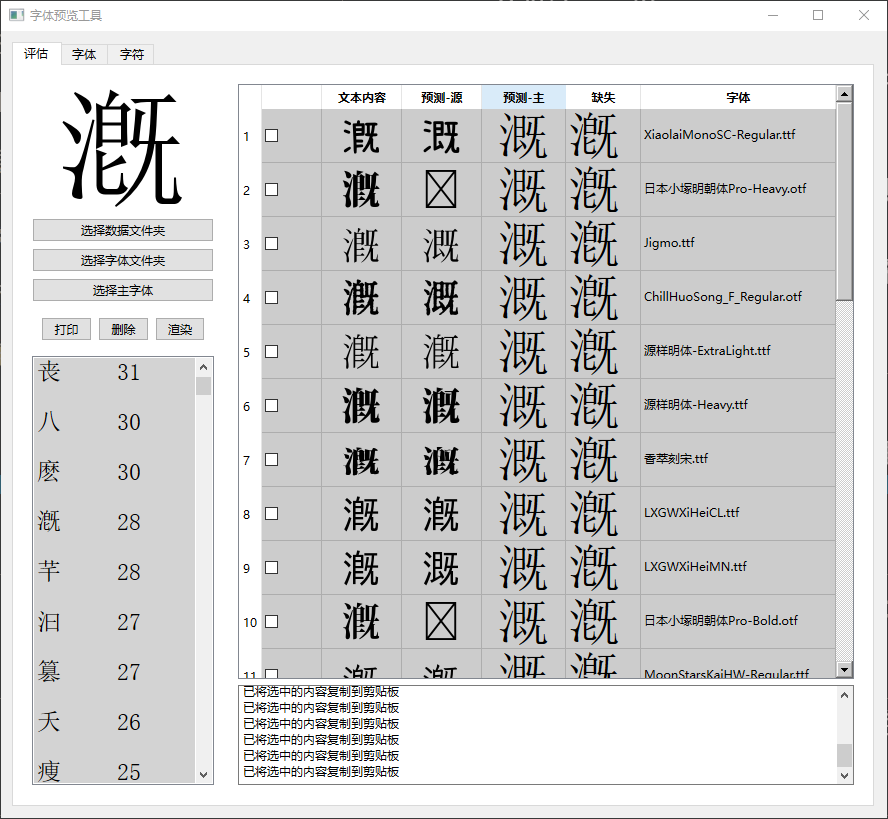
前两列是两种编码 漑溉 (异体字关系,第一列是漑,第二列是溉)在不同字体的字形,后面两列是给你列出了unicode规定的大陆标准字形(第三列是溉,第四列是漑)。
这个人做这个图表是为了让你比较不同字体的字形区别,是否符合大陆标准。不过说实话,顺序有点乱,也没做好说明,让人看不懂。
1 个赞
前三种看名字都知道,是旧字形字体,有意地完全采用了传承字形的部件(中间的那个部件是主要区别),也因此不会符合unicode规定的字形标准。传承字形的选择完全是由民间的自行讨论得到的,不过有一点明体的作者专门制订了一个文档规范。
不过溉字的右侧部件是用的现代部件,这方面预留了多种选择,是出于什么考量我就不懂了。个人只觉得这样造字不伦不类。
霞鹜晰黑的CL版是传承字形版,这个作者的做法是将溉字的字形直接变为了漑,和前面两种字体的做法不一样。
霞鹜晰黑的MN版是兼采现代部件为求简化的版本,所以保留了这两个字的区别。这个版本的部件选择是不太明确的。
我综合评价一下,部件的选取原则完全是按作者的喜好来的,为了追求部件准确性和不混乱,这些字体都不太推荐日常使用。
用霞鹜新晰黑还靠谱一点,严格采用国标字形。
能劳烦楼主标下出处吗?是在哪里看到的这个图?
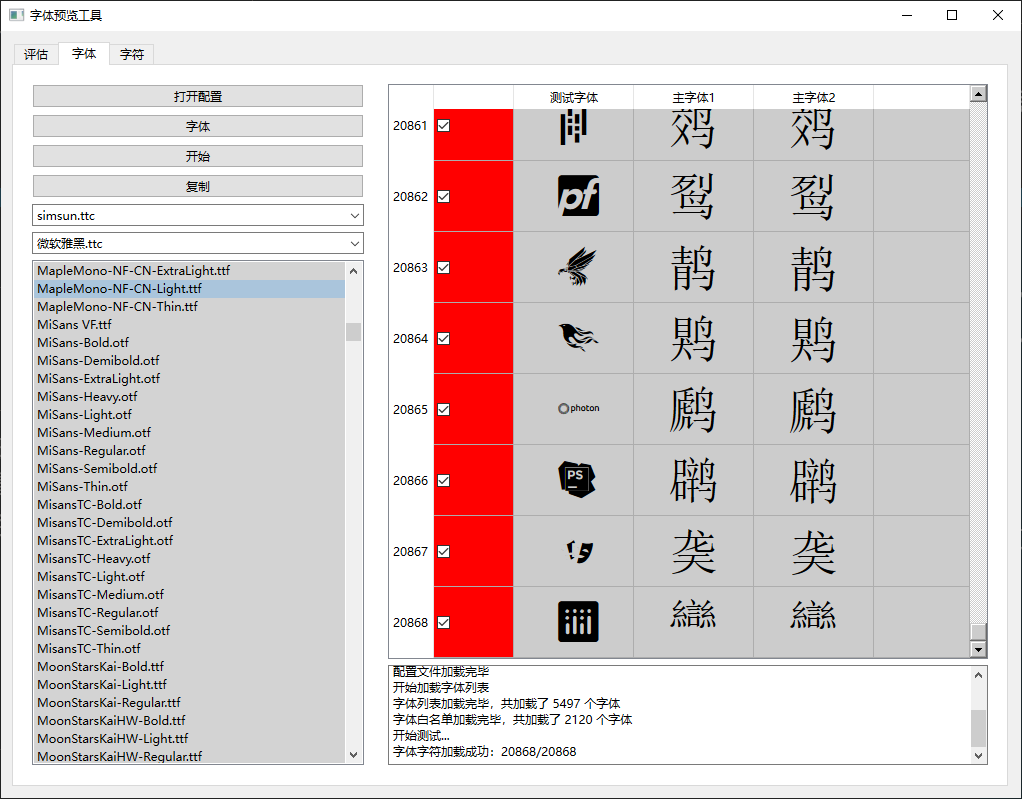
自己用 Python Pyside6 写的小工具截图。过年闲着无聊用网上找的字体合成训练数据,训练中文OCR模型玩,再用训练出的模型输出识别错误的文字,最后在开发的工具批量将这些文字可视化出来。
以下是工具完整截图,界面大概说明:
选择主字体是指选择一个作为参考的目标字体,左上角的大号字是当前选择的识别错误文字在参考字体的字形,左下列表是识别错误的文字列表。
第一列文本内容:当前选择的错误文字在第五列那个字体中的字形
第二列预测-源:当前选择的错误文字被模型识别出的文字在第五列那个字体中的字形
第三列预-主:当前选择的错误文字被模型识别出的文字在参考字体中的字形
第四缺失:用于训练的那张图片中有哪些文字识别错误,以参考字体字形显示
第五列字体:用于合成训练图片的字体名
找这些民间字体,真不如找些常用字体,原因我也说了。
自己写的程序还要问?你自己不都知道是什么字了?第一列正确的字就是这个啊。不知道是不是我理解有误,第一列是什么字要自己认吗?
常用 的,不常用 的,找了大概两千多个字体。因为字体多了,同一个字,在不同的字体中什么形态的都有,有对的,也有错的。上面截图只是一部分,像那个样子的文字有三个字跟它形态一样,正好那个字我不认识。
呃,感觉第二个问题你答非所问。你是已经有预设的文字了,第四列就是预设文字的字形,直接复制这个unicode码不就行了,不需要自己认啊。和你不认识有什么关系呢。
你写程序的时候是不是自己都云里雾里的?
我设计软件会这么排序
unicode编码 | 标准参考字体字形 | 选中的测试字体字形 | ocr结果对应的标准参考字形 | ocr结果对应的测试字体字形|

对嘛,那为什么会来提问“求第一列是什么字”,你不都知道是什么字吗?你没输入这个字,程序怎么给你呈现不同字体字形。
我大概明白你程序的作用了,你是要找这些字体错误的字形,你要修正字体?
如果你是要训练ocr引擎的话,哪里有简体字体和繁体字体多种标准字形混合训练的,这样效果会好吗?我表示质疑。
1 个赞
人可以用眼睛认识这些字,机器视觉模型也可以,效果就看参与训练的数据质量。
那参与训练的数据质量太低了吧,我肯定只会去用出版物和正经字厂的字体。
当前网上公开的OCR模型都是简体字与繁体字分开训练的,如果一张图像中同时有简体字与繁体字,就没有一个模型可以把这些字全部正确的识别出来。
你要相信前人的智慧,不是你特别聪明。这样的模型你以为是两边都能,其实是两边都差。
训练这个模型只是找乐子好玩,目的是尽可能的提高识别正确率,不自己撞南墙怎么知道头疼?