词汇是外语学习的一个非常重要的环节,但要设定好学习预期却并非易事。英语中大约有 5 万个单词[1],这是一个难以达成的上界——即使日耕不辍地每天学习 10 个单词,完整过完一遍也至少需要 13.7 年的时间。大多数母语人士的词汇量在 2 万左右,这是一个相对更加实际的安全上界。能够如此大幅缩减的一个重要原因是每个单词的重要性是不同的,比如仅单个单词 the 便覆盖了任意英文文本的 7%;前 1000 个最高频的词汇能够覆盖大多数英文文本的 80%;一个 10 万字的英文小说大约包含 5000 个单词,然而其中一半的单词只会出现一次。也就是说大多数单词都是非常低频的,少数高频单词占据了英文的绝大部分,Zipf 经验定律就是对这一现象的数学化表达。
更进一步地,词汇相关的学术研究根据词频将单词进一步划分为高频、中频、低频这三类。高频单词的量级一般为 3000 个,比如经典的牛津 3000 词,久负盛名的牛津高阶词典便是仅使用这 3000 个核心单词给出每个单词的英文释义。中频单词一般在 4000-9000 这个范围,10,000 往上则属于低频。以单词表「The BNC-COCA Lists」为例,高频单词加上专有名词,能够覆盖 95% 的英文文本(其中专有名词大约占 2%);再加上中频单词,便能够覆盖 98%,这意味着每 50 个单词里约有一个低频单词,即使不认识在大多数情况下也不影响继续阅读。高频、中频往往是一些通用词汇,从低频开始,会出现一些技术单词、日常使用中难以碰到的词。中频和低频的的界限也是母语人士词汇的一个分水岭,在这个阶段,由于每个人的兴趣、专业领域不同,积累的词汇种类也开始出现分叉,对一个人非常高频的技术词汇可能是另一个人的低频单词。这些研究带给我们的启发是:
1/ 将精力优先投入在更重要的词汇上具有非常高的投入产出比;
2/ 高频、中频适合刻意学习,而低频单词则更适合在大量的阅读与听力中潜移默化地习得。
刻意学习的方式比如找到一个包含词频分类信息的单词表,按照高频、中频的顺序依次学习每个单词。对于偏爱沉浸式方法的学习者,则可以在遇到生词时查询该单词的词频分类信息,若属于高频、中频,便加入记忆卡片进行重点学习与记忆。「The BNC-COCA Lists」这个包含词频分类、按照实用程度循序渐进、由语言研究学者精心设计的单词表就是一个绝佳的辅助工具。它是一个包含 30 组单词列表的集合,其中每组包含 1000 个单词。这里单词的单位使用的是词族 (word family),即由一个单词的基本形式及其各种词形变化所组成的集合,比如 take (基本形式), took、taken (过去式、过去分词)、takes (第三人称单数)、retake (前缀) 这些单词都同属于 take 这个词族。其中第一组的 1000 个单词 (记为 1k) 和第二组 1000 个单词 (记为 2k,后同),使用了一个特殊设计的、包含 1000 万个词元的语料构建。其中 600 万语料来自英式与美式英语的口语表达,包括电影、电视等,剩余 400 万为书面表达,包括面向儿童的文字、小说等。另外,数字、星期被直接放进了 1k 组、月份被放入到了 2k 组,尽管从词频上不一定如此。生存词汇 (在国外旅游或短暂生活一段时间所需的必备词汇,如打招呼、购物、问路等) 也被硬性地包含在了前 2k 中。3k 及以上的组则根据 COCA (当代美国英语语料库) 和 BNC (英国国家语料库) 的词频构建,并排除掉已经出现在前 2k 的单词。
「The BNC-COCA Lists」可以从该词表的构建者 Paul Nation 的网站上免费获取。使用 WordFamilyFinder 可以快速地查询一个单词属于 30 组中的哪一组,并且它还额外提供了该词族的每个成员在 BNC 中的词频信息,从而能够对该单词的每种词形变化的出现频率有个大体的了解。但网页查询这种形式使用起来还是不如本地字典快速便捷,这里提供一个基于 WordFamilyFinder 所提供的数据制作的一个可以在本地使用的词典,包括可用于 MDict、欧陆词典等的 .mdx 格式以及可用于 macOS 内置字典应用的 .dictionary 格式。词典的下载、制作代码可参阅该项目的 GitHub 页面。
.mdx:mdict.zip (1.3 MB).dictionary: appledict.zip (8.0 MB)
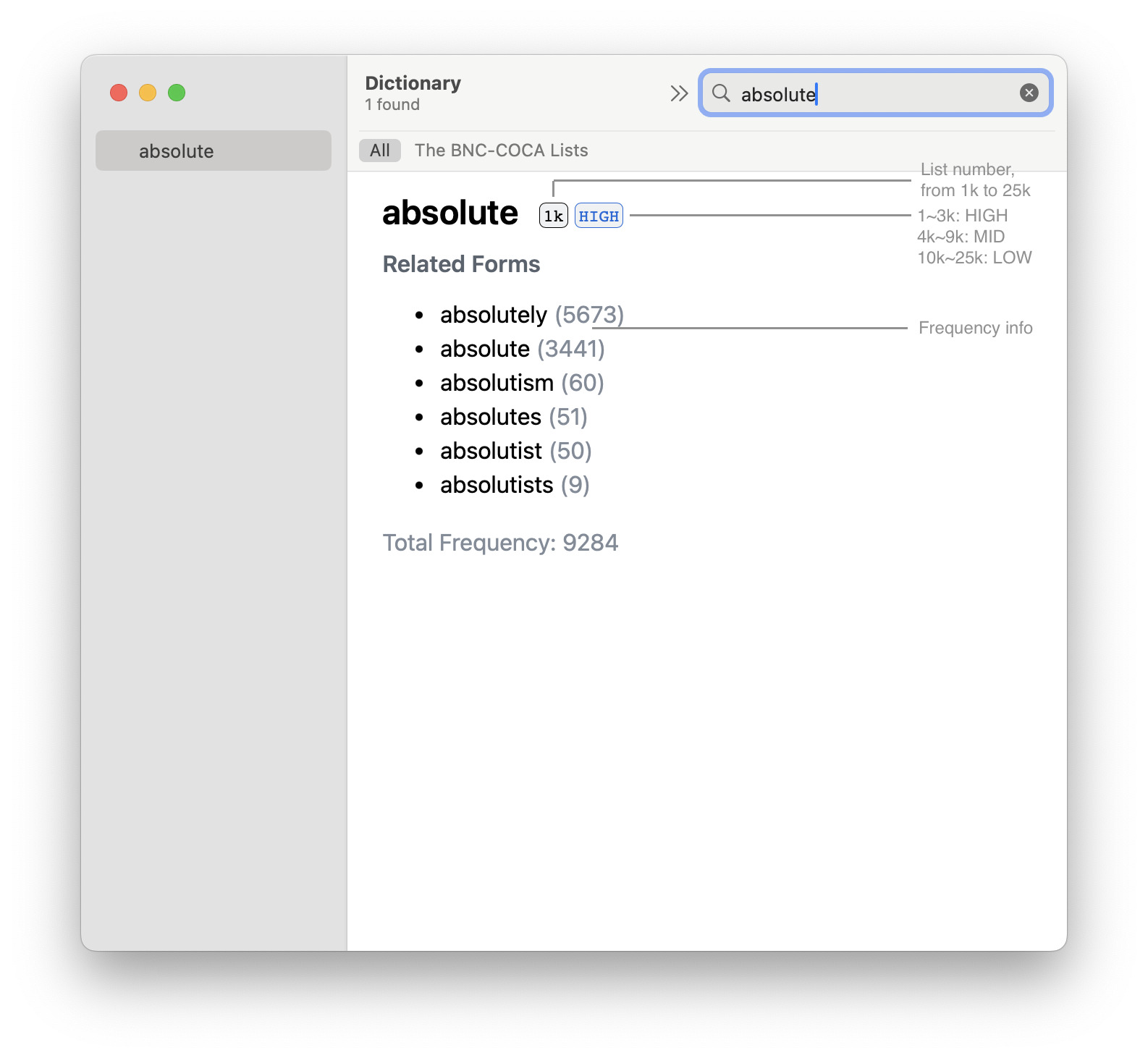
此外,还提供一个仅包含前 9k 的 .csv 格式的数据以方便对高、中频单词进行刻意学习:
- csv.zip (271.2 KB)
其他补充信息:
- 文中使用的统计数据主要出自 Making and Using Word Lists for Language Learning and Teaching (Nation, 2016) 与 Learning Vocabulary in Another Language (3rd Ed., Nation, 2022)。
- 「The BNC-COCA Lists」是一个不断在完善中的词表,它的目标是提供 30 组单词列表,但目前还没有完全构建完毕。作者 Paul Nation 在网站上提供的是 25 组的版本,WordFamilyFinder 则增加了第 26-30 组的部分,虽然依然尚不完整 (每组不足 1000),但由于这部分是低频单词,所以在使用上的影响微乎其微。
- 「The BNC-COCA Lists」的词族判定基于词族分类的 Level-6,时态、人称、常用的前后缀这些词形变换都被囊括在内,因此这个词表也是目前最大的词族列表。
- 「The BNC-COCA Lists」还包含了 5 个额外的列表:(1) 专有名词;(2) 边缘词汇如 uh, um, meow;(3) 透明复合词如 notebook;(4) 缩写;(5) 外来词汇。这几类词本身易于识别,因此没有被放入上述提到的本地词典中。
单词的统计本身是一个复杂的命题,不同的统计单元、面向不同的用途都会得到不同的结果。此处的 5 万来自对词典「Webster’s Third New International Dictionary」的统计,这本拥有超过 45 万个条目的词典,包含 5.4 万个词族 (不包含复合词、专有名词、一些地方方言等) Goulden,
Nation, & Read, 1990。这是一个相对有些过时的研究,毕竟语言本身的发展是动态的,但这里不再深究,因为 5 万已经是一个难以达成的上界。 ↩︎