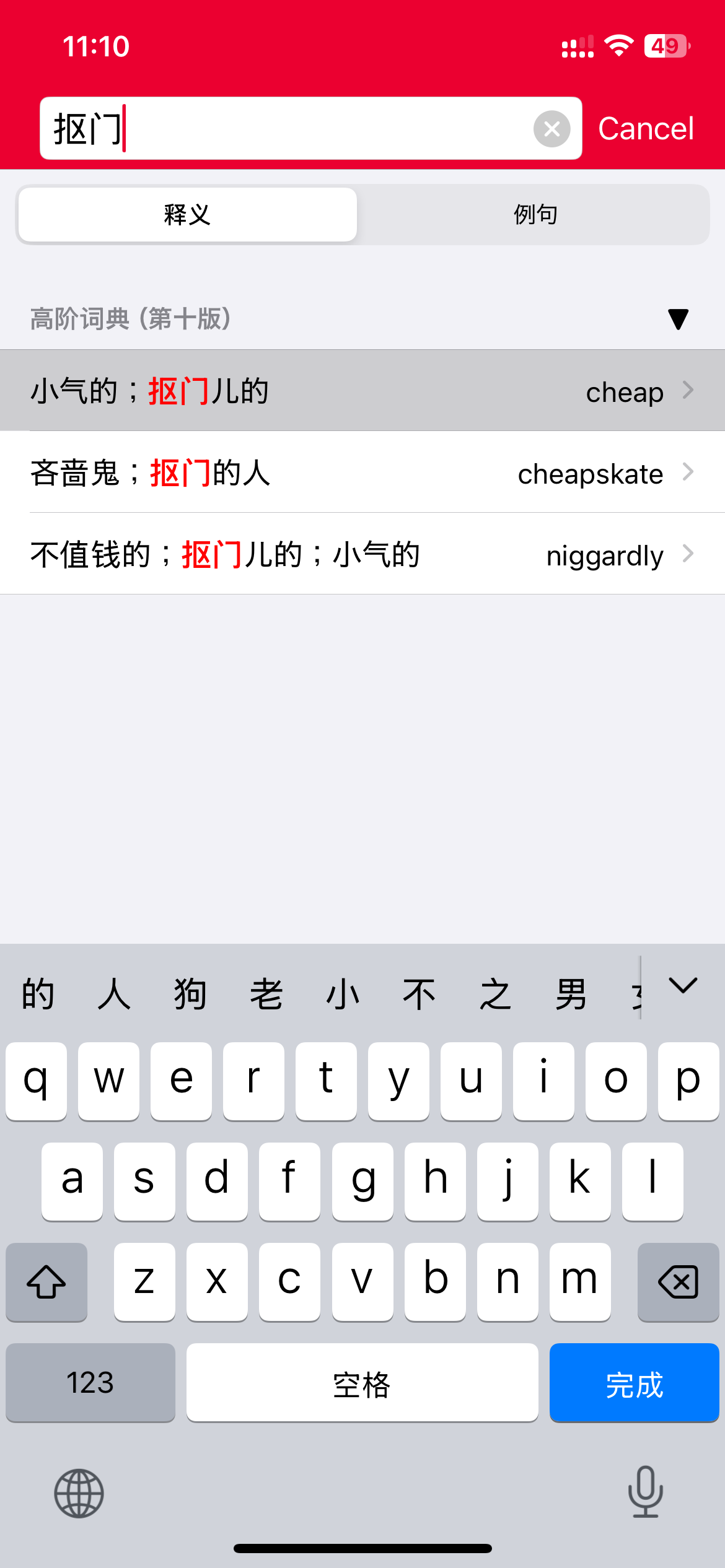
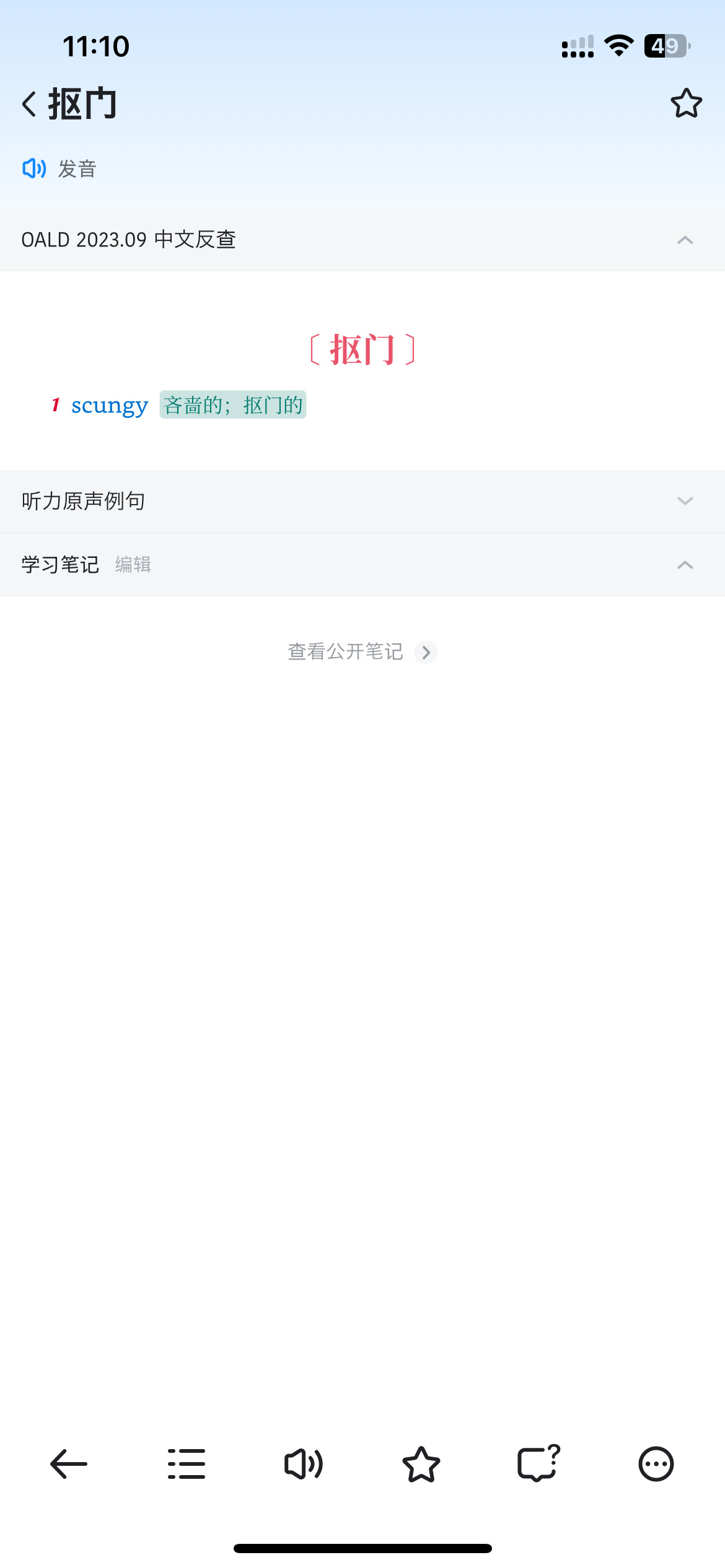
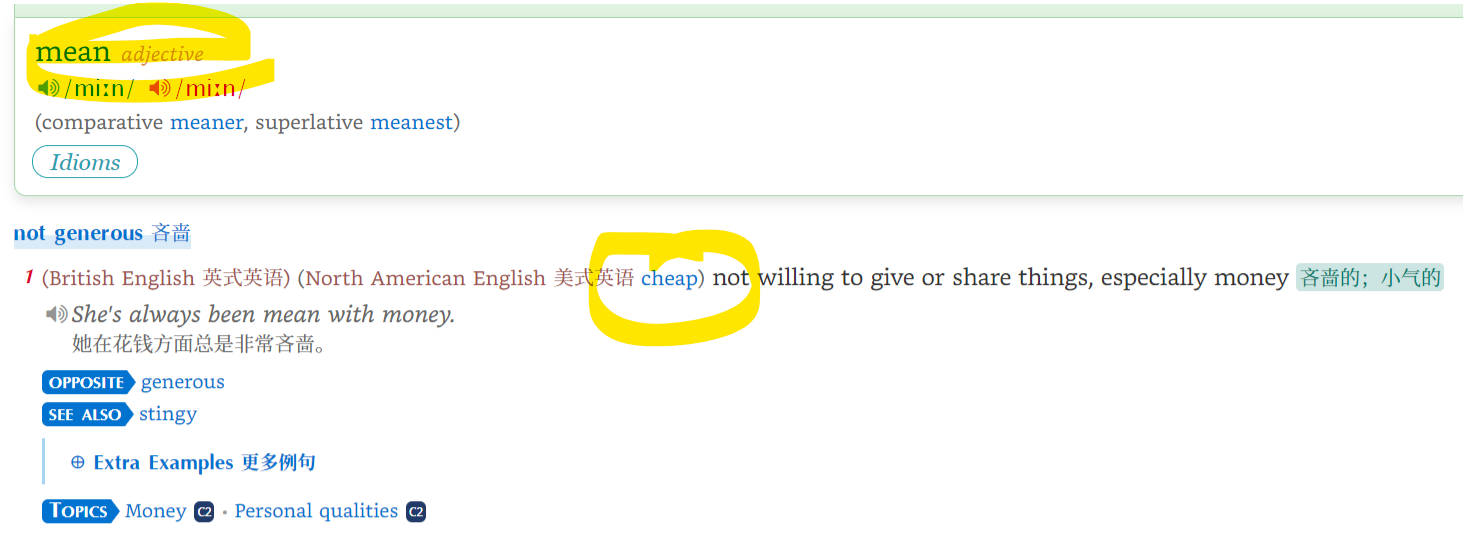
看起来更像是数据不一致。(没用 10,猜测的。
你查 “抠门儿” 就有了,反查没那么智能
1 个赞
这样讲就不是数据问题了,是反查的分词没做好。
如果用的jieba分词,应该是用的精确模式,我做分词一直都用全模式。
sentence = "我来自中国人民大学"
# 默认精确模式
words = jieba.cut(sentence)
print("精确模式: %s" % " ".join(words))
# 全模式
words = jieba.cut(sentence, cut_all=True)
print("全模式: %s" % " ".join(words))
# 新词模式
words = jieba.cut(sentence, use_paddle=True)
print("paddle模式: %s" % " ".join(words))
# 搜索模式
words = jieba.cut_for_search(sentence)
print("搜索模式: %s" % " ".join(words))
精确模式: 我 来自 中国人民大学
全模式: 我 来自 中国 中国人民大学 国人 人民 人民大学 大学
paddle模式: 我 来自 中国人民大学
搜索模式: 我 来自 中国 国人 人民 大学 中国人民大学
>>> import jieba
>>> seg_list = jieba.cut_for_search("小气的;抠门儿的")
>>> print(", ".join(seg_list))
Building prefix dict from the default dictionary ...
Loading model from cache
Loading model cost 0.564 seconds.
Prefix dict has been built successfully.
小气, 的, ;, 抠门, 门儿, 抠门儿, 的
1 个赞
jieba 的分词也有点问题,一直困扰着各国老外。
比如尝试分词: 「小化妆包」,全模式或者搜索模式分词后都搜索不到「包」字。(发现启用 Paddle 模式也不可以。
的确有问题,第一次做,全靠个人理解和摸索。
释义用的自定义规则,没用分词,要完全匹配才行
例句用的精确分词
2 个赞
我折腾的那个macos端的新app也有这样的问题,后面我干脆用一元分词了(就是每个字都分开),几乎等于没有分词。
1 个赞
@okayer 做过好几本反查
没用过,不知道分词器用的是什么,只要是结巴分词或多或少都会有类似问题。