txt使用mdxbuilder3.0转化为mdx文件时,中间丢失了一大段词条(而且是对应的两三百页都丢失了),但将该mdx转化为txt后检索相应的词条却又能找到相应的“字头”。不知道如何解决。求助大佬帮忙看看!
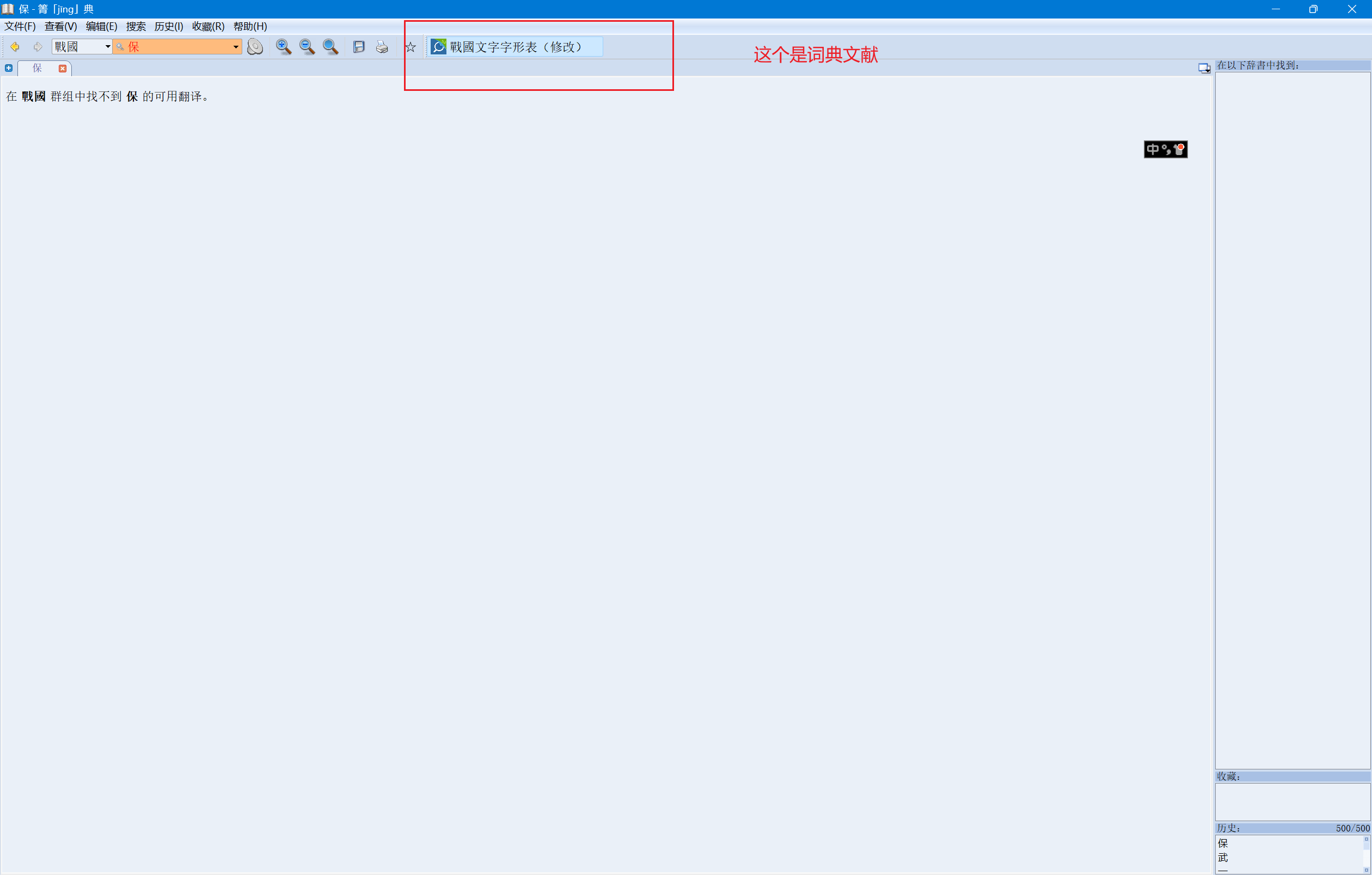
上图是goldendict运行查找相应词条时的结果(PS:mdict运行也是一样,找不到相应的词条)
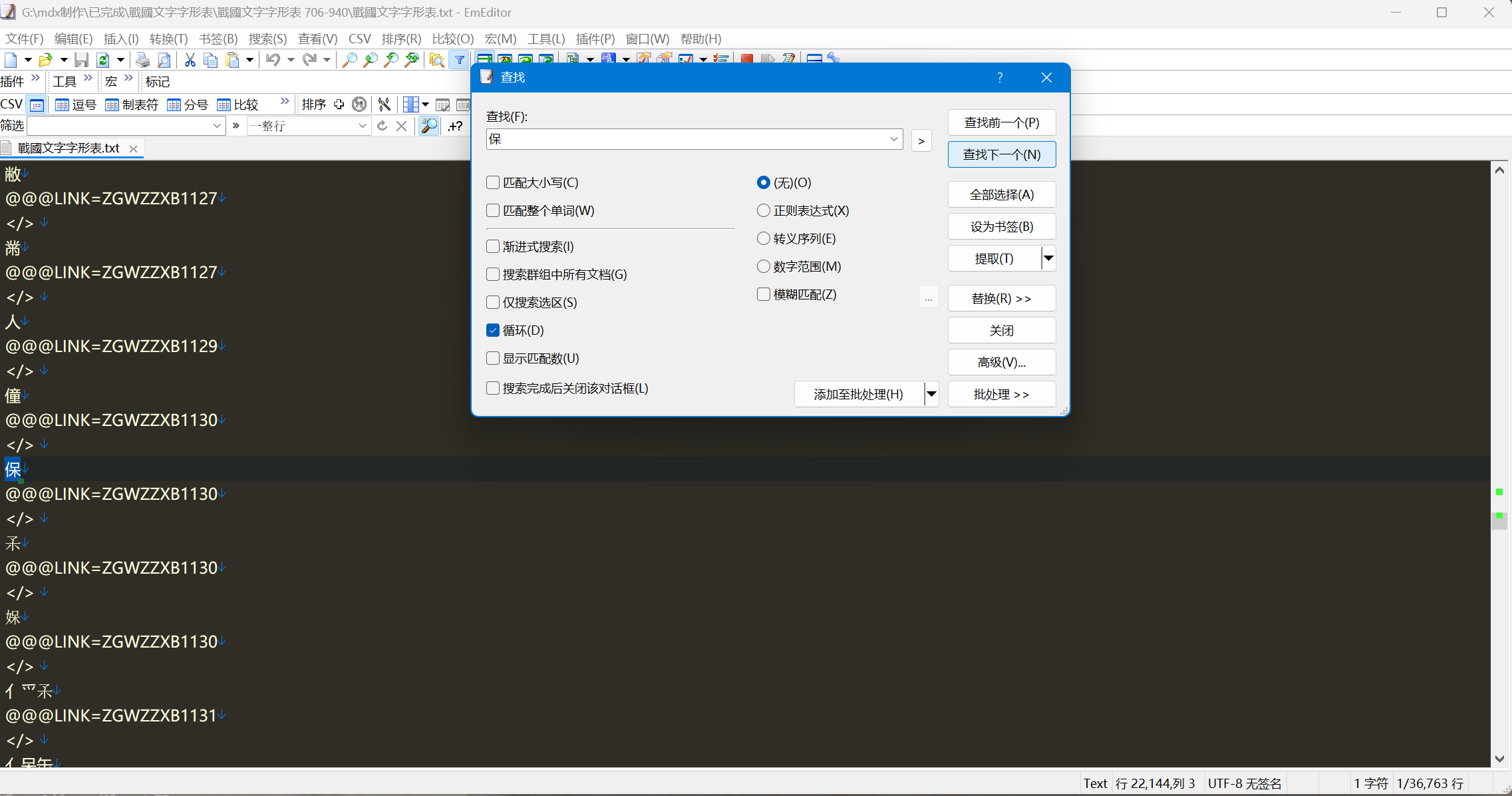
查找txt中相应的词条又能找到这一条。不知道如何解决。
此文件共有上万条词条,对应的mdd文件有2000多页
txt使用mdxbuilder3.0转化为mdx文件时,中间丢失了一大段词条(而且是对应的两三百页都丢失了),但将该mdx转化为txt后检索相应的词条却又能找到相应的“字头”。不知道如何解决。求助大佬帮忙看看!
换行符\n,换成\r\n ,试试看
程序代码这块,机器啥时候都是死的,潜台词,对格式的要求也肯定特别严格,严格到死板的地步。一句话,工具类程序,当初代码写的是能处理啥格式,你的数据文件对应就得提供啥格式。你仔细检查,出问题的地方,和其他,正常显示的地方,格式上有啥不一样。或者,把原始数据上传过来,让论坛里的愿意管闲事儿的看一眼。生成工具这块,应该问题不大,或者说,不至于,最大的问题,还是你的原始数据。
戰國文字字形表.txt (683.7 KB)
txt源文件在这 麻烦大佬们看看啥情况QAQ
“</>”后面不要有空格,空行
一千多条吧
从
暘
@@@LINK=ZGWZZXB0941
到
亻𠂤目
@@@LINK=ZGWZZXB1176
</>
这一段全无了
!!!我才发现有空格!!太感谢了!!我这就去试试
解决了!!非常感谢