使用mdict-utils的Python项目打包的MDX词典,求兼容性测评
mdict-utils的版本我升级到了24.2
python -m pip install --upgrade pip==24.2
TXT转MDX的py脚本.zip (2.8 MB)
PY 批量打包脚本:
import subprocess
import os
# 定义输入和输出目录
input_dir = r'E:\02\01'
output_dir = r'E:\02\01MDX'
# 确保输出目录存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 定义标题和描述文件路径
title_file_path = r'E:\01\title.html'
description_file_path = r'E:\01\description.html'
# 构建命令
def convert_to_mdx(txt_file_path, mdx_file_path):
command = [
'mdict',
'--title', title_file_path,
'--description', description_file_path,
'-a', txt_file_path,
mdx_file_path
]
# 执行命令
subprocess.run(command, check=True)
print(f"Dictionary saved as {mdx_file_path}")
# 遍历输入目录中的所有TXT文件
for filename in os.listdir(input_dir):
if filename.endswith(".txt"):
# 构建完整的文件路径
txt_file_path = os.path.join(input_dir, filename)
# 构建输出的MDX文件路径
mdx_filename = os.path.splitext(filename)[0] + '.mdx'
mdx_file_path = os.path.join(output_dir, mdx_filename)
# 转换为MDX
convert_to_mdx(txt_file_path, mdx_file_path)
批量打包MDD
import subprocess
import os
# 定义输入和输出目录
input_dir = r'E:\01\03'
output_dir = r'E:\01\03MDD'
# 确保输出目录存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 定义标题和描述文件路径
title_file_path = r'E:\01\title.html'
description_file_path = r'E:\01\description.html'
# 创建标题和描述的HTML文件
with open(title_file_path, 'w', encoding='utf-8') as title_file:
title_file.write('<title>Data Files</title>')
with open(description_file_path, 'w', encoding='utf-8') as description_file:
description_file.write('<p>Data files packed into MDD format</p>')
# 构建命令并执行
def pack_to_mdd(source_dir, output_mdd_path):
command = [
'mdict',
'--title', title_file_path,
'--description', description_file_path,
'-a', source_dir,
output_mdd_path
]
# 执行命令
subprocess.run(command, check=True)
print(f"Data files have been packed into MDD file: {output_mdd_path}")
# 遍历输入目录中的所有子目录
for subdir in next(os.walk(input_dir))[1]:
# 构建完整的源目录路径
subdir_path = os.path.join(input_dir, subdir)
# 构建输出的MDD文件路径
mdd_filename = os.path.splitext(subdir)[0] + '.mdd'
mdd_file_path = os.path.join(output_dir, mdd_filename)
# 打包成MDD
pack_to_mdd(subdir_path, mdd_file_path)
# 清理创建的标题和描述文件
os.remove(title_file_path)
os.remove(description_file_path)
用这个的好处是可以批量打包。不过描述文件必须是纯英文的。不支持中文。
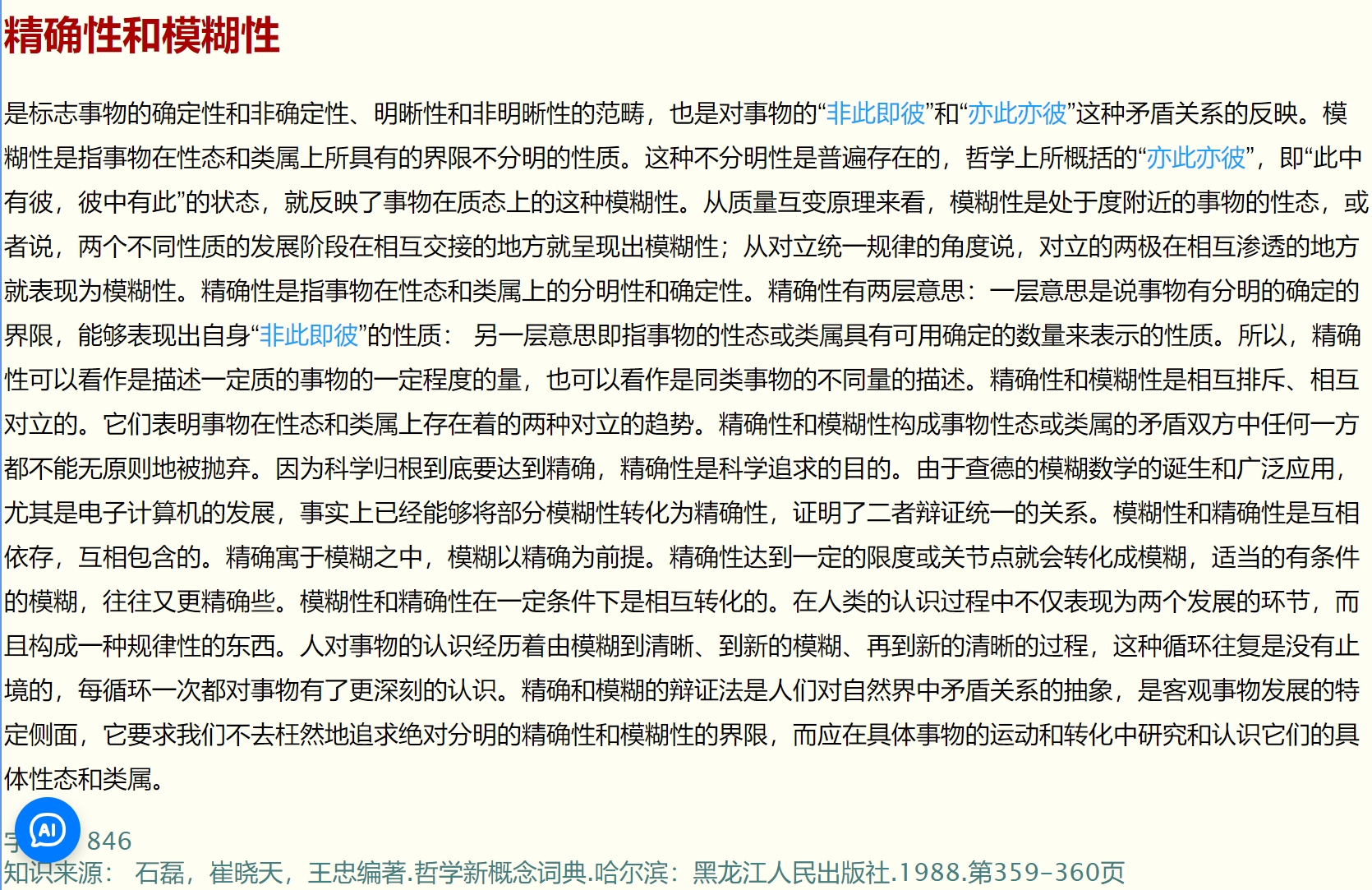
现在打包了一个词典,不知道在各个平台,各个词典软件的兼容性如何。请大家测试一下。如果兼容性不好,只好改回官方的MdxBuilder3.0手动打包了。
在WIN 11上MDICT测试通过。
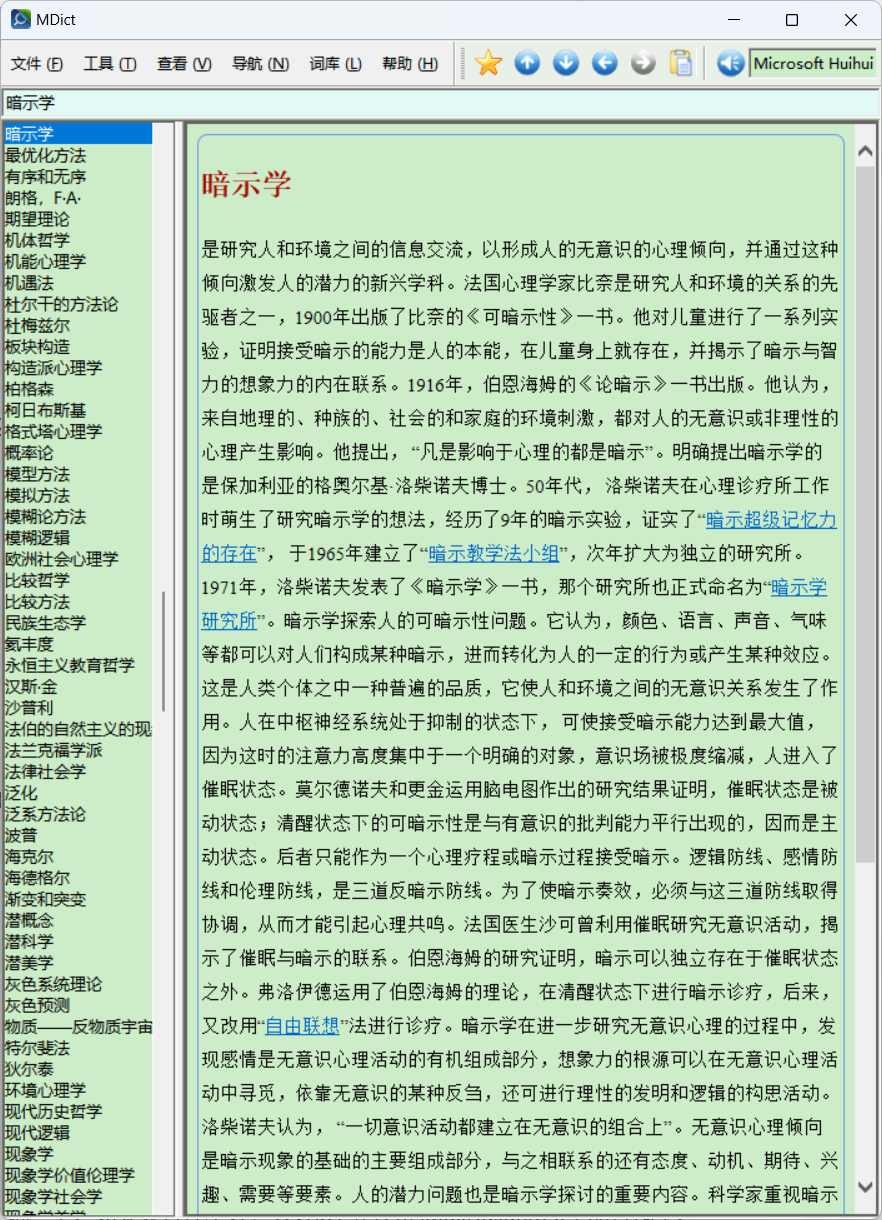
哲学新概念词典[1988].zip (555.0 KB)