已知问题:
- 有些空格是多出来的,有的又不能删。
- pua 413 个,puas.txt (6.0 KB)
- 图片仅下载了资源,未匹配标签
- 结构复杂,工期会很长、很长、很长。
下载:
- xdhycd.css (2.1 KB)
- 现代汉语词典.mdx (11.5 MB)
- 现代汉语词典.mdd.zip (6.0 MB)
预览:
感谢:
- amob 分享
- bud 分享
已知问题:
下载:
预览:
感谢:
谢谢,非常方便,试了几个字和词,和《现代汉语词典》解释一样
最好不要标注数据来源,这样标注被版权方发现的话,肯定会封掉这个获取渠道,以后就没有新数据了。
感谢,已修改。
这个词典之前有大神花大力气整理过,这个字体应该对录入PUA有点帮助。
STShusong_pua.woff (52.4 KB)
这个字体一共包含242个PUA字符,其中有不少未被Unicode收录的异体字形和数学公式,要完全避免PUA难度很大。
puas~XH录入.zip (9.6 KB)
PUA录入完成
“”: “𫘤”,
“”: “𬴂”,
“”: “𬴃”,
“”: “𫘝”,
“”: “𫘨”,
…
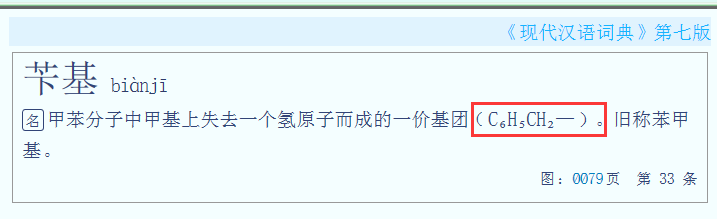
“”: “”, (㊟化学式字母与下标数字之间的标记,共3条7处,
磷酸 :H3PO4→H₃PO₄,
葡萄糖:C6H12O6→C₆H₁₂O₆,
龙脑:C10H17OH→C₁₀H₁₇OH )
“”: “”, (㊟"文"缺末笔见 xht001.jpg)
“”: “”,(㊟全宋体)
“”: “”, (㊟城墙符号见 xht002.jpg)
人狠话不多,出活超级快。
有三种方案
【H<sub>3</sub>PO<sub>4</sub>】,方便源码输入(带tag)、页面搜索(无tag)、显示效果也是对的,如H3PO4。我个人倾向用第一种,想了解下您的建议、喜好和使用场景。
使用深蓝词典加DictTango,那就用第一种方案,能正确呈现就好
好久不学化学了,这个键是不是有长键、短键之分啊 ![]()
and chiral squaramide co-catalyzed carbene N–H insertion reaction
U+2013, 《Nature》
看了几个例子,不同词典比如collins 还有用 U+002D,统一就好吧,我倾向于跟着 Nature 走。
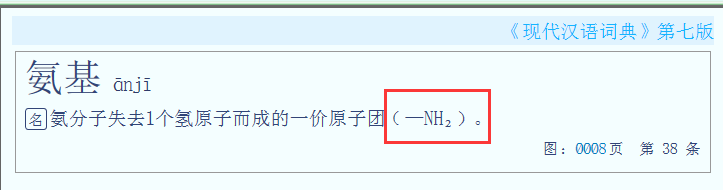
amines (-NH2) from NH3·H2O
The Ag−C distance in Int3-O is shorter than that in Int3-N
这篇 nature 里有 002d 和 2013 两种,NH2是最朴素的短的-减号。
Chemoselective carbene insertion into the N−H bonds of NH3·H2O | Nature Communications
嗯。
刚才搜了一下,002d、2013、2014,都有。短横、中横、长横。
没弄明白,还是保持原样好了。
未替换pua的 70101 个字词目 hwds.txt (511.0 KB)
有没有之前抓过网站发音的,分享下发音mdd,我就不用再写了。 ![]()
字词目的提取代码如下,由 bs4 换成了 lxml,非常快
import os
from lxml import etree
def get_projPath():
projPath = os.path.dirname(
os.path.abspath(__file__)
)
return projPath
def get_xmlsPaths(projPath):
paths = []
parent = os.path.join(
os.path.dirname(projPath),
'xmls'
)
for xml in os.listdir(parent):
paths.append(
os.path.join(parent, xml)
)
paths = sorted(paths)
return paths
def checkHwds(xmlsPaths, hwdTag):
hwds = []
for xmlPath in xmlsPaths:
with open(xmlPath, 'rb') as f:
t = f.read()
elesTree = etree.fromstring(t)
for citiao in elesTree.iter(hwdTag):
if len(citiao):
hwd = ''
hwd = checkTextTail(hwd, citiao, True)
for ele in citiao.iter():
hwd = checkTextTail(hwd, ele, False)
else:
# hwd = etree.tostring(citiao, method='text', encoding='UTF-8').decode('utf-8')
hwd = citiao.text
hwd = hwd.strip()
hwds.append(hwd)
hwdsPath = '../hwds/hwds.txt'
os.makedirs(os.path.dirname(hwdsPath), exist_ok=True)
with open(hwdsPath, 'w', encoding='utf-8') as f:
f.write('\n'.join(hwds))
def checkTextTail(hwd, ele, isRoot=False):
if ele.text is None:
pass
else:
hwdSub = ele.text.strip()
if hwdSub == "":
pass
else:
hwd += hwdSub
if isRoot:
pass
else:
if ele.tail is None:
pass
else:
hwdSub = ele.tail.strip()
if hwdSub == "":
pass
else:
hwd += hwdSub
return hwd
projPath = get_projPath()
xmlsPaths = get_xmlsPaths(projPath)
checkHwds(xmlsPaths, '词条')
发音六万多,失败了1000多条。其中er和|类型可以自动换,但是像总编辑,责任编辑的多个发音,只剩一个,大家可以官网查查或者app看看正确的资源地址是什么,反正我这是失败的。查了纸书总编辑就一个音,但是书面音标形式不代表实际发音,有的一个书面音配了四个音。
发音很重要,对普通话不好,经常错读的人更重要。
谢谢楼主!
小白 请教下这里发的这个现代汉语词典跟现代汉语词典第7版-20240219更新 - #183,来自 slgns
这个有什么区别吗?
请问STShusong_pua.woff这个字体是哪里来的?
——初始数据文本上,跟这个有何区别?
有些词条还是有错,如:怏怏