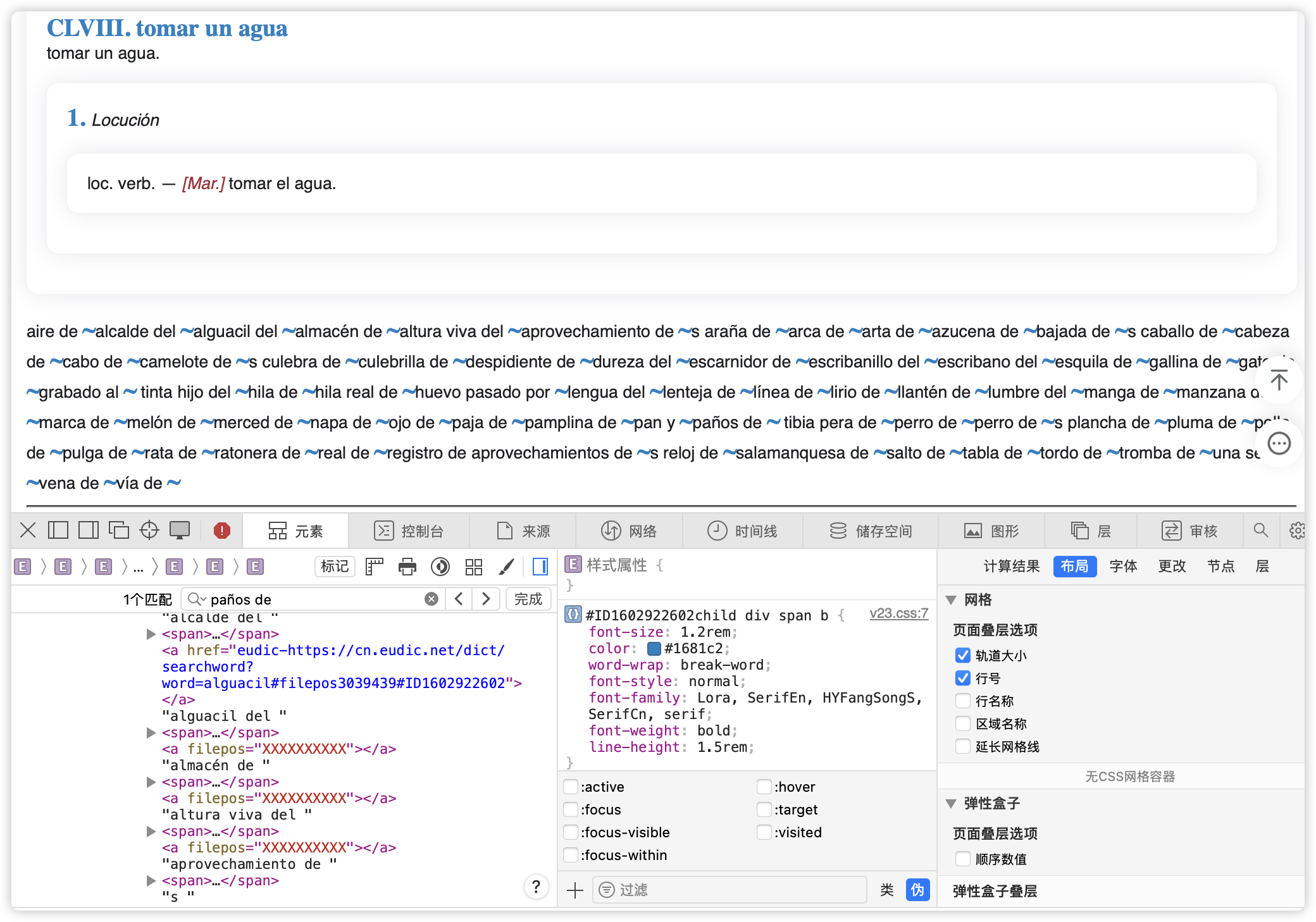
mdx 标签很乱,源代码惨不忍睹。
mdx(如下图),css样式我已经尽力了,没有办法再进一步美化。
原网站应该是 RAE(如下图)
SiteMap在哪里?我个人觉得抓取词条很困难。抓单词还要抓单词里的词组
那么mdx原数据在哪里?
mdx下载地址:
https://061061.xyz/38977.html
mdx 标签很乱,源代码惨不忍睹。
mdx(如下图),css样式我已经尽力了,没有办法再进一步美化。
原网站应该是 RAE(如下图)
SiteMap在哪里?我个人觉得抓取词条很困难。抓单词还要抓单词里的词组
那么mdx原数据在哪里?
mdx下载地址:
https://061061.xyz/38977.html
看文不仔细啊,都说是电子书转的,有两个不同大小的,不知道区别:
这个mdx原来没css,看着其实也还挺整齐,但是变位表没显示,数据里还没有同反义词。原链接中说原始数据是Kindle,那似为某个mobi文件。或可从epub重做
明白了,那么如何获取wordlist?若没有,我可以不可以提取mdx里所有词条抓取网站?150万……可能会有重复的。这方法好像不可取吧?
我之前做过一个去除各种变形的mdx,共93077条,这个没重复Diccionario de la Lengua Española V23
确实,这个词典的可视性极差