有些语言字母的形态需要根据词的阴阳性来变换。比如蒙古语当中字母g实际上是有阴阳两个,分别转写为g和ɣ,但是Unicode只有一个码位182D。这就需要字体的配合来实现正确显示。不符合一般规律的,通过3个FREE VARIATION SELECTOR(FVS)来选择形式。但流通的字体总有这样那样的问题。
这个字体是我发现的最符合Unicode的,但有一个问题,就是字母g在只有元音i的单词当中显示为阳性形态,这是错误的。一般情况下,只有元音i的单词被认为是阴性。所以这个字体在这种情况下把阴阳性判断错了。可以通过FVS来手动选择阴性形式,但这不符合编码理念。比如bicig这个单词,如下图,字体默认显示为左边那个,词末朝右弯的那个是阳性的g。正确的词性应该是右边那个,是通过输入在最后加上FVS2实现的。当单词中含有其他阴性元音时,词性的识别是正确的,比如becig(为了对比生造的),末尾的g显示就是正确的(第二张图)。
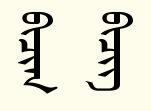

我想要校正这个错误却不知道怎么入手,甚至用fontforge打开之后,不作任何改动,都无法重新生成字体。有没有了解字体编辑的大神指导一下?
jcz777
3
字体修改三大法,
一是导,直接导入图片,最简单,但可能会很丑。
二是搬,搬相近的结构,拼在一起,相对难度大点,但是好看。
三是造,凭空创造,利用字体制作工具,创造一切可能的字符。需要较强动手能力。
修改字体后,最好重新给字体起个名,注意这不是文件名。
最后导出成ttf、woff等格式
看情况,你可能需要安装再使用,也可能直接使用。
最开始的时候蒙古文字体的设计非常混乱,编码标准也有过大改动,目前这个国际/国家标准大框架应该不会动了。Unicode把它设计成一个码点也是合理的,从音系上来说,它们可以其实是同一个音位,只是在阴性、阳性的两种情况下互补分布。不同编码方式的兼容是一个天坑
现在的情况是所有显示的情况都有了,只需要修改一项从编码到字形的映射方式。但更具体的我就完全捉不到头脑了
但那样的话其实加重了用户的负担,输入的时候需要自己选择用哪一个,那一种形式。这个字母还有其他字母不同的形式挺多的,但绝大部分是规律的。字体处理这绝大部分,剩下很少的就靠用户选择了。
他她它是三个不同的词素,和这里还不一样,这里只是一个音位和阴阳性元音配合时的不同形式,没有任何信息,最多就是好认一些,因为有时候不同的元音显示形式是一样的,比如非词首的阳性元音a和阴性元音e看起来就一样,但若词中有阴性写法的g,那这个元音就必然是e,因为蒙文是严格元音和谐的。类似这样的配合在蒙文里很多,这个字体把其他的情况都处理得很好。
蒙文的阴阳性和法语西语德语之类的不一样,就单纯的元音的区别,a、o、u是阳性,e、ö、ü是阴性,i姑且算是中性。阳性元音元音只能和阳性元音以及i搭配,词中辅音的形式若分阴阳就只能是阳性。阴性元音元音只能和阴性元音以及i搭配,词中辅音的形式若分阴阳就只能是阴性。若词中的元音只有i,那就归为阴性。违反这些的主要是最近借入的外来词以及合写的专有名词。前者很少,后者字体可以处理,我觉着这个字体是按照上面最近的元音的阴阳性来判断的,为了举例我生造一些词。
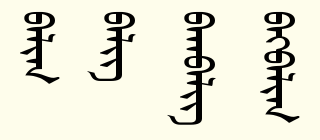
第一个是阳性balig,第二个是阴性belig,第一个音节ba和be的写法完全相同,但从最末的g的阴阳形式可以分辨究竟是哪个元音。第三个写的是bagbelig(第一个g是阳性,第二个g是阴性,显示正确),第四个写的是begbalig(第一个g是阴性,第二个g是阳性,显示正确),元音和谐律不允许,但也可能是两个词合成的专有名词。
不能正确处理的就是我提问的词中只有i的情形。