I have created a font that copies kanji shapes 大漢和辞典. The svg data and 大漢和辞典 id to unicode mapping comes from glyphwiki.org.
641 characters have overlapping unicode which means that I had to make a choice as to which 大漢和辞典 character to keep based on the information provided within the dictionary. Please let me know if I made a mistake.
The bundled python script uses fontforge to create fontforge project file based on the content of the SVG folder. The part before the space in the filename of the svg files is the decimal number representing an unicode code point.
Once the fontforge project file is generated (.sfd), open it in fontforge, select all glyphs and apply a 1000 fixed width to all of them. ctrl+a > right click > “Set width…” > “Set Width To: 1000”.
To generate the font files: File > Generate Fonts
Update 2022/12/07: Version 1.1
Fixed a bug where latin characters were displayed as being transparent. Fallback fonts for those characters should now work.
Update 2022/12/23: Version 1.3
Re-checked all 640 overlapping characters in order to fix some mistakes/select the most accurate character.
Fixed a missing glyph.
Generated additional font formats (otf, ttf, woff and woff2).
I’m planning to review all of them once again to make sure I didn’t make any mistake.
There is also an “issue” where I personally picked 俗字 over 誤字/譌字 but that might not always be a good idea because it doesn’t correspond to the glyph displayed in the unicode standard. To give a specific example, a user showed me this issue on telegram:
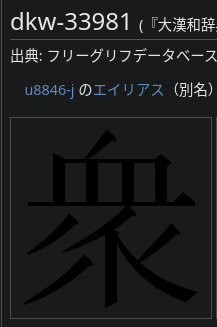
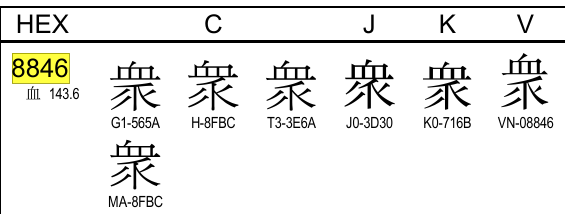
These two characters are both colliding within the “衆” unicode point so I had to pick one over the other. 33981 is registered as being 譌字 of 眾 whilst 49702 is registered as being a 俗字 of 眾. This means that I selected 49702 instead of 33981 but this glyph doesn’t appear in the unicode chart at all. In this case I believe it might make more sense to have 33981 instead.
what does the morohashi glyph look like? (I no longer have this dictionary because the the picture quality on mine was poor, despite talking up several GB)
I have attached pictures of the glyphs in question in my post above. These are svgs from the glyphwiki.org project. The 大漢和辞典 ID is the number displayed after “dkw-”
An hd version of the mdx dictionary can be found here: 百度网盘 请输入提取码 提取码:js6f
oh I see. IMO, the so called Unicode standard is a reference guide for common use, you should not be limited by it if the goal is to faithfully represent a particular glyph in a dictionary.
if the dictionary has both glyphs then one should find a way to preserve both. if the issue is that the available svg glyphs are merely approximate, well, heh, then it has be manually customized. there is a lot of variation for this character.
I would like to represent both glyph but it is not possible because they share the same unicode code point for 衆 (the 正字 “眾” is a totally different code point so no issue there):
+matches the unicode standard for “衆”
-譌字 classification within 大漢和辞典
-doesn’t match the unicode standard for “衆”
+俗字 classification within 大漢和辞典
From my understanding, 俗字 is more “correct” than 譌字 since 譌字 is a pure mistake whilst 俗字 is just informal. But in this case, this would mean choosing the glyph that doesn’t correctly represent the unicode standard.
the Unicode code chart is for providing reference glyphs that represent regional standards, standards used by modern institutions.
that’s not relevant to representing the actual variants found in classical dictionaries. if the glyph is faithful, use it, and then choose the codepoint that best corresponds to the character.
as for concepts like 正, 俗 and 譌, they are useful for thinking about historical change, but as value judgments these categories are not absolute and actually shift over time, and can even differ from dictionary to dictionary. if a particular glyph had been used for centuries, who are we to tell the ancients they were wrong all along? as if they are stuck in their historical moment while we are somehow outside of time and freed from history.