skippy
1
几年前把一个来源不明且受污染的汉语大词典转为stardict格式,放在Kobo 的Koreader里面使用。由于使用时间不短,曾经遇到不少繁简转换错误,随手查对其他本子修改了。当然还有许多问题存在,但由于花了不少时间,不忍弃置。有个格式问题倒是很碍眼,就是在不该换行时换行了。例如:
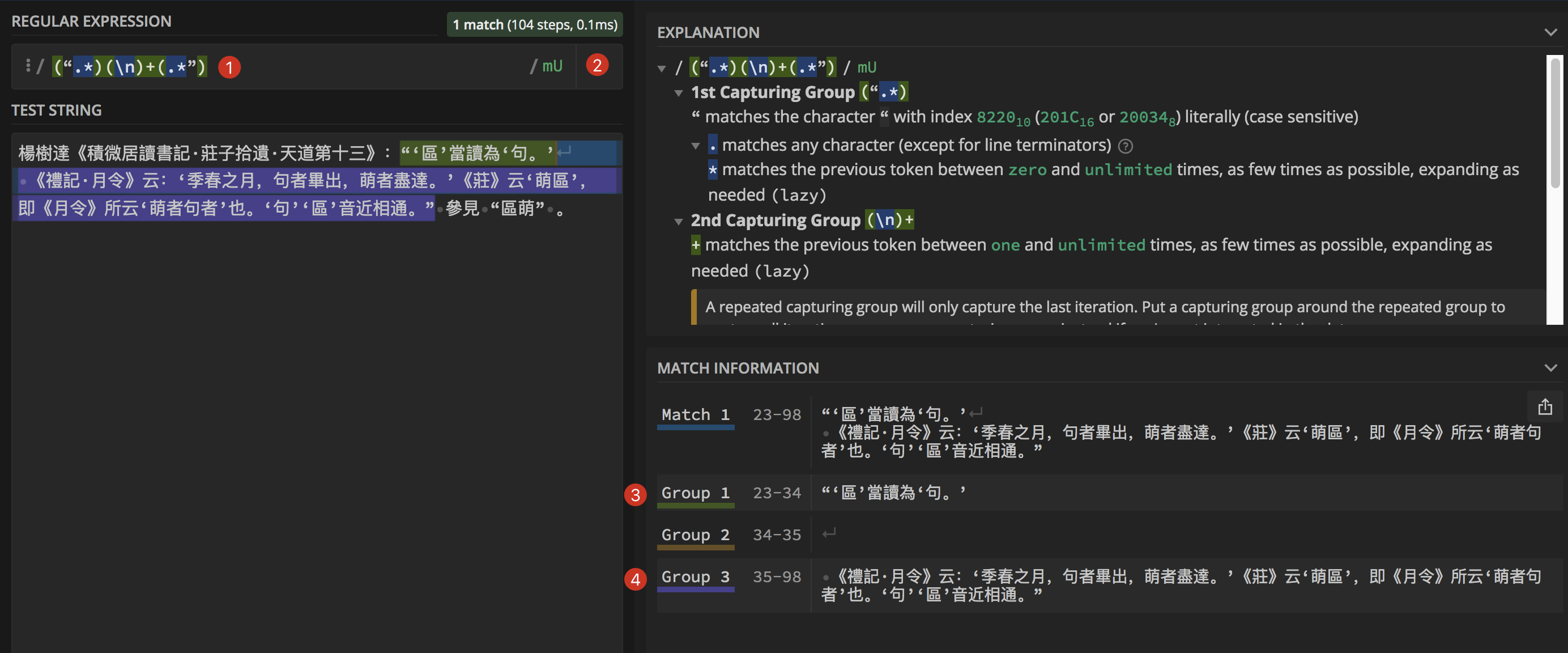
楊樹達《積微居讀書記‧莊子拾遺‧天道第十三》:“‘區’當讀為‘句。’\n 《禮記‧月令》云:‘季春之月,句者畢出,萌者盡達。’《莊》云‘萌區’,即《月令》所云‘萌者句者’也。‘句’‘區’音近相通。” 參見 “區萌” 。
要把“和” 之间的\n 都删除,在正则式里怎么做?谢谢!
1 个赞
没有看懂,请贴更完整的有问题的词典内容,应包含大量上下文。
此问题的难点在于怎么保留需要的换行,你要把限制条件想得很清楚才行。
skippy
3
:“‘區…相通。” 之间的两个双引号内,都是楊樹達书的引文,不应该在《禮記‧月令》前换行,所以想把这换行指令删除。
我刚才在VS里面只搜到一个能用的Regex Editor插件,整半天居然没找到 input string 开启自动换行的方法。请教下你这分析正则式用的是什么工具?VS Code里的插件?
你用的是网页啊,我还以为是IDE里自带的分析工具呢。
我在VS中搜到一个唯一个还能用的插件,有点奇葩。IDE里写代码换行开关我知道,这个换行是指插件窗口里的换行。这个插件基本没法用。回头我试试你上面说的几个。以前都是人工算capture group,有点痛苦 
哦,那 regex101 比那个插件强多了,实时匹配测试,实时分析。
btw 我很多时候,有些简单的临时替换,会直接在浏览器控制台里写。
1 个赞
可以考慮把所有例證、釋義中的 \n 都刪掉,重新認定例證。例如在 EmEditor:
-
先標上例證必有的結尾:
FIND:([。?!][’]*”)
REPLACE:\1◨
-
再標上例證之中必有的標點:
FIND:(》:“) 或 (:“) 看狀況處理。
REPLACE:\1⬤
-
把例證夾在標籤。第二括號指例證:
FIND:(。|◨|</🗹>|<p>)([^。⬤◨🗹]+⬤[^⬤◨🗹]+)◨
REPLACE:\1<🗹>\2</🗹>
第一個括號裡的 | 是 or 的意思:A or B or C or D 等等。按照自己數據調理:指定例證開頭的候選位子。
比方說:例證可以從釋義句子的逗號(。)開始。自然也可以從前面例證的結尾(◨|</🗹>) 開始。或從 (<p>)標籤開始。這正則邊調邊用。字典格式不一。
弄完,把 [⬤◨] 刪掉。
然後把 <🗹>、</🗹> 換成你要的標籤名。
這做法的前提是 “ 與 ” 的引號數量是對稱的。用 FIND 來分別計算。不數也罷了,不用那麼龜毛、事兒媽哈哈。
4 个赞
Sadly anomalies always exits, esp. in a large text file.
嗯,標點經常有問題,我沒見過引號完全對稱的數據。
而且漢字字典的標點要先標準化,零碎的半寬 .?! 改成全寬 。?!
1 个赞
这个解决不难,各人根据自己的常用资料的特点写一个批量正则替换的脚本进行标准化处理一下就行,象你做的那个正则就是经过长期改进得到的吧。
嗯,不難,按照自己數據調理。弄一弄,做到可以用的程度。
要達到近 100% 的準確度,會發現紙本本身也有問題,標點有錯失、例證的格式不規範,難免要手工處理些。常見的是 《書名》:“引文”。這逗號錯位。
釋義 如:“AB”、“AC。” 也是錯位。這是搭配詞例,不是例證。
如果 0.5% 有問題,說多也不多,講絕對數也不少。古代汉语词典2,例證我沒整理,翻翻應當有問題。
2 个赞
我以前处理OCR文本多的时候,就攒过一个极长的脚本,使用时间越长就越完善。处理不了的可疑之处,自动标记出来再人工处理,基本可以达到满意
1 个赞