注:本文在如下平台有备份:
以hunspell_ja_JP项目文件为例浅析goldendict构词法规则 - NoHeartPen的文章 - 知乎
《以hunspell_ja_JP项目文件为例浅析goldendict构词法规则-语雀》
以hunspell_ja_JP项目文件为例浅析goldendict构词法规则 - 软件经验交流展望 - FreeMdict Forum
前言
本文以MrCorn0-0/hunspell_ja_JP: Hunspell morphology dictionary for Japanese used in GoldenDict. (github.com)项目(以下简称“原项目”)的构词法文件为例,参考Linux hunspell 官网提供的 man 4 hunspell PDF 文件(以下简称“手册”)讲解基础的构词法规则。
提前声明:本人才疏学浅,只是大致弄清楚了原项目的构词法文件的部分规则,可能会有错误的地方,希望大家理性阅读,友好交流。另外原项目只针对日语,如果是其他语言的构词法问题,我可能无法解答,请自行查阅手册。
GoldenDict 的构词法功能使用的技术主要是 Hunspell,这个本来是 Linux 端的拼写检查工具,所以 GoldenDict 和向德语系学生介绍 hunspell提到的略有区别,GoldenDict 的构词法只有下面将会讲解的后缀名为.dic和 .aff 的 2 个文件,并没有后缀名为.morph、.good、.wrong、.sug的文件,不过.dic和.aff文件的规则 Hunspell 的手册是完全一致的。
关于这 2 个文件的作用,引用向德语系学生介绍 hunspell的说法:
- .dic 词典文件,里面的内容类似纸质词典里的词头(lexem)。
- .aff 还原规则集,里面写了怎样把一个加了前缀后缀或与其他词语复合的复杂形式,转化为一个词典中存在的词头的许多组规则。
dic 文件基本格式
dic 文件比较简单,就是形如下面的文件(最开始的数字表示 dic 文件收录的词汇数量)
450851
あ
亜
亞
吾
我
高い/XA
部分单词有个/,后面还有看起来像是乱码的东西,这种写法可以直接理解为在告诉软件单词的词性,表示这个单词有一个名为XA的变形规则,后面会详细介绍,这里只需要知道 dic 文件里面可以指定一个单词的词性即可。
另外,GoldenDict 的 dic 文件收录的单词会在启用构词法功能时影响最终查词结果,最好谨慎对待这份文件里的单词,不要贸然修改。
aff 文件
aff 文件的规则非常复杂,下面只讲解原项目使用到的规则,研究其他语言或者有其他需求的同学请自行查阅 Linux 项目的 man 4 Hunspell 手册。(重要的事再重复一遍,本人英语也只有四级水平,读手册非常吃力,完全是靠猜测加验证得出的结论,并不是读手册读懂的。各位与其指望一个日语专业的英语学渣,不如自己尝试一下呢:)
MAP
先用一个例子介绍最好理解的 MAP 规则:
#拼写变体
MAP 89
MAP あア
MAP かカ
MAP さサ
MAP たタ
MAP 89表示下面将会有 89 条 MAP 规则。
MAP 规则简单理解就是忽略指定字符的差异,比如MAP あア表示输入ア会被当做あ来处理,所以这个规则在原项目中是用来处理日语拟声拟态词的书写习惯,比如チョコチョコ在大多数权威词典里面都没有,而经过规则替换后的ちょこちょこ很多词典都有。
不过,原项目在最后的部分有个我尚未完全理解的式子:
MAP (ゃ)(ャ)
按照手册的说法,Use parenthesized groups for character sequences (eg. for composed Unicode characters):(使用括号包裹的分组来处理由多个字符组成的特殊字符,比如 Unicode 中的那些特殊符号),所以这几条规则应该是针对拗音——对于チョロチョロ,计算机使用チ、ョ、ロ这 3 个字符来表示,所以替换的时候,需要专门一起替换么?但是我并不认读懂
另外,下面这样的规则似乎并没有什么意义,因为很多字典都没有收录腕きゞ这样的词条,替不替换其实无所谓。要真想解决踊り字导致的问题可能还是得借助正则表达式才可以(哼哼,我就是在嘚瑟~《日本語非辞書形辞典 v3》在上个版本已经完美支持啦)
MAP (ゝ)(ヽ)
MAP (ゞ)(ヾ)
(这样可能看不出来,找图片看得更清楚,第一列的符号都有个小勾)
REP
下面介绍与 MAP 规则很像的 REP 规则:
REP 12
REP かけ 掛け
REP かか 掛か
(原项目写的是REP かけ 掛け かけ,可能是写错了……)
和 MAP 一样,REP 12说明接下来会有 12 条 REP 规则,但和 MAP 不一样的是,REP かけ 掛け的かけ是输入,掛け才是替换的结果(和 MAP 的顺序是反过来的),另外,REP 规则可以实现多个字符的替换。(用制表符来分割参数,而 MAP 只能使用()局限性比较大)
aff 基本格式
接下来回过头来介绍 aff 文件的基本格式,所有的 aff 文件都应该是下面这样开头:
SET UTF-8
LANG ja
FLAG long
# https://github.com/MrCorn0-0/hunspell_ja_JP/
SET设定文件编码;
LANG指定规则适用的语言,其他语言请参考手册;
FLAG long指的是给规则命名时需要使用 2 个 ASCII 码的字符,比如后面会用来当做例子的一个规则,XA 就是规则名。:
SFX XA Y 1
SFX XA い く い
如果喜欢用数字直接给规则编号,可以按照手册的:The long' value sets the double extended ASCII character flag type, the num' sets the decimal number flag type. ,在文件的开头写FLAG num,之后就可以按下面这样的风格起名了:
# 形容詞く
SFX 001 Y 1
SFX 001 い く い
为了方便以后修改,用数字命名时最好通过注释进行解释说明。注意:#要放在每一行的开头,所在的那一行才会被当做解释说明的内容。
不过通过数字命名还会导致一个问题:如何对一个单词同时使用多个规则呢?(用言的活用都不是一种对吧?)
如果使用long我们只需要把规则直接写上去就可以了(长度都是固定的 2 个字符,程序可以识别):
高い/XAXB
使用数字时就需要用英文半角逗号来区分:
高い/001,002
SFX
之所以要回过头去介绍 aff 文件最开始部分的写法,主要是想强调 dic 文件可以指定多种规则,这里的多种规则不是指的 MAP 和 REP,而是为了接下来介绍的支持自定义命名的 SFX 规则。
这里专门强调支“持自定义命名”,是因为命名不仅会影响 aff 文件,会影响 dic 文件。
一开始就提到了 dic 文件中可能会出现这样的写法:
高い/XA
在某种程度来说,SFX 规则才是真正意义上的构词法,通过这个功能可以构造词缀、实现词形还原,才能实现日语活用的推导与辞書形的还原。(接下来的内容主要参考手册的AFFIX FILE OPTIONS FOR AFFIX CREATION章节部分。)
首先,还是以一个简单的例子进行说明:
SFX XA Y 1
SFX XA い く い
第一行:XA是我们自定义的词缀的名字,Y 是固定的参数(手册里有谈到 #? ),1 是这个名为XA的词缀包含的词缀数量;
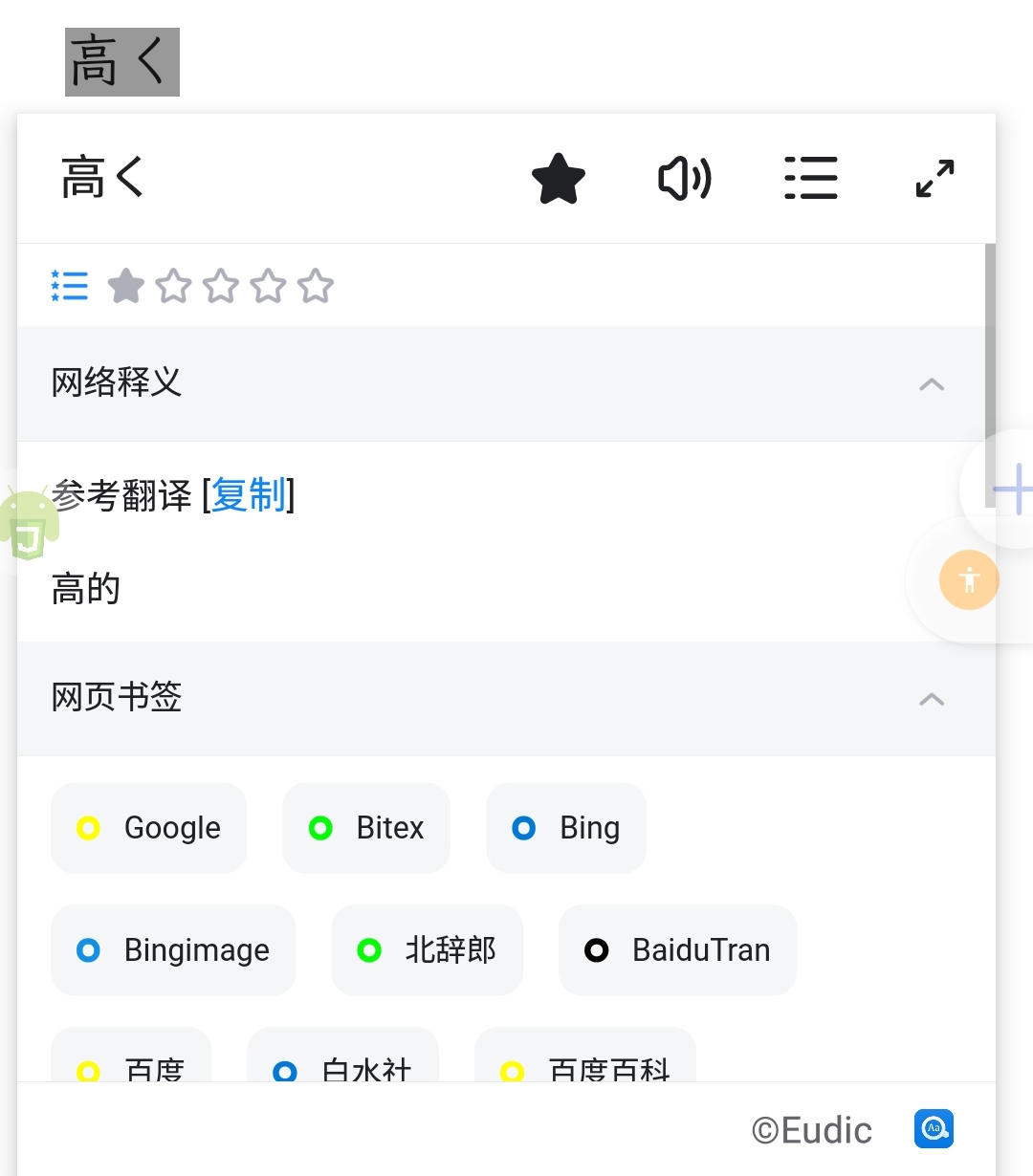
第二行,第一个い表示这条规则只对dic文件中的以い结尾的单词起作用(手册的说法是stripping characters from beginning (at prefix rules) or end (at suffix rules) of the word,我的理解是我们定义了一个名为 XA 的词缀,词缀的真正内容是い。这个词缀就是程序处理时会处理的部分),く表示这条规则将在输入的单词以く结尾时发挥作用,末尾的い表示构词法真正发挥作用前还需要满足的一个条件:“构词法推导的单词结尾是い”,不满足的话,不会展示推导结果。
举个具体的例子,当我们输入高く时,程序将く替换为い(这里的い是第二行的第一个い),然后查找 dic 文件中以い结尾单词是否有高い(这里的以い结尾是因为第二行的第二个い),如果有,那么 GoldenDict 就会直接跳到相应的界面。
之所以说简单,是因为原项目中这条规则其实是下面这样:
#形容詞文く
SFX XA Y 2
SFX XA し く/BaTe し
SFX XA い く/BaTe い
这是因为日语中高く还可以继续活用,所以用户可能划词的部分是高くば或者高くて,原项目作者充分考虑了日语的这个特点,使用/这条规则来处理嵌套的连续变形(是不是有点眼熟?因为在 dic 文件中,这个符号是用来表示单词可以用于哪些规则,你可以理解为词性)。
需要注意的是,BaTe是 2 条独立的规则,是原作者自定义的,查阅原项目的 aff 文件就可以找到:
SFX Ba Y 1
SFX Ba 0 ば .
(我不是很确定是否有高くば这样的语法,但我将这条规则剥离出来进行测试时,发现这条规则确实会让软件在输入高くば时展示高い的解释)
SFX Te Y 3
SFX Te 0 て [っいしく]
SFX Te 0 で ん
SFX Te 0 て .
(关键就是SFX Te 0 て .这一句,其他是规则从日语语法的角度来说和 SFX XA し く/BaTe し、SFX XA い く/BaTe い无关,原项目作者可能是出于个人习惯将他们归为一类)
这里出现了.这样极为特殊字符,之前说过,它们所在的位置应该是表示替换后的结果中词尾应该包含的字符,而这个位置的参数有一个规则是Zero condition is indicated by dot.,所以SFX Te 0 て .的意思是对于任何处于词尾的て直接将其删除。
这样说可能很难理解规则的作用,我们回到SFX XA い く/BaTe い这个规则,把它和SFX Te 0 て .放到一起再举一个例子就好理解了:原项目作者是为了处理输入高くて。(去掉/BaTe的话,就和《日本語非辞書形辞典》一样:对于划词的要求变高了,所以原项目真的设计得非常好)
上面的例子由于涉及到了双重嵌套,可能还是不好理解,有疑问的话,参考手册的Twofold suffix stripping章节和AFFIX FILE OPTIONS FOR AFFIX CREATION部分。其实我也没有怎么搞懂啦
下面再举一个例子:
SFX To Y 1
SFX To 0 とも .
To是规则名,0代表这条规则会删掉定义的词缀とも,とも表示实际输入的单词的词缀, .表示对于替换后结果没有任何要求,所以这条名为To的规则作用是:去掉输入框中输入的位于词尾的とも。(这条规则很符合学习とも这条日语规则的思维,所以也许会好理解一点吧。)
另外,SFX Te 0 て [っいしく]这里出现了[っいしく],按照手册的说法
这表示替换之前输入的字符中要有っ、い、し、く中的任意一个。
下面还有一些比较难的自定义规则,只做简单介绍:
[^行]く和正则表达式的意思一样,规则只对那些不含行く、但又以い结尾的单词生效
SFX 5T く い/TeTaTrTm [^行]く
SFX 5T く っ/TeTaTrTm 行く
这条规则就是稍微长了“一”点,实际没什么特殊的
SFX KN く け/RUTeTaTrTmf1f2f3f4f5f6m0m1m2m3m4m5m6m7TiTItiSuNgQq1Eba1M1myo く
这个规则其实可以拆成 2 条,但原作者灵活运用了[]的语法
SFX xU い かる/bs [しじ]い
题外话
本人会对构词法感兴趣完全是因为《日本語非辞書形辞典》项目遇到了棘手的问题,想看看有没有其他解决的思路,所以才会花近一周的时间阅读晦涩难懂的手册。虽然只了解大概,但已经感受到 GoldenDict 的构词法 Hunspell 功能的强大之处语言学 YYDS!,抱着授人以鱼不如授人以渔的想法分享自己的总结希望能让大家对这个功能有点了解,也期待大家能一起完善 GoldenDict 的构词法 Hunspell 功能。快去- hunspell_ja_JP提交 issue 和 PR 吧
不过还有个更重要的原因:才加入 FreeMdict 的@epistularum 用类似《日本語非辞書形辞典》的思路做了一个 GoldenDict 构词法的 Demo(在 GitHub),为了与 Ta 沟通交流,我才下定决心把拖了几个月的事情给正式提上日程(英语不好真的是举步维艰……)
另外,提前预告一下 GoldenDict 可以轻松解决曾经提到过的日语复合动词汉字书写的问题啦:
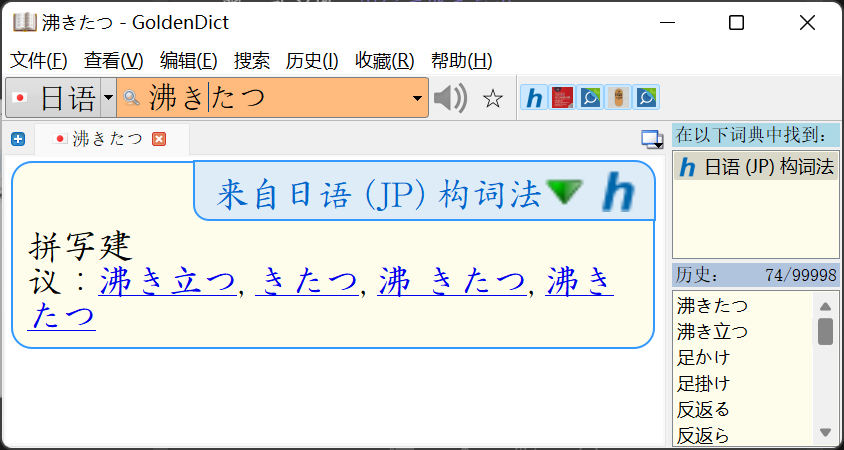
另外,很奇怪的是 GoldenDict 的 hunspell 功能可以返回多个结果,欧路词典也有类似的 hunspell 的功能,但却只支持返回一个结果。虽然按照手册说法只有一个特性在手机上可能不受支持BUG: UTF-8 flag type doesn't work on ARM platform.,但欧路不会因为这个原因不采用这个技术吧……
但不论如何,都应该支持多个拼写结果才对,比如:
雨が降ります。
バスから降ります。
参考
教程
-
- 最关键的就是名为 man 4 hunspell 文件,其他文件是介绍 Linux 端实现的技术细节
- 提供一份我的批注版:
-
向德语系学生介绍 hunspell - 许一诺的文章 - 知乎
- 整理了上面用到 man 4 hunspell PDF 资料,讲解了一些简单的概念
开源项目
- MrCorn0-0/hunspell_ja_JP: Hunspell morphology dictionary for Japanese used in GoldenDict. (github.com):按照日语语法的思路写了将近 400 条构词法规则,作者是一位中国人
- epistularum/hunspell-ja-deinflection: Hunspell dictionary to deinflect all Japanese conjugated verbs to the dictionary form and suggest correct spelling. (github.com):按照替换词尾的思路写规则,不是很完善,作者是一名外国人
- https://github.com/wooorm/dictionaries:收录了 JavaScript 写的构词法,但没有日语