看见一个帖子:《教育部重編國語辭典修訂本》mdx版 - FreeMdict Forum,里面提到了字体精简与压缩的问题,因此我觉得可以把自己使用到的工具及经验分享给大家。
使用的系统为 Windows10,工具为 fontTools。
【前期准备】
1. 首先,点开此电脑(或文件资源管理器),开启显示文件扩展名的选项。如下图:
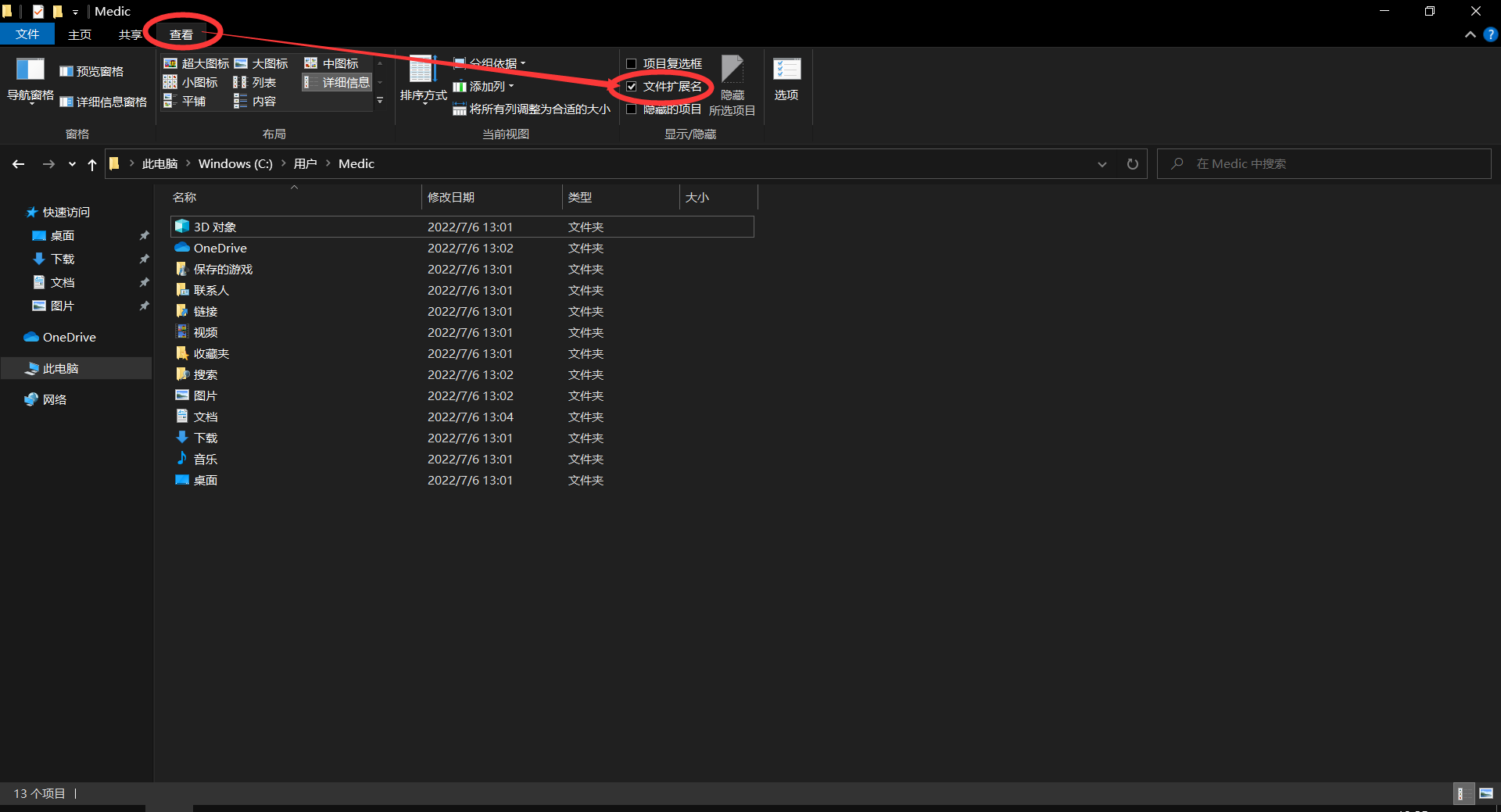
开启该选项后以便于区分文件后缀、文件类型。
2. 第二步,下载并安装 Python 3.6 之后的版本。
如下图,进入 Python 官网下载适用于 Windows系统的安装包,目前最新的是 Python 3.10:
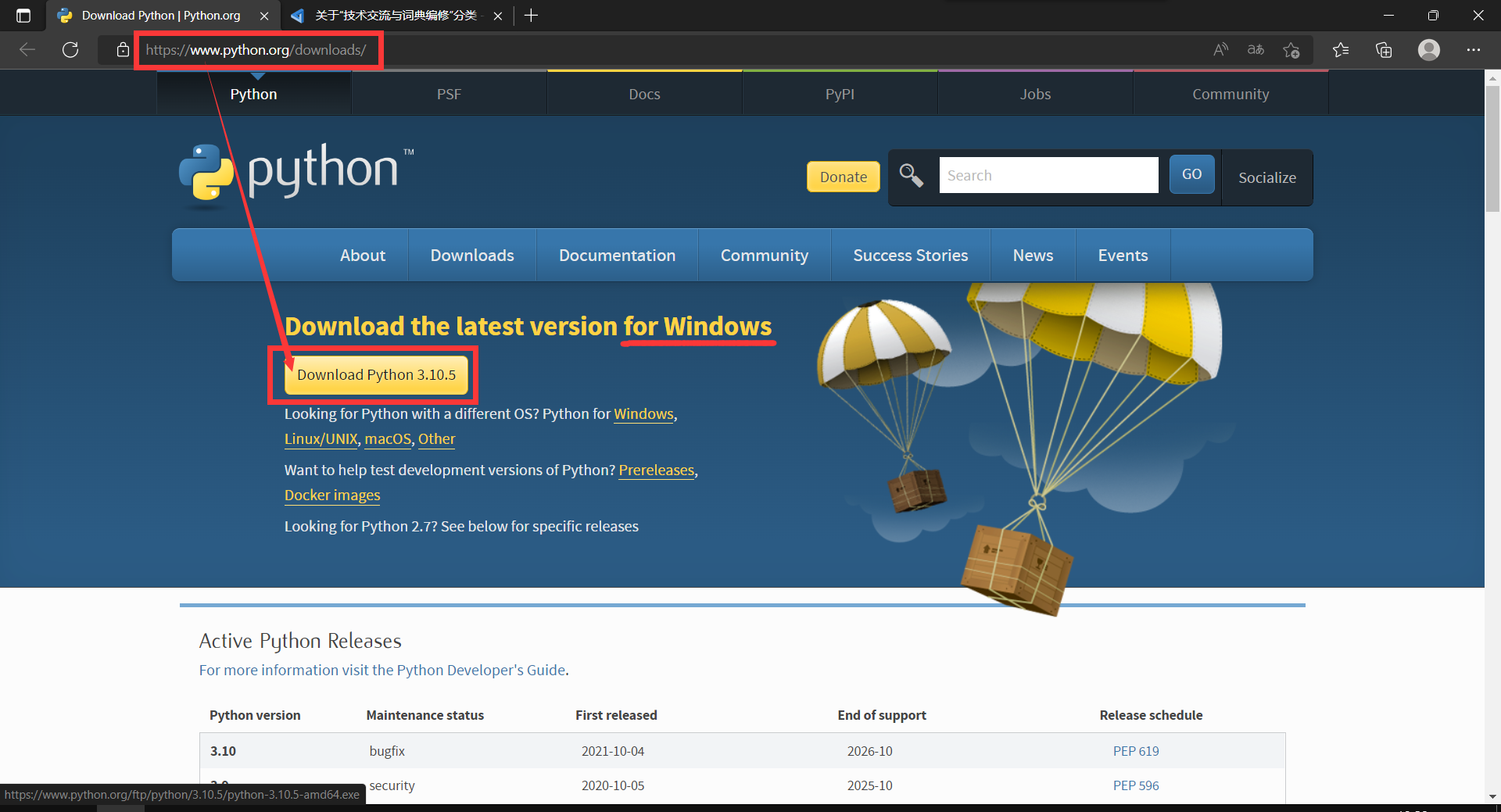
直接进入 Microsoft Store (微软应用商店)下载 Python 按理也可行,但我没有试验。
下载好安装包后,运行,出现下图安装界面(注意最下面的 Add Python to PATH 选项应当勾选,否则后续会多出很多步骤):
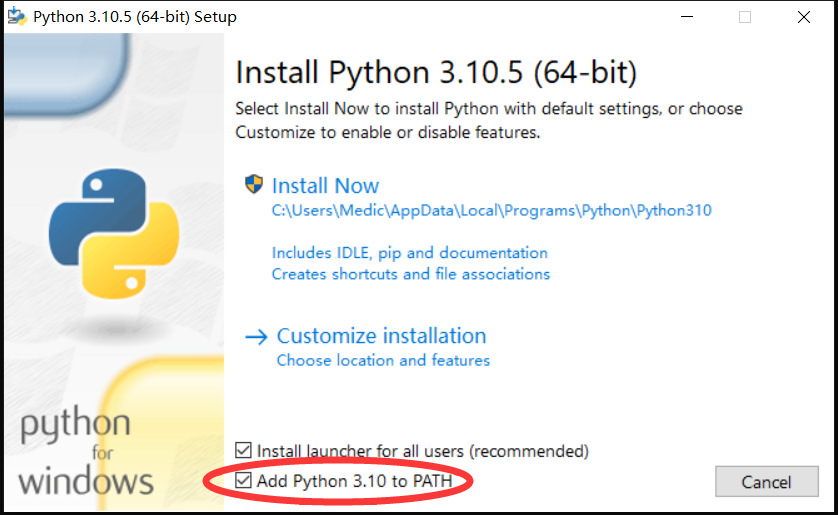
然后点击 Install Now (立即安装)即可。
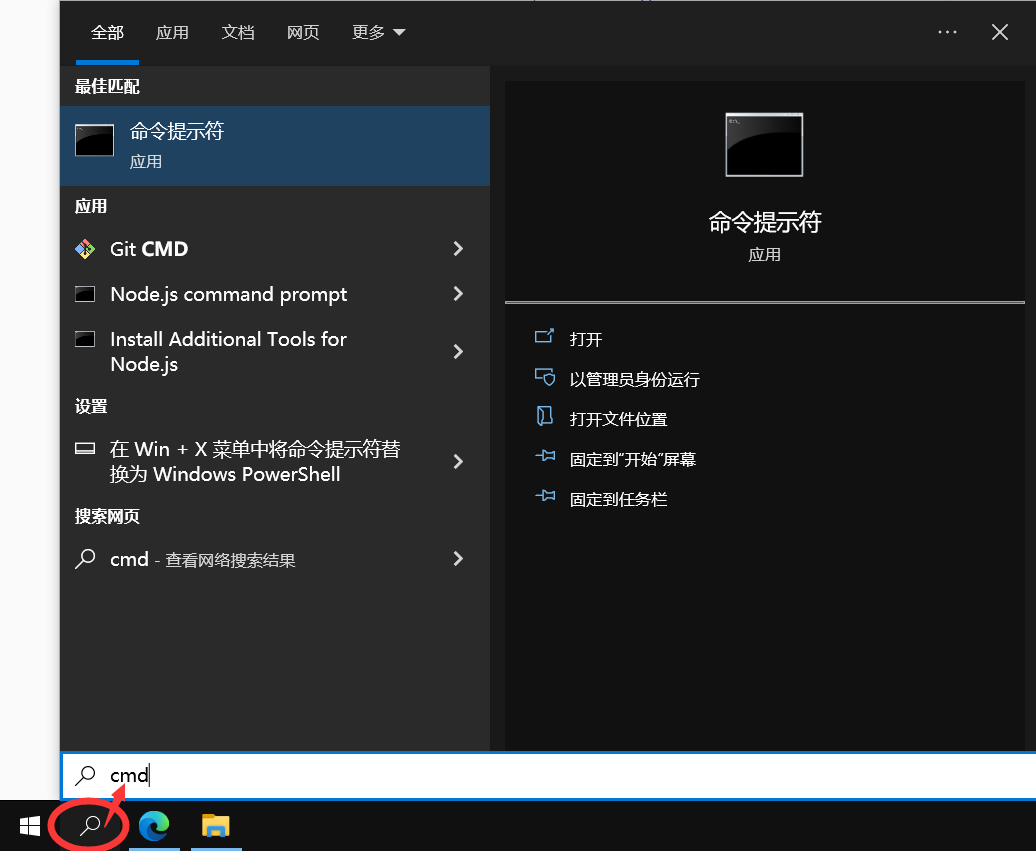
3. 第三步,打开命令提示符。
如下图,左下角开始菜单旁有搜索按钮,点击,输入 cmd ,然后打开即可:
若搜索框搜不到,也可以打开文件资源管理器,按照下图的路径找:
打开后应当显示的是如下页面,其中 C:\Users\ 后面是你登录Windows系统时的用户名,每个人各不同,不需要在意:

接着,直接键入 python ,然后按键盘上的 Enter 建(下文统称“回车”)。若 Python 安装成功,且第二步提到的 Add Python to PATH 勾选了,则如下图:
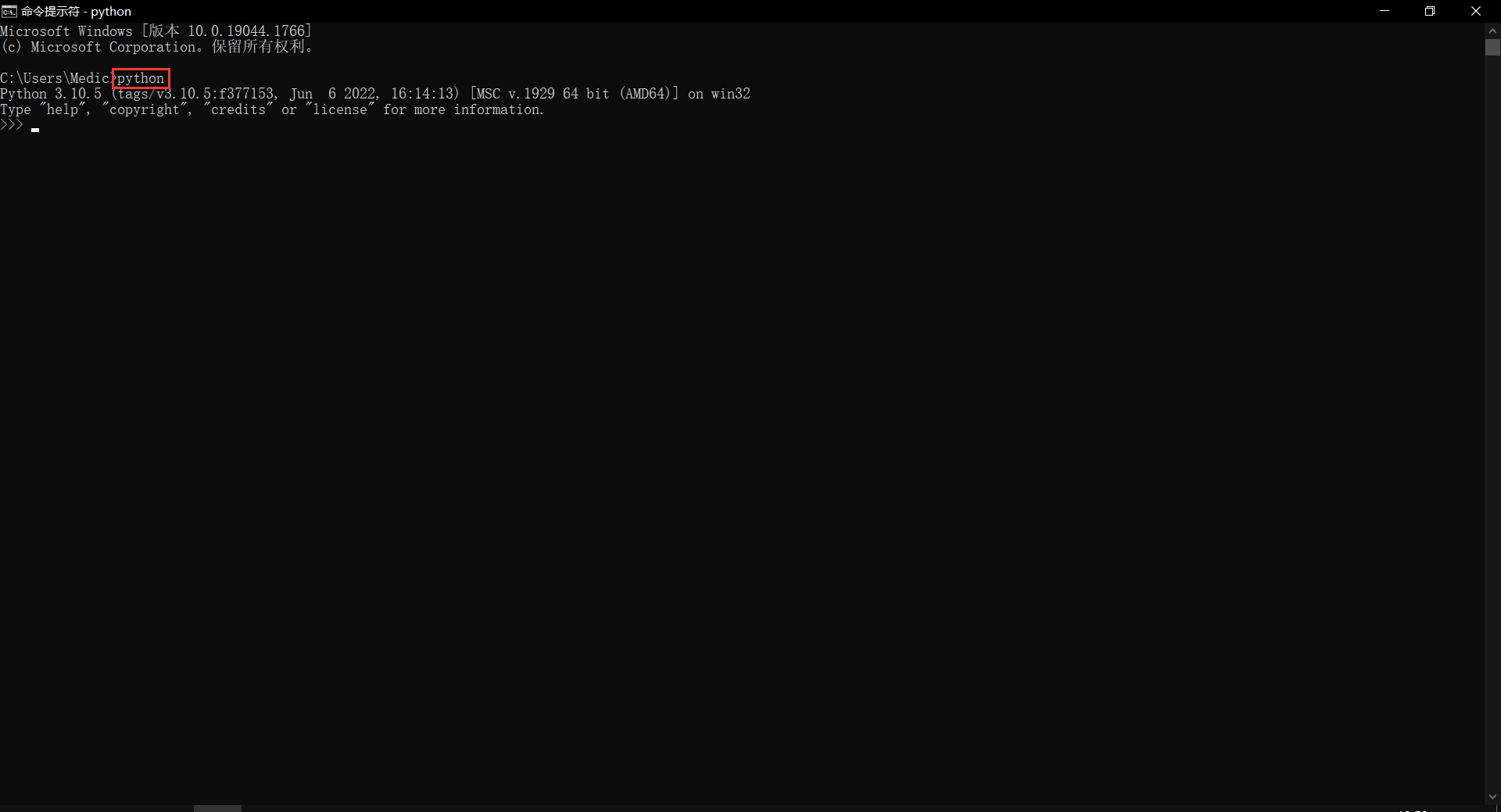
后续操作 fontTools 不需要进入 Python,因此可以退出该界面,键入 exit() 后回车,或 按 Ctrl 和 Z 并回车即可。实在关不掉的话,右上角叉掉cmd的窗口,重新打开一遍就行。
4. 第四步,安装 fontTools。
如下图,键入 pip install fonttools 后回车即可:
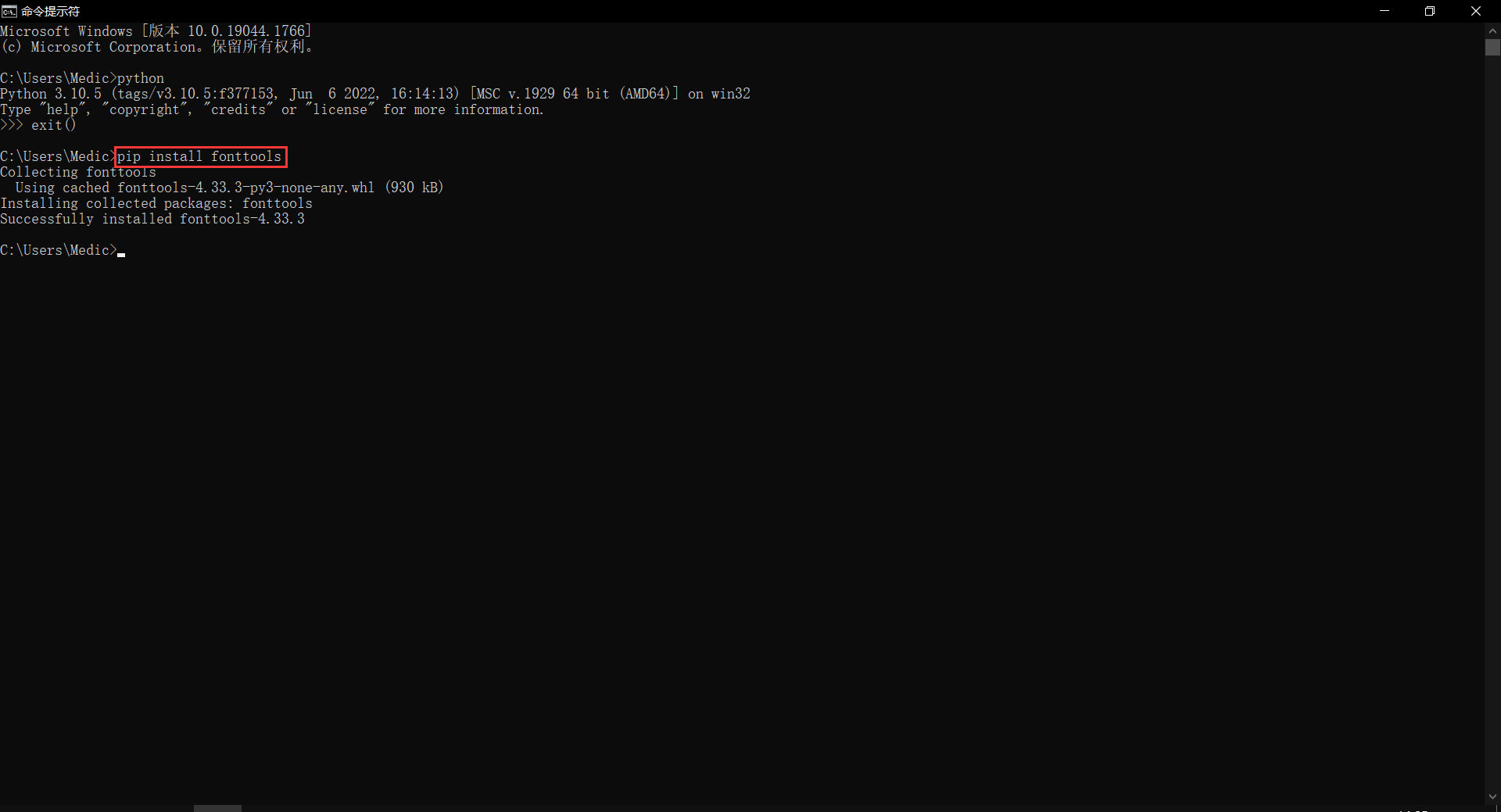
若出现一行黄色字,说 pip version 等等之类的,不用担心,是 pip 需要更新,不更新暂时也没事。
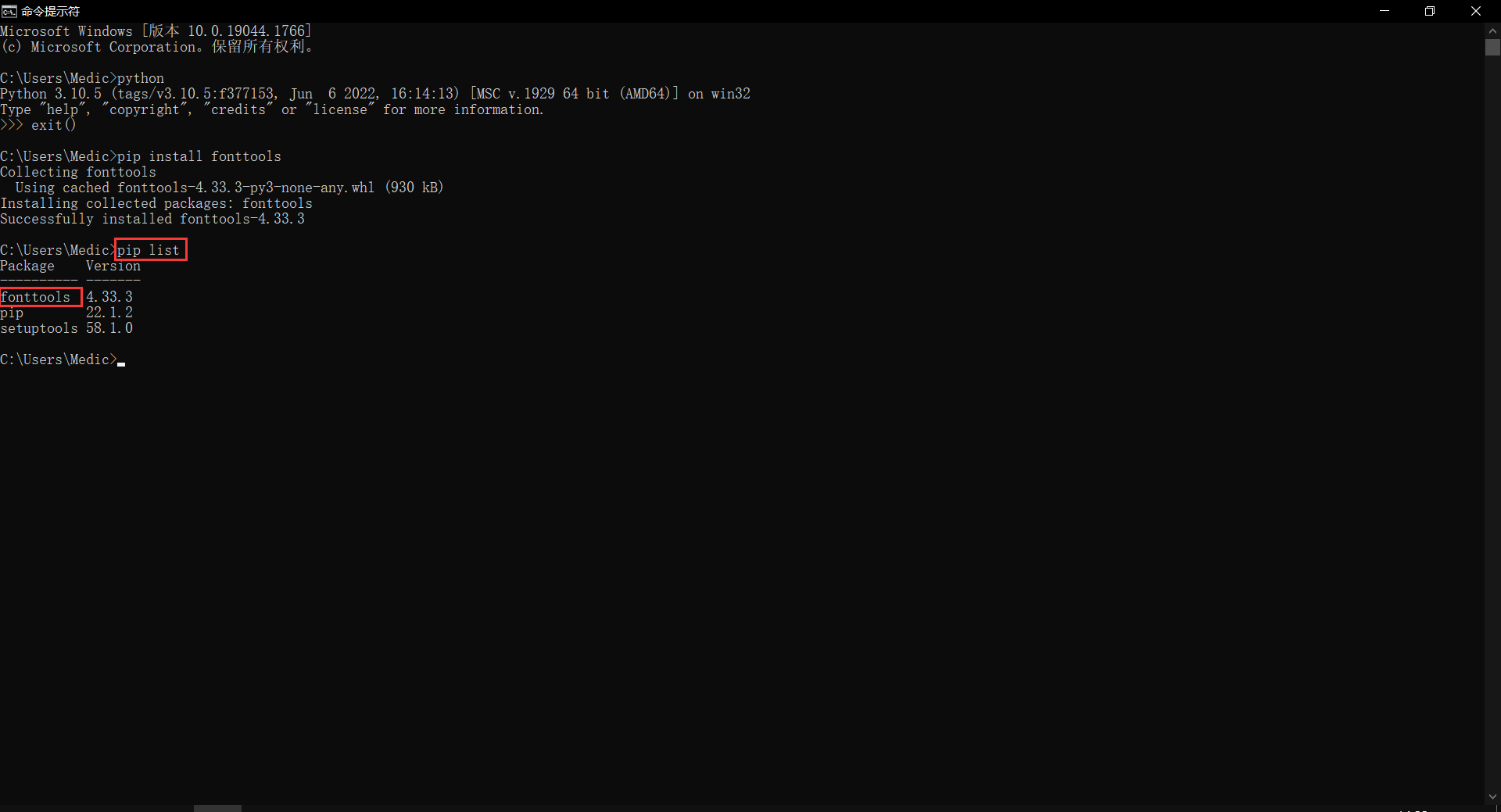
键入 pip list,回车。如下图,可以看到 fontTools 已经安装好了:
【正文开始】
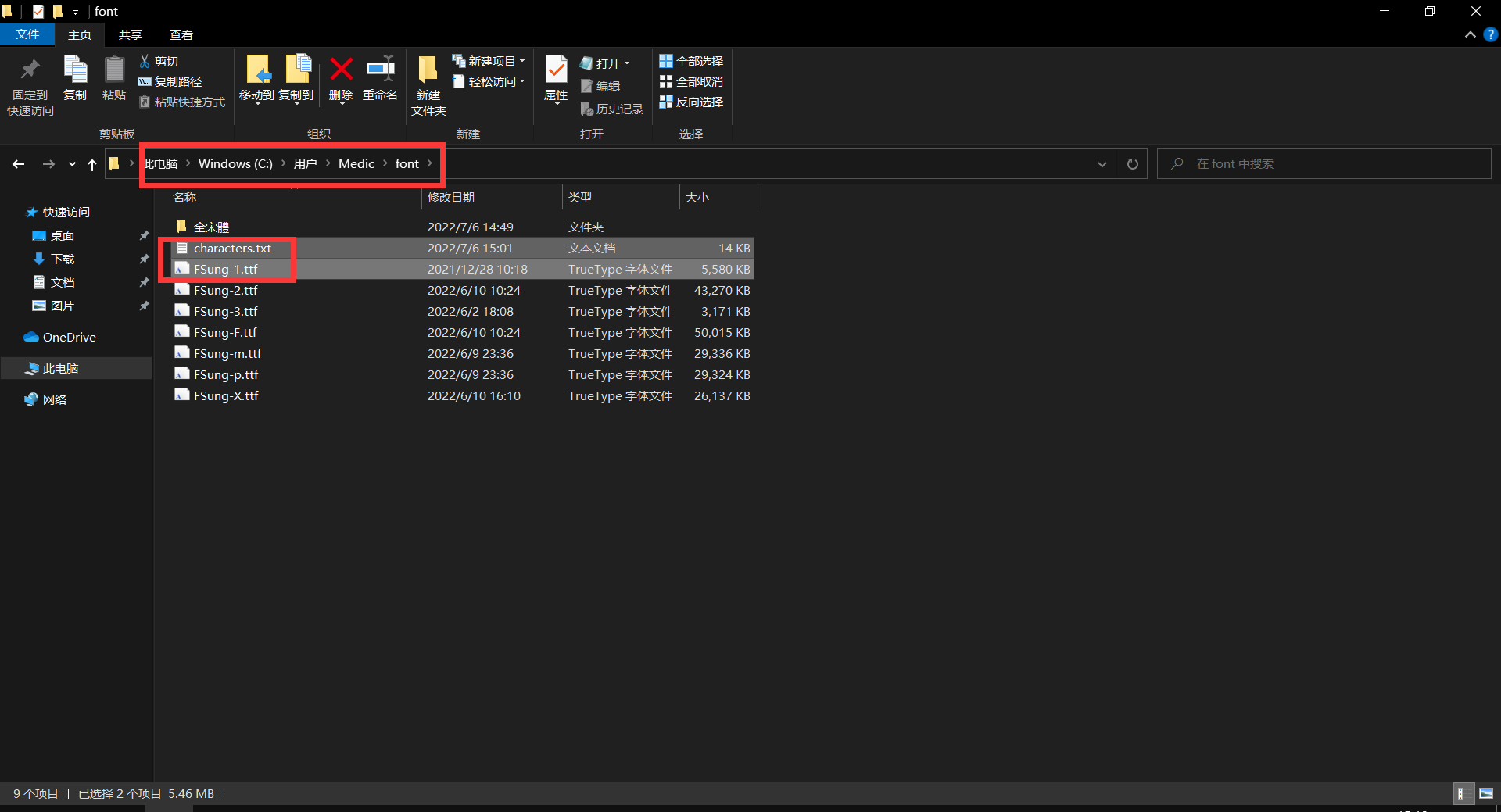
5. 第五步,准备好字体文件和要保留的字库文本。
如下图,需要先准备好一个文本文档(内含需要保留的字符,空格、换行等不影响效果),此处该文档被重命名为 characters.txt:

接着,字体也准备好。此处用于示例的字体文件是 FSung-1.ttf (全宋體-1)。
我把字体文件与上一步准备好的文本文档都放在了 C:\Users\Medic\font\ 目录下(即 C盘\用户\自己的用户名\fonts 这个文件夹中)。如下图:
6. 第六步,使用 fontTools 的子集化功能 pyftsubset 来精简字体。
如下图。回到 cmd,键入
pyftsubset font/FSung-1.ttf --text-file=font/characters.txt
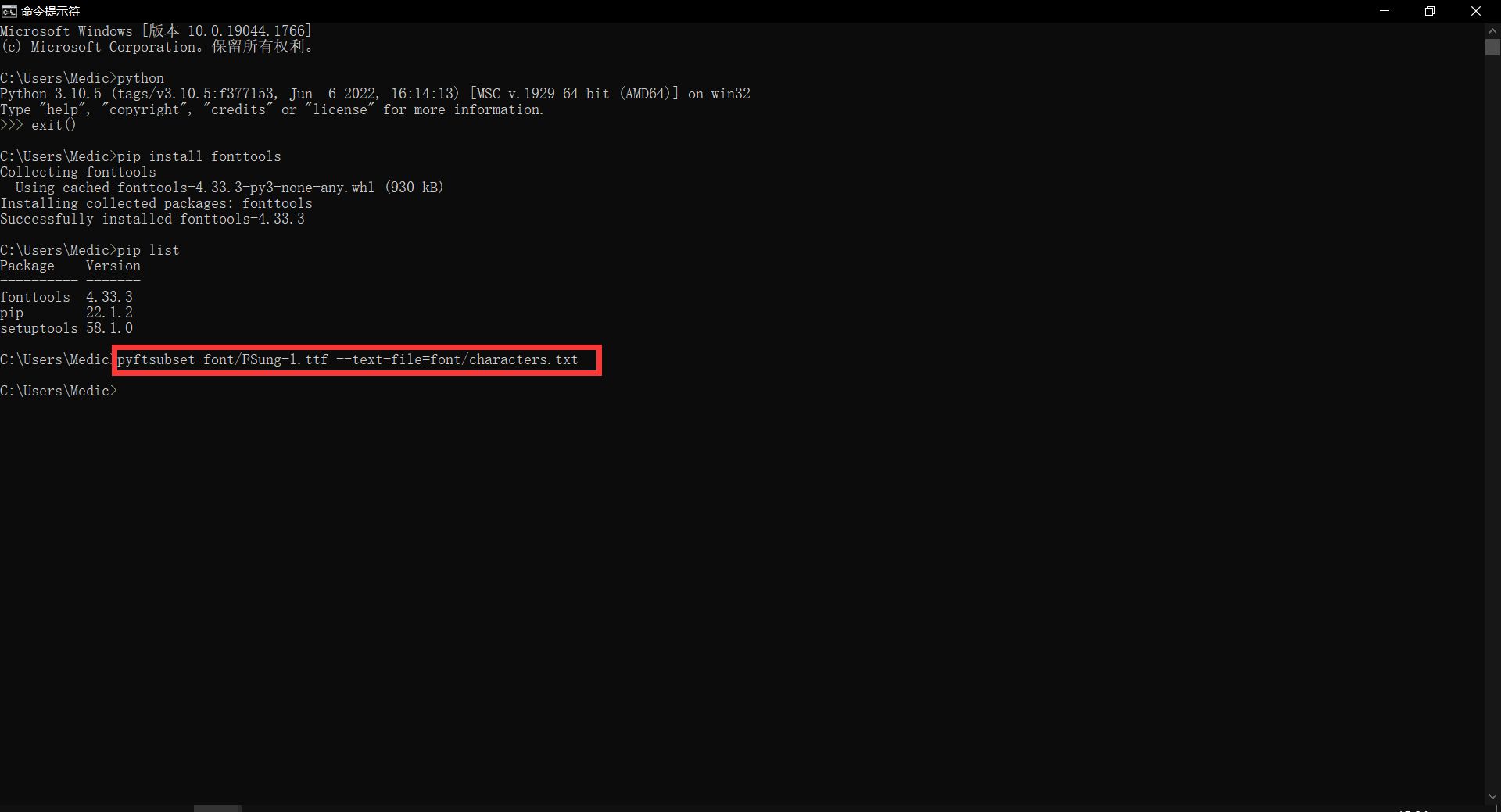
图中框起来的部分含义如下:
-
pyftsubset是 fontTools 内置的一款工具,用于字体子集化。 -
font/FSung-1.ttf是字体文件的位置。如第五步所述,FSung-1.ttf 这个字体文件在 C:\Users\Medic\font\ 文件夹中,而当前 cmd 已经处于 C:\Users\Medic\ 下,因此此处只需要标明 字体文件FSung-1.ttf 位于 font文件夹即可。
如果搞不清楚,那此处也可直接填入字体文件的完整位置,例如:
pyftsubset C:\Users\Medic\font\FSung-1.ttf --text-file=C:\Users\Medic\font\characters.txt
-
--text-file=表示后面所跟的文件内含字体中需要保留的字符。 -
font/characters.txt参见上面两条说明。
【正文结束,下面是可选步骤(非必选)】
7. 第七步,添加 --flavor=woff2 参数以生成 woff2 格式的压缩字体。
如下图,如果直接键入,则会报错,提示没有 Brotli 模块:
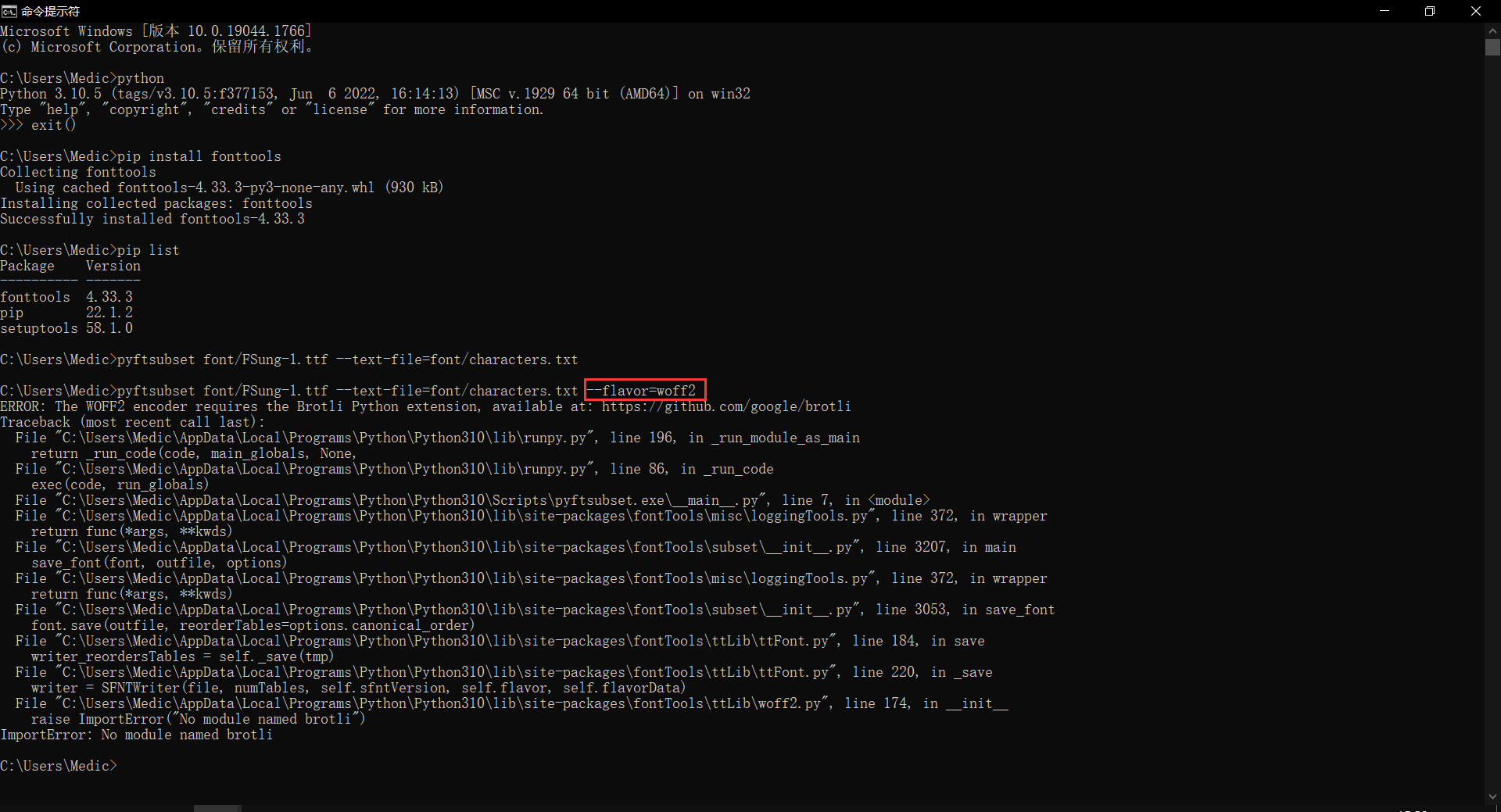
不要慌,按照第四步的方式,用 pip install brotli 安装一下即可。如下图第一个红框:
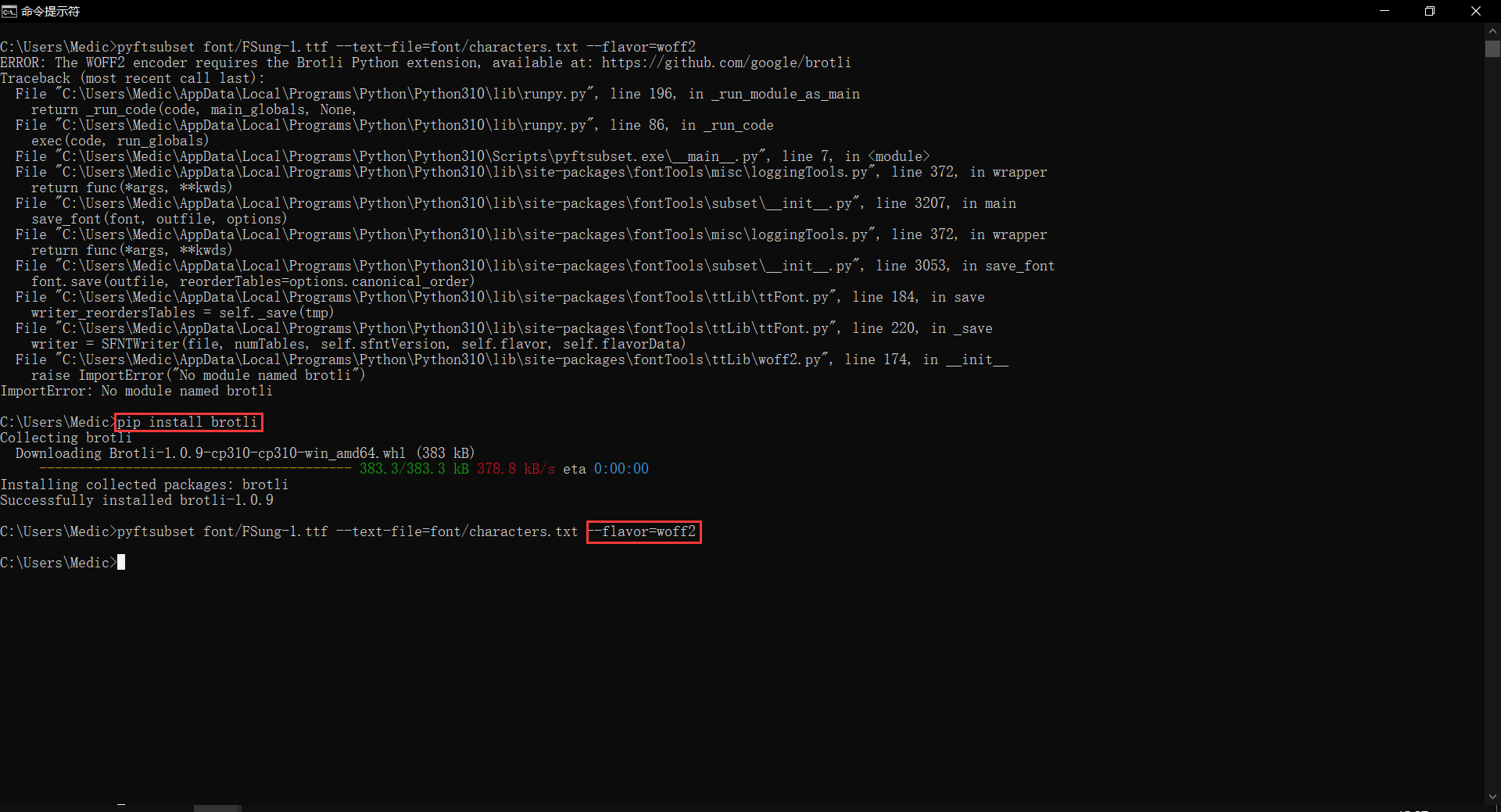
然后重新这样键入就没有问题了,可以成功生成。如上图第二个红框:
pyftsubset font/FSung-1.ttf --text-file=font/characters.txt --flavor=woff2
第六步(精简)与第七步(精简并压缩)的生成结果:
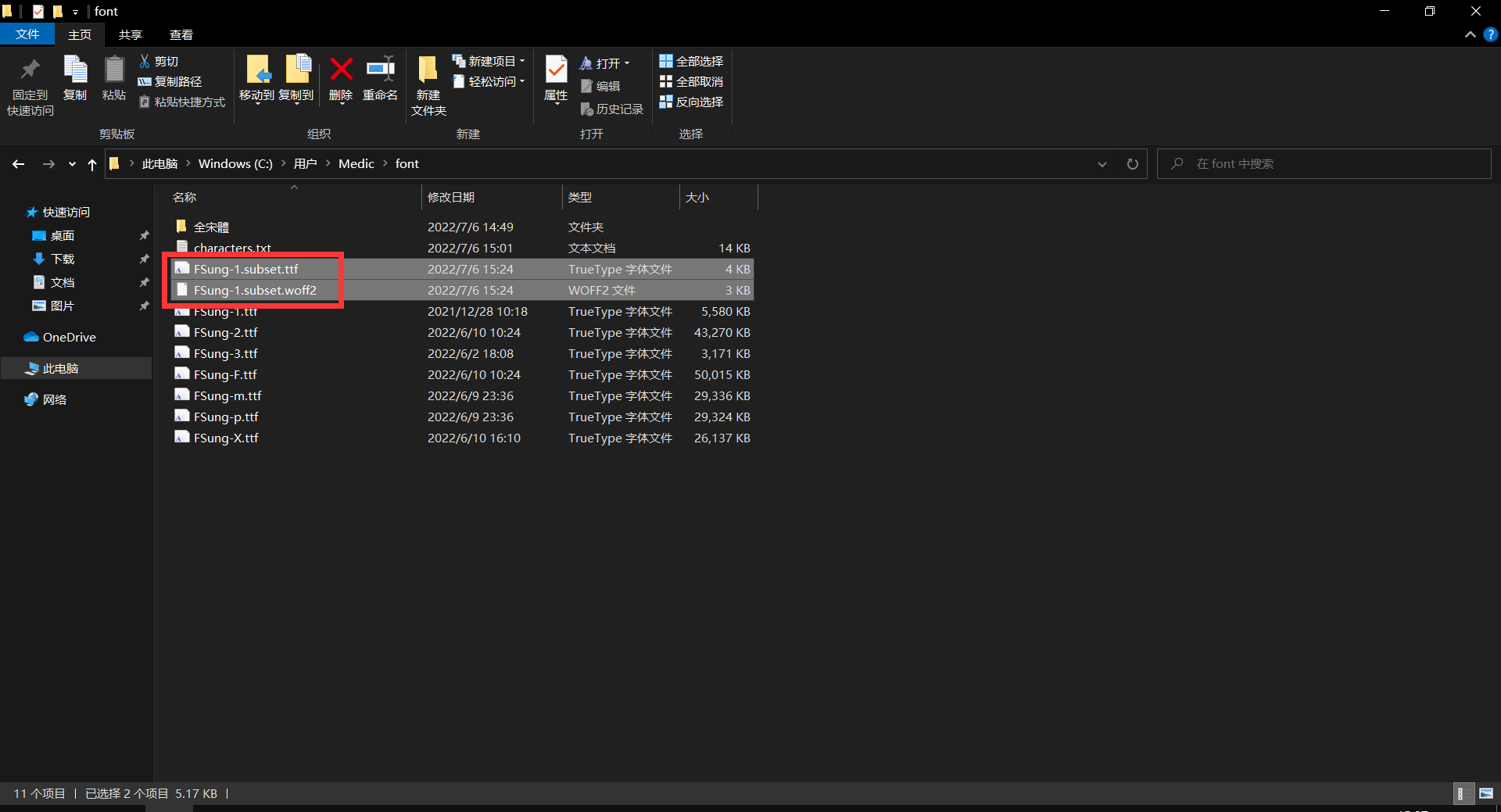
注: 源字体文件在哪,精简和压缩后的文件就在哪,且输出的字体文件名默认是 源字体文件名.subset。如果有需要,可以使用 --output-file= 参数来指定输出位置及输出文件名。
8. 其他:不精简,只压缩。
使用 fonttools ttLib.woff2 compress 即可。例如:
fonttools ttLib.woff2 compress font\FSung-1.ttf