比如一段话
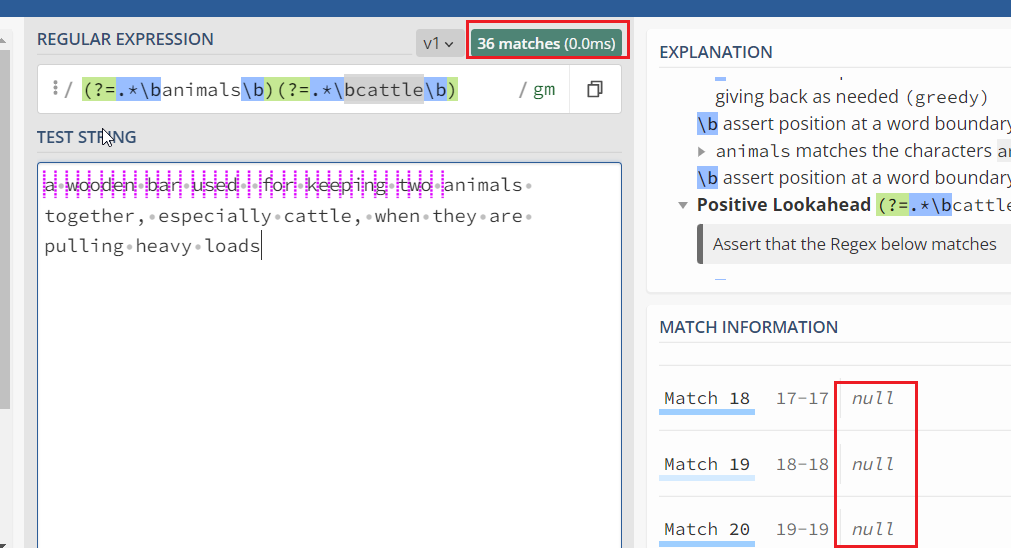
a wooden bar used for keeping two animals together, especially cattle, when they are pulling heavy loads
如何判断这段语句中,同时含有 animal 和 cattle
需要匹配的单词的数量不定,也可能是4个单词。
如果正则实在没办法一次性搞定。也欢迎提供比较优的判断方式
比如一段话
a wooden bar used for keeping two animals together, especially cattle, when they are pulling heavy loads
如何判断这段语句中,同时含有 animal 和 cattle
需要匹配的单词的数量不定,也可能是4个单词。
如果正则实在没办法一次性搞定。也欢迎提供比较优的判断方式
个人觉得单纯正则不太好处理,animal和animals, cattle和cattleman, worry和worries,shop和shopping要不要匹配到呢?
可以尝试打散成两个数组以忽略顺序,借助nltk或morphology字典,还原、变形数组内的单词,同时进行嵌套对比即可。
这个可以不用考虑。先按简单的case考虑。全匹配
不考虑正则的话,是个办法。
我做文本高亮的时候,也差不多的需求。没有用正则,直接读取的字符串,按空格或者标点符号分割字符串,前缀匹配就记下位置。
多谢各位。看来正则不适合。 转为程序处理
emeditor一种功能叫批处理,我忘了哪个视频了,你上B站搜。
(?=.*animal)(?=.*cattle)
如何?只是
判断这段语句中,同时含有 animal 和 cattle
如需匹配则是另一回事。
更多单词的话直接加后面,例如(?=.*animal)(?=.*cattle)(?=.*cow)
希望准确匹配的话前后加上\b, 例如 (?=.\banimals\b)(?=.\bcattle\b)
需匹配的话 (?=.*animal)(?=.*cattle)(?:cattle|animal)|(?:animal|cattle)
不过显然无法处理太多单词:3个单词有6种组合,4个单词有24种组合!
(?=^.*animal)(?=^.*cattle)
可以大大提高效率
(?=^.*?animal)(?=^.*?cattle)
再提高一点效率 ![]()