是的,这个就是国内的繁体字规范字形。
谢谢!
咱们论坛上哪位大侠,有这个字形表吗?或者符合这个字形表的词典mdx
http://www.homeinmists.com/Standard_glyph_list2.htm#1
白云深处提供了,在线查询。谁能做成mdx吗?
或许普通人没事查字典不推荐查《汉语大词典》,就像不推荐查OED一样 ![]() 可查现代汉语大词典之类
可查现代汉语大词典之类
根本原因是《古籍印刷通用字规范字形表》发布了,但这个只是指导性而非强制性的国家标准(其标准自身也需要不断听取反馈改进),因此目前还没有那个输入法宣布支持了该表(当然需要专门字体文件相配合)。
目前来看,可能籍合网的那个输入法和配套字体有希望率先做到这一点。
至于Unicode中同一个字的不同字形被收入到不同码位(甚至常用字形被排得很靠后),短期内没办法,程序员包括汉语圈的懂得异体字这些弯弯绕绕的凤毛麟角,更不要谈国外的程序员了。
自己动手的话,比较可行的是根据异体字字典或说文解字MDX中的异体字列表,按照《古籍印刷通用字规范字形表》整理出以下json格式的字典,用python脚本处理过一遍。
{
“丼”: “井”,
“円”: “圓”,
“刄”: “刃”,
“自定异体字”: “常用规范字”
……
}
mdict查日语词典,输入 风 能直接显示 風 的词条,应该是内置了简繁字集。当然不能期望它能收齐所有异体字,这应该是词库制作者和使用者的事。
从词典软件端入手,确实一定程度上可以解决词头的检索问题。
比如,在识典古籍搜索“后汉书”,后台实际上搜索(后)(後)(漢)(汉)(书)(書)的各种组合:
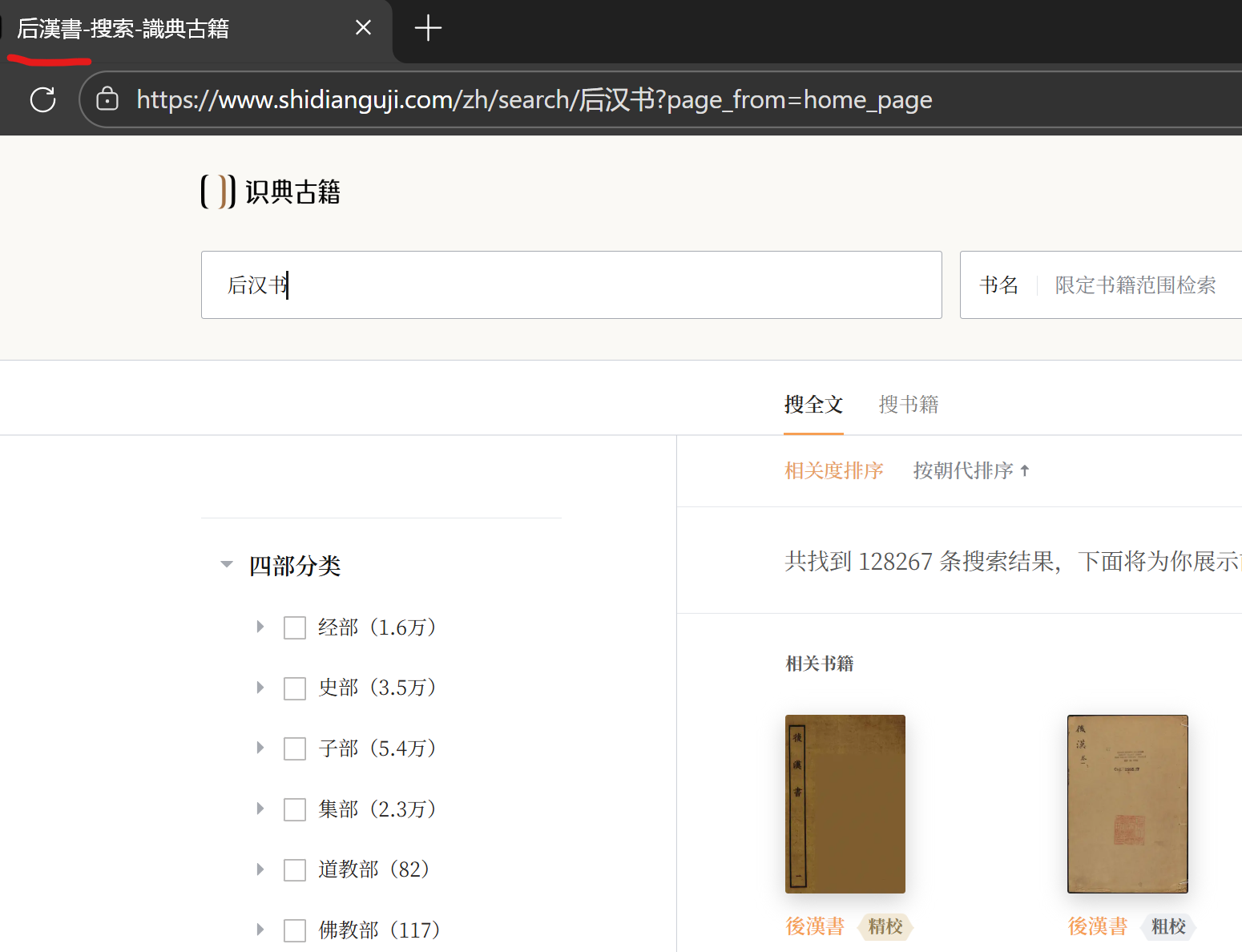
当然,在正规书籍中是不可能出现“后漢書”这种组合的。
责任划分,一个原则是“让专业的人干专业的事”。很多MDX制作者并不十分熟悉前端技术,所以我不赞成去要求制作者去不断改进MDX以适配各种词典软件,而应该是MDX用户去问熟悉前端的软件作者。
至于异体字这个场景,要求程序员去解决,并不是“让专业的人干专业的事”,所以才会看到“后漢書”这种组合。何况即便是由资深专家主持制定的《古籍印刷通用字规范字形表》,也有诸多质疑声音。
(后)(後)(漢)(汉)(书)(書)只是解决了词头的问题,但难以解决文本自身的进一步再利用。不知道古籍专业的LLM训练是不是先将古籍文本简体化再喂给大模型。
不会的,训练喂的是原文。
发现《方正古籍规范宋》明确说支持该标准,可能也是籍合网所用的。
方正古籍规范宋字体包,方正古籍规范宋字体打包下载_方正字库官网
另外,有漢文字愛好者“特里王”个人自制的京華老宋体,声明其遵守该标准