怎么回事?我下载那个压缩包只有219个字节,难道…… ![]()
hua老大这不是已经解密了吗?
看来只能做些笨活,为大神们做点服务了。看到了备考前全部正确,没有一处错误。这个文本质量很高啊。
这就是字体子集的加密思路。这个碼位 是配合钥匙使用的,不是传统常见编码中的码位,可以理解为在这个字体子集中的编号。“切”在不同词条中出现,对应的是不同的字体子集,编号不同才能达到加密的目的。
我没有下载顶层的文件,不知道理解的对不对
https://blog.csdn.net/weixin_46917978/article/details/108307049
下载不了,无能为力,看上面的帖子有没有帮助
hua老大是只解开了一个词条?要不上面那个不是完全没有问题了吗?
还有这篇https://blog.csdn.net/weixin_43189702/article/details/102927834?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-2.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-2.no_search_link
我只有一楼的一个词条文件,因为我下载百度云很折腾,又没有人帮我下。
算了,我折腾着把百度云文件下载完了。
1 个赞
我只仔細看了兩個字條,所注意到的是每一頁html,font-face指定了五六個woff。woff文件名都是獨特的,同一個woff不會跨頁而用。
我打開了20多woff,瞧了碼位範圍,都是4xxx-9xxx,故意模仿中日韓統漢碼的基本區,範圍不夠用如果每字分配獨特碼位,所以一定有recycle的碼位。也就是說,同一個碼位,在不同頁,顯示不同字。
有的woff只有一個字哈哈。能夠想像他們在幹啥。有的woff我打不開,格式不規範,所以不方便把小的woff湊在一起。關鍵是碼位重疊的woff不能合併。
[備考]以後文字沒有錯誤。完全正確。 ![]()
文件上傳到了本站。見一樓
2 个赞
卻是。我裁圖的“並”字條,字頭沒顯示出來。說明它用的不是“並”的普通字體,而是配合紙書的:
數據不是馬馬虎虎弄出來的。
1 个赞
你等网页加载完了再点。。
1 个赞
奶牛:
你有一份文件待查收!即刻点击链接获取文件:文件下载-奶牛快传 Download |CowTransfer 或进入 cowtransfer.com 获取,在首页输入取件码:206667(24 小时内有效)
多谢佛兄!刚才可能就是没等网页加载完毕就开始点了,现在正在下。
不过我也就是好奇看看,hua大已经出手了,就准备坐享其成了 ![]()
1 个赞
1.txt 的词头是个啥?
<img width="" height="" src="/dictionary/u/cms/www/202008/211320118w5o.png">
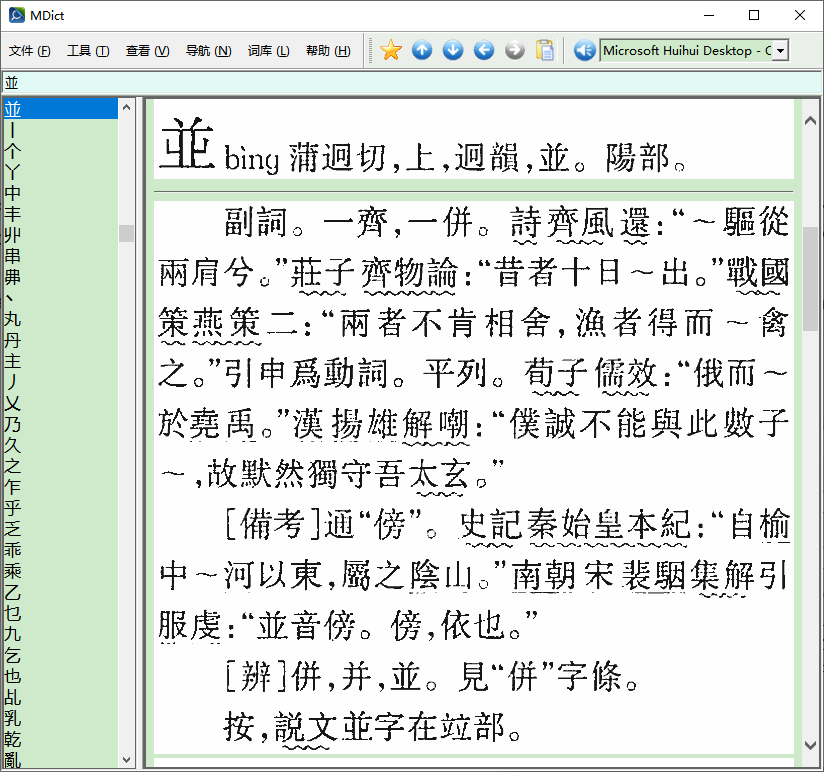
那些图片下载没有?恐怕需要登录才能下载吧?
应该就是上边我发的两个链接提到的字体加密,但很好奇hua老大没有字体文件怎么解的密……
那这些字可以自行添加上吗?不是私有区里面的。最好是符合纸质书吧,但是如果追求字形完全一致而导致查不到似乎也不好。
下面是类似词头 44 个,如果可以的话,还请补上词头,回复本贴,如果不合适的话,这 44 个我也不用加在 MDX 里面。
to_be_fixed.zip (10.8 KB)
籍合网 我早研究过一会。它的“本源”字体是提供下载的,你不细心吧。
加还是得加,要不就少了44条,还可能是常用字,但没必要还用私造字,检索也麻烦,下载图片也麻烦,正文不就用了“並”吗?
文字版的最大意义在于可搜索。
如果这个数据里头那些私造字都能转为中华大字典所用的那个字体就OK了,按说都是该网的。
之后如果有人要折腾为全宋体之类的,他们可以自行处理