sff34
273
让我感到困惑的是,就算是记事本,记事本里全是英文,它取出来的词也有不对的,这就奇怪了。
它取词的时候难道兵分两路,对任何一个词,一边HOOK,一边OCR,以先到者为准?但记事本里的简单英文也能HOOK这么慢?还有,OCR的准确度并不高,虽说欧路他们宣传好像说有百分之九十几,但实际上如果算上卡壳的时候,它这个准确度也就在80%多吧,像鸡肋一样。
我们日常取词,无非是office文本(主要是word和excel文本),acrobat pdf文本,网页文本,还有其它app的少量文本,这些可划文本,再加上操作界面上的一些不可划文本,如果识别准确度不能非常接近100%,这些商业软件的设计思路就有些匪夷所思了。OCR本来是锦上添花的功能,现在只能用OCR去弥补文本识别的残缺,当前这种取词生态,怎么看怎么不对劲。
1 个赞
sff34
274
或者,对于可划文本,正确的取词方式是先划取,划取不成再屏幕点选?
1 个赞
记事本,IE浏览器我这边测试纯文本内容是100%成功的,感觉不到任何延迟,不清楚欧路是怎么设置的,WordCaptureX有多种设置可选。Chrome里面的文本会失败,可能切换成了OCR识别,Office系列没有测试。打开图片识别里面英文单词的话会慢一些,准确度大家都差不多,错都一起错,可能我用的图片样本少了。
WordCaptureX官网有提供Demo,[链接],感兴趣可以自行尝试,有安装360的话,会有提示有远程线程正试图注入,风险自行考虑。
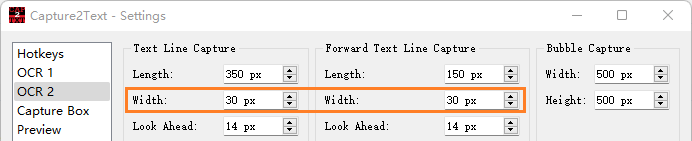
取词成功率与设置关系相当大,用顶楼的设置,对size 7-9取词成功率达80-90%!如果是大字体,要自己调整设置。
sff34
277
试了WordCaptureX Demo,结果很有意思。可能是我的记事本版本较新(Win11自带),而WordCaptureX版本较早,WordCaptureX无法对记事本进行Native Method取词,只能以FullText Method和OCR Method(OCR Method细分有两种方式我使用起来没发现有什么区别)。WordCaptureX 以OCR方式对记事本的英语单词取词极慢,经常卡壳取不到词,但反复试下来所有的英语单词都取到了,正确率100%!WordCaptureX对word、写字板、IE浏览器都可以进行Native Method取词,正确率100%!
对记事本取词,正确率最高的是WordCaptureX ,100%(小样本情况)。欧路不稳定,有时候经常出错,正确率在70%多,过一阵子又正常发挥,先前出错的词都能正常读取了,基本上能达到100%。GdOcrTool点选按一般字体配置的正确率始终在20~40%,换成较大字体配置后正确率能达到80%多,算上偶尔的fail和某些词的不响应,整体成功率应该也不低于80%。我的我的EXCEL是11号字,记事本是小四字体,不算什么较大字体,可能是我的显示比例为200%,较大字体是按显示比例为100%定义的吧(按物理分辨率而不是逻辑分辨率定义)?
记事本取词,WordCaptureX和欧路可能混合了FullText Method?记事本中如果参杂了些长的差不多的词,WordCaptureX有时就会混淆,正确率达不到100%,比如我的一行字前一个是appropriate,最后一个是approximately,结果WordCaptureX把appropriate识别成了appropriately,似乎把两个词捏在一起了。
1 个赞
sff34
278
嗯,根据我的经验,大字体似乎是指的物理分辨率,而不是逻辑分辨率。我的机子显示比例是200%,小四字体甚至11号就得用“较大”字体了。
sff34
280
是啊,单位是px,应该是物理像素,而不是逻辑像素吧。但是,字体的字号是逻辑的而不是物理的,所以,就算5号小字也可能成为“较大”字体。
我一开始把这个弄混了,以为11号字很小了,不应该用“较大”字体,结果怎么也弄不对。这个说清楚就行了。
artour
283
@Johnny_Van, chi_sim.traineddata我也放置了,现在中文不能正常OCR取词,英文正常取词,我的操作哪里有问题还是中文词典有问题?我在该分组中包含了新货字典和现代汉语词典第7版还有新世纪汉英大辞典
Chloey
286
64位两个分卷包都要下载吗?分卷包2下载后解压不了,文件错误
重新下载两个文件:
GoldenDict_OCR-All-in-1_x64 (497).7z.001
GoldenDict_OCR-All-in-1_x64 (497).7z.002
你需要WinRAR或者7-Zip,然后双击“GoldenDict_OCR-All-in-1_x64 (497).7z.001”, 打开压缩包,解压到你指定目录 (如 D:\):
Done!!!
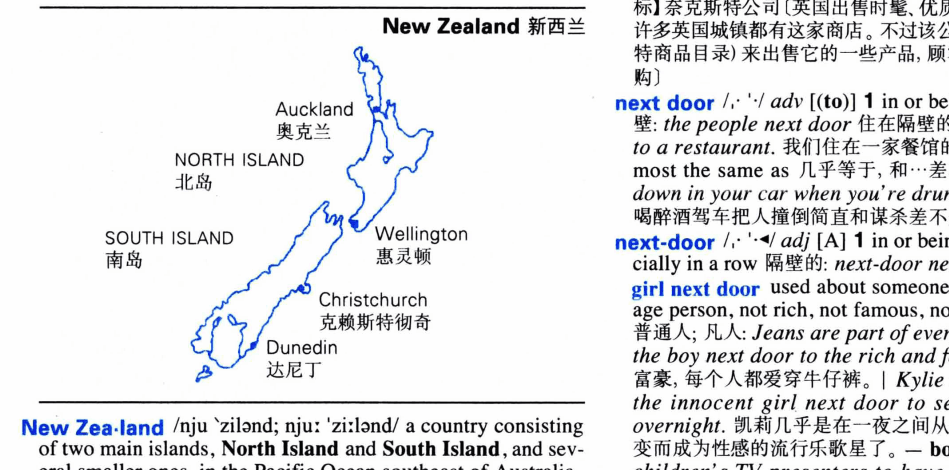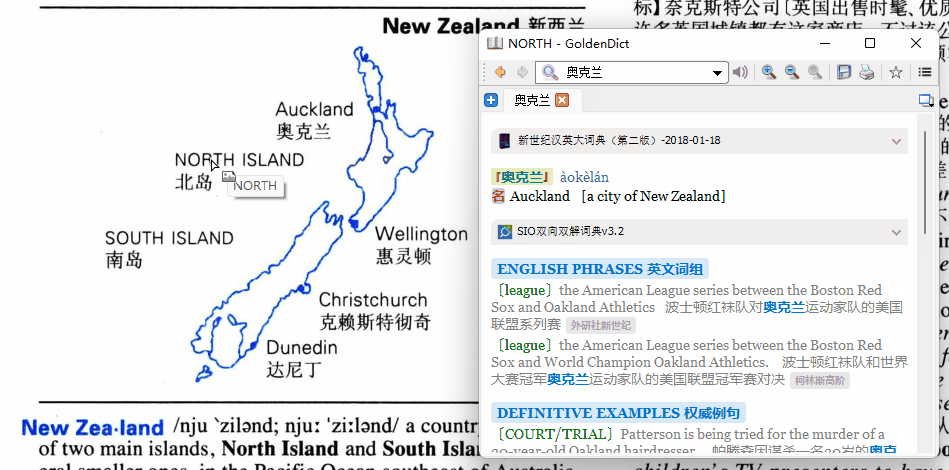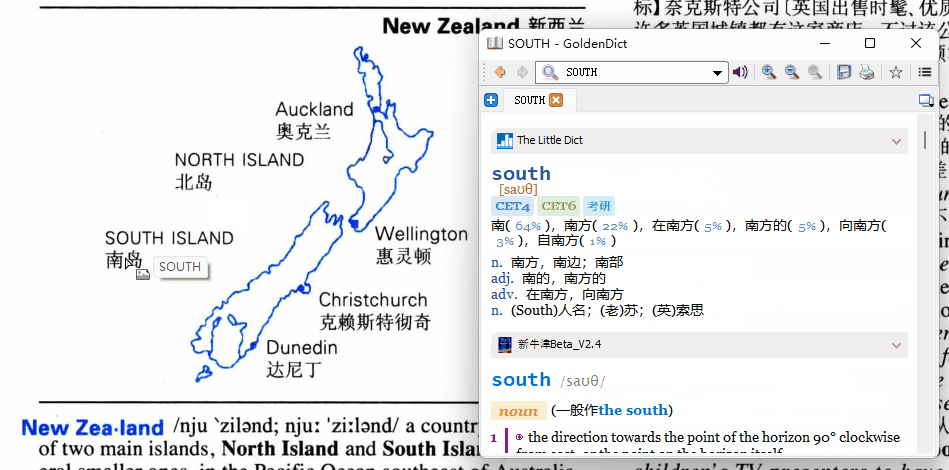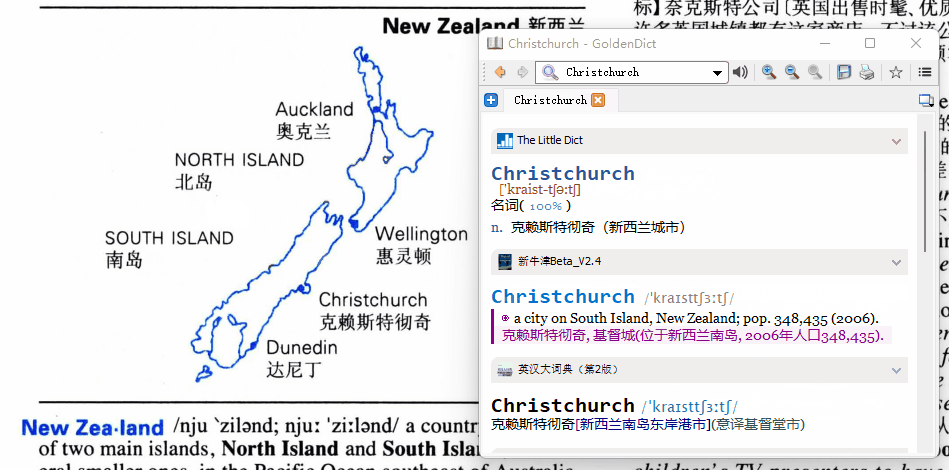
请教下,动图中直接点击图片中的单词就能取词也忒智能了点,按照我的理解,应该要手动框选住这个单词才能够取到啊,哪位大神能否解释下原理?谢谢啦
elisir
291
这个使用的OCR前端+截图软件(capture2text)不支持同时识别多种语言,只能单选。还不如后台的tesseract,那个可以同时支持多语言数据包,不如只能运行在命令行。在Linux下倒是好实现。
主要就几步:热键唤起截屏——截屏文件交tesseract进行OCR识别——识别结果复制板传递给goldendict,并删除临时文件。
可惜snipaste不支持截图传递给后续程序。
现有的这几种方案都不完美, [9.15]GoldenDict & 欧路 取词完美版(AHK) - GoldenDict - 掌上百科 - PDAWIKI - Powered by Discuz!这个quci脚本只能针对非图片的文字型,但不区分中英文。
这个GdOcrTool使用时操作最简便,可以对图片OCR,但采用的Capture2Text不支持同时识别中英文。得手动切换。
goldendict++带的OCR,得按快捷键激活,再拉框选择,但可同时支持中英文。如果它可以选择切换成右键加鼠标方式就方便些了。
quicker带的动作库也有支持goldendict的,只是也得先按快捷键再选择动作。
对于取词功能,一是同时支持中英文识别,不用来回切换。再就是快捷键激活精准拉框和按下CTRL+右键自动识别并存,对用户体验来说才更舒服。
如果有对win脚本编程熟悉的,倒是可以试试,我一个外行曾在Linux下基本完成,毕竟有通道。
刚发现quicker有个goldendict OCR查词的动作,可以设置快捷键,实现的功能基本与goldendict++一致,不过不需要安装除quicker之外的其它软件,就可以使官方goldendict实现OCR取词。除了不能双击取词翻译和按CTRL+右键直接取词翻译,挺好了。 GoldenDict OCR 查词 - 动作信息 - Quicker (getquicker.net)
elisir
292
楼主辛苦,感谢。
另,之前尝试过,貌似该脚本使用的capture2text不支持同时识别中英文,而原型tesseract是支持的。
在知乎发现有网友推荐了一个离线OCR软件Umi-OCR( Releases · hiroi-sora/Umi-OCR · GitHub),经测试,可以同时识别中英文等,软件可以设置为不弹出、复制识别结果、自定义快捷键。
个人认为挺适合跟goldendict搭配的,建议楼主试试。
2 个赞
johnye
293
这个真的挺好用,但遇到个问题,不知道,文本为什么不能拷贝,能点拨一下吗?谢谢!
这个也是用 PaddleOCR。
前面有人说中文识别不佳。