可能 WR 网站有反爬机制,我第一次爬的时候,requests 返回过50开头的状态码。
有可能的,你可以控制下速率。
我再跑跑试试。
发现问题了,状态码等于500时,网址后面有多余的字符串,得去掉后再请求。
wg04-15.py (1.7 KB)
2 个赞
我服务器 IP 应该被 wordreference 封了,现在全是 ERROR 还是要限制速率的。
我没有 ERROR 但还是漏,在试 N = 1
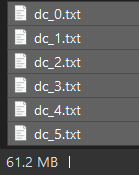
1 个赞
我这儿爬了一天,目前还正常。我用的移动4G网络,可能 IP 有变动过。
我是用 Windows 的 Ubuntu,不知道有没有关系
1 个赞
WSL1 肯定不行,WSL2 也许行。可以用 VirtualBox 装个 Ubuntu 虚拟机啊。
1 个赞
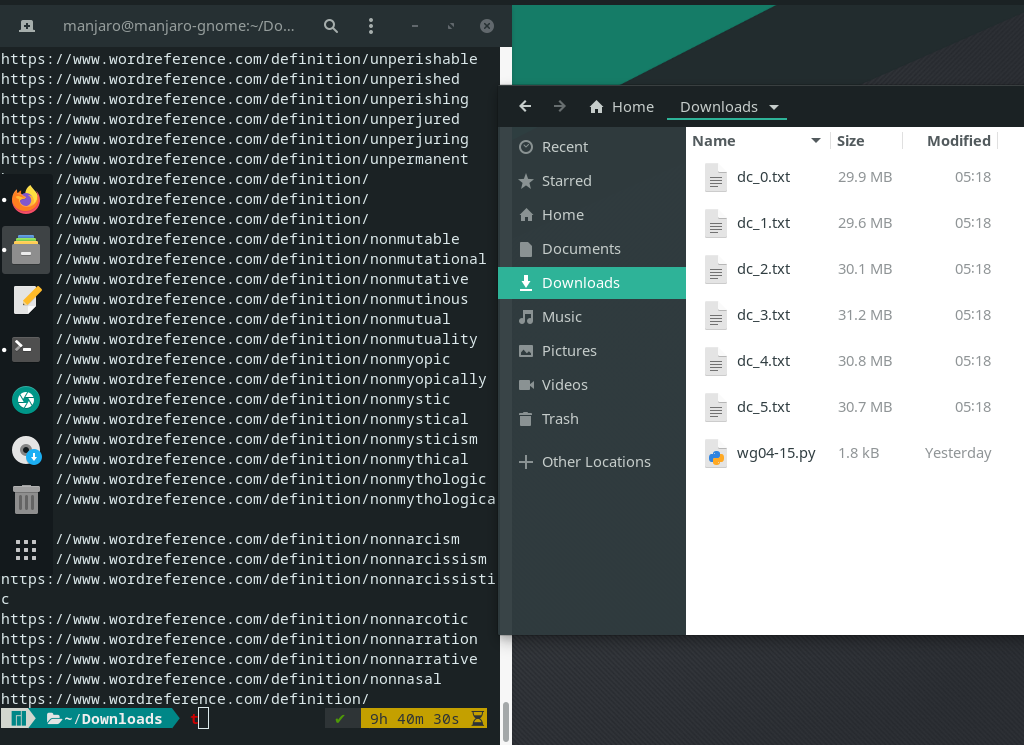
好的,有没有漏对比一下第二版就知道了
发现用 wget 下载 WR 网页,会被重定向到 Yahoo 网站,这可能就是 WR 的反爬措施。改了代码,禁了重定向,你最后再运行一次吧。
wg04-16.py (1.8 KB)
1 个赞
在跑了。。。
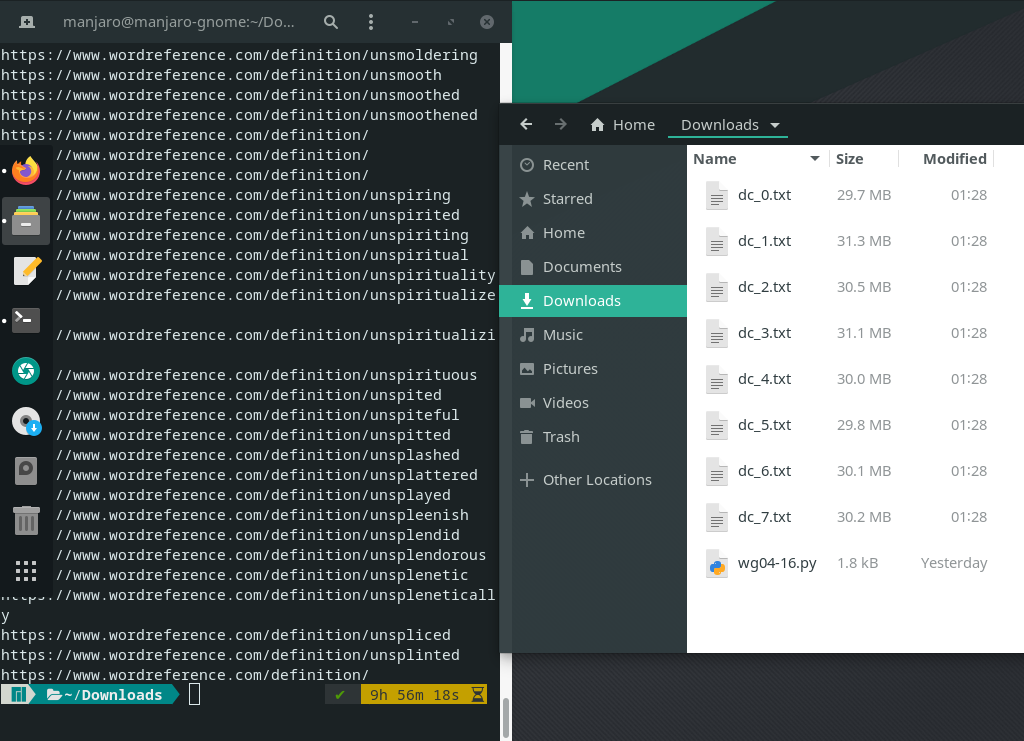
似乎没问题了,你可以找找看有没有词条缺失。
这个 Python 程序稍作修改,就可以爬很多词典网站,不管是有索引页还是附近词条区,只要从一个或多个网页开始,通过超链接能遍历全站的,都可以。基于 WordReference 的数据,已经有很多 MDX 了,但我感觉它们都缺词条,应该重做。完。
怎么不把发音文件一起爬下来… ![]()
2 个赞
在词条会被漏爬的时候爬发音毫无意义。God be with ye!
粗略看了下,好像挺全的
2 个赞
我也爬了一份 dc.txt,文件行数与你那份是否一致?
dc.7z (24.5 MB)
1 个赞