endnote:
再补充我的一点发现,关于词条显示顺序
词库词序排列的问题
解决方法 ,借鉴
尝试了一下,用MdxBuilder编译前,在第一个词条的词头前面再加上两行</>,即一共三行(如该词条前面只有两行</>则编译后消失),然后再编译txt为mdx。
一点感想:
1 个赞
御宅暴君:
HTML 规范貌似用 CR LF 换行
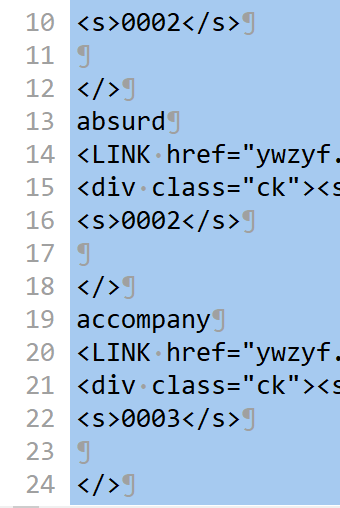
最近用MdxExport.3.6 解包一个mdx,其源代码里头有大量的软回车(即箭头向下符号),如下图
在emeditor中用正则\n搜索可以匹配两类换行符,但用\r或\r\n只能匹配硬回车、不能匹配软回车。
之前听说有些txt用其他开源工具编译失败,但用官方的工具可以成功编译。显然,MdxExport是可以无视软回车的,估计这种兼容处理是其容错性强的一个方面吧。
2 个赞
ubersoft:
利用正则删除
是的。既然解包了,肯定会顺手规范处理。
另一个可以成功编译的例子:mdx官方工具不仅可以无视软回车,硬回车也没问题。
现实中,很多小白并不会一开始就注意规范。mdx官方工具容错性强,是其广泛流行的一个重要因素。如果门槛过高过于严格,无疑会挫伤小白们参与的积极性;但过分降低门槛,就会出现目前mdx面临的一些窘境。
可见,规范和使用是鱼肉熊掌不可兼得的trade-off关系,需要在两者之间进行精细取舍权衡。毕竟,绝大多数老手是从小白一步一步成长起来的。
2 个赞
今天第一次遇到链接图片打包时编译器提示出错,把img文件夹从中文命名的文件夹中移出再编译再ok了。
有时候确实会吃一条,大部分情况都是正常的,不知道什么原因
Arlin
2020 年10 月 5 日 10:13
32
mdxbuilder 没有出现这个问题,这说的是lgmcw改良了排序的writemdict.py
https://www.pdawiki.com/forum/thread-36415-1-1.html
1 个赞
吃一条的原因可能是文本编码为utf-8有签名的原因,改为无签名应该就没问题。
2 个赞
ubersoft:
刚刚看了他的代码
lgmcw这个之前说是python 2代码。分号作为语句结束也可能是js。
我用的是zzzsleep的mdict-utils mdict 打包解包工具。
pip install mdict-utils
1 个赞
mdict-utils 的排序处理标点符号时,用的是python 自带的符号库,这个符号库里面的符号特别少,中文标点都没有匹配,不知道 mdxbuilder 的作者有没有处理中文标点。
这么说好像可以跟一些奇怪的mdx联系起来了。'都是全角的’,经过不同的打包工具的辗转之后,一些mdx缺失了这些’,造成阅读理解上的不便。貌似研究社新編英和活用大辞典有些mdx版本有相似问题。
即便只是一个打包工具,也是有很多坑的啊。幸如 Linus’s Law所言,Given enough eyeballs, all bugs are shallow。
大小写转换也有很多坑,unicode 码表上大小写的 i 各有24种,这些要不要处理,碰到小语种的词典,还涉及到变形问题,不是一句大小写敏感就能说清的。
1 个赞
last_idol:
碰到小语种的词典
就算是英语词典,有时候也要注意古英语的特殊字符。如OED
ubersoft:
非字母的不参与排序
没有深入研究过这个。
Arlin
2020 年12 月 12 日 09:52
45
我来更新 4 个。
No.1 转化词头当中的 HTML 符号实体 或者 HTML URL 编码
HTML URL 编码貌似 BeautifulSoup 当中的 html.parser 可以自动转化,但 HTML 符号实体不行,导致英文词库的词头经常得输入 & 才能查到 & 相关的词组。
建议使用单独的 html.parser 或者用文本编辑器批量替换。
No.2 自闭合标签
MDX 中常用的自闭合有 link img br source。
发现一些制作者会在 HTML 中将 script 错当成自闭合。今早刚发现 Thesaurus.com 2020 source 写错了,奈何文件已删除,请各位自行解包 mdx,将 < /source> 删掉。
No.3 转化链接中的标点 。
URL当中的 ? 需替换为 %3F(多平台)。
URL当中的 " 需替换为 %22。
BeautifulSoup 并不能保留 url 中的引号,或者将其转为 %22,而会把引号及内容分成属性和属性值。这种情况不是很常见。
假设:
<a>I love "U"</a>
处理成了:
<a href="entry://I love "U""> I love "U" </a>
经过解析后,会变成:
<a href="entry://I love" U=""> I love "U" </a>
▲ MDX 中,一些特殊字符采用 URL编码反倒不能正确跳转 (比如 ® )。
转标点符号这个问题,我在提取词组跳转到主词条时经常会忘记而费时返工。
No.4 去除空白行和首尾空白
获取标签内容作为词头或者 url 时,要去除前后空白。
空白行会导致无法打包,这时候需要用编辑器定位到提示的字节进行修改。
今儿个修了自己发现的 Free Dictionary of Idioms 2020 当中存在的以上问题。P 站更新链接点这里 ,目前里面的百度网盘链接还没有更新,奶牛链接里的是最新版 。
1 个赞
agno3
2020 年12 月 12 日 18:44
48
我觉得最大的缺点就是无论是mdx格式,还是mdict,以及mdxbuilder都没有一个详细的说明。
所以我完全不觉得没有说明文件和规范这一点会对入门者友善,反而会因此劝退许多人。因为入门者往往遇到困难就是在许多小的方面,可能是某个选项的作用,可能是带符号的词条,可能是小语种字符或音标,可能是代码版本。是改一下内容即可,还是根本就不支持,需要自己摸石头过河。
其实上面列出的许多问题,并不一定需要开源,只需要作者稍微作个说明即可。支持(或不支持)什么格式,最大长度多少,限制是什么。以及程序中的某个选项具体有什么意义,选取后会产生什么不同结果等等。
具体我举三个我到目前都没有弄清的问题。(我平时主要用ebwin,所以是在ebwin中使用自制mdx时遇到的问题,可能有点小众。)
1,a href跳转。
2,检索结果缺失(这一点不确定是ebwin的问题还是mdx的问题)
以a检索可以检索到所有词条。但是以ab检索的话,显示不出abd。以aac检索的话,只显示a a c,不显示aac。
3,mdxbuilder的index block size到底按什么确定。
12120
当index block size设为32k时,用1212可以检索出所有词条,但是用12120就会搜不到这个词。index block size设为64k时可以搜到部分,到128k时可以搜到全部。词头本身都是5位数字,真正词头也不长,不知道为什么就是这个结果。
以上的后两条可能是ebwin的问题,不过也是因为mdx没有一个技术性文档,所以ebwin的作者也无从确认一定是ebwin的问题并调试。所以即使我反馈给他结果也是石沉大海。
3 个赞
Vim
2020 年12 月 25 日 00:55
49
新发现一个:如果keyword中有英文的问号,那么GD将无法正确识别,它所识别的关键词不包括问号及问号之后的内容。
1 个赞
jns
2020 年12 月 25 日 04:43
50
用ABBYY时应该先修改一个合适的显示字体,有的字体对于大写I,小写l,数字1,以及大写O,数字0很难分别。
1 个赞