
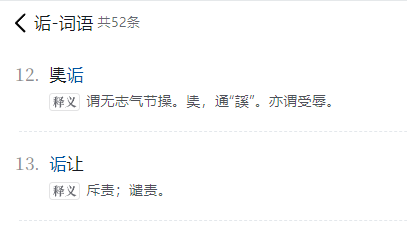
个人找到 61.1W 遗漏的 1731条,大部分非汉大词头
dyNew.txt (57.0 KB)
已有简体词头,但缺汉大繁体的 近7k
redirect.txt (113.1 KB)
谢谢,
弄好了分享给大家。
你这方面最棒,其实我一开始就准备复刻,只是笨拙。
再试一下,看看是不是好看一些。
你怎么也会汉语?
我们是程序猿群。。。
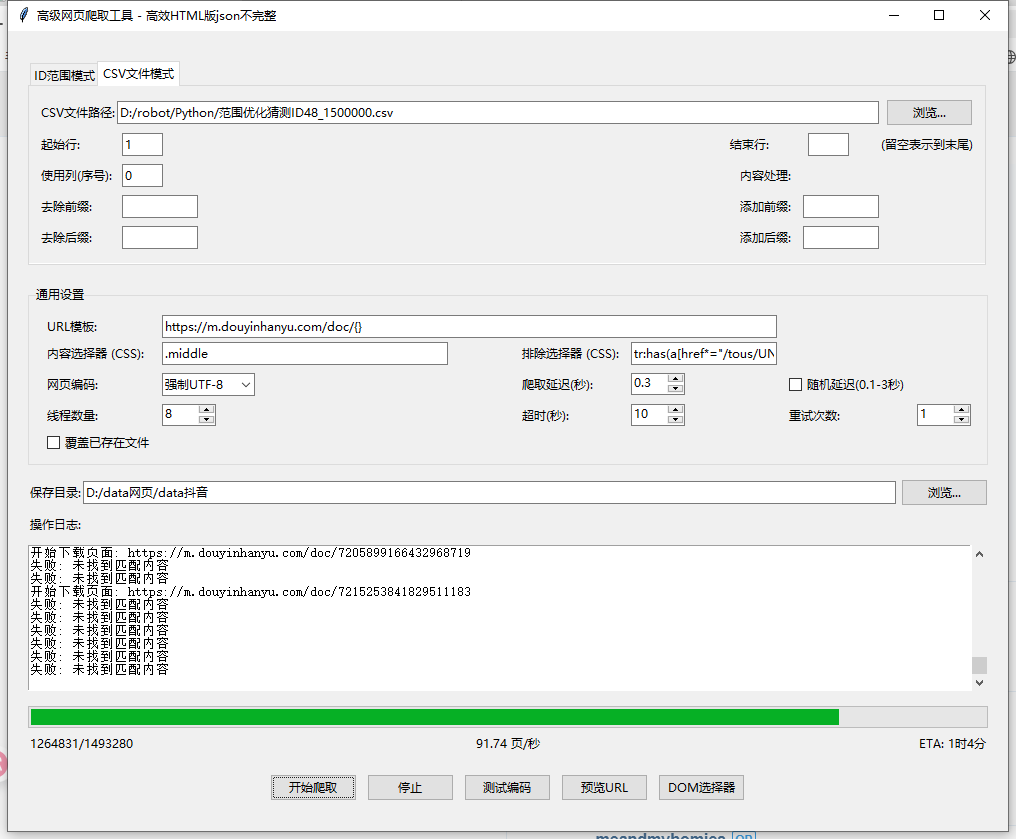
最新版本用leon的font可以显示,但是json里面的错别字就没法系统修正了。
你是遵循程序的员。
更新了0.mdd,像官网,好看一点点。
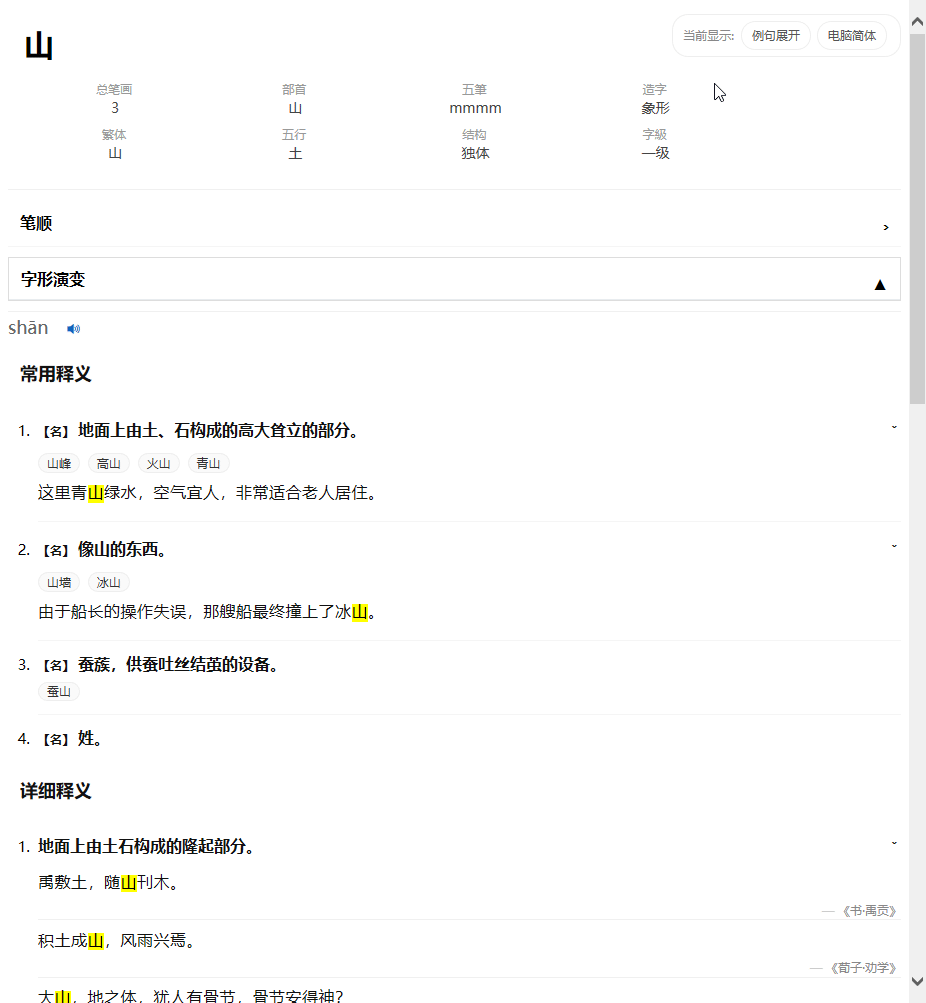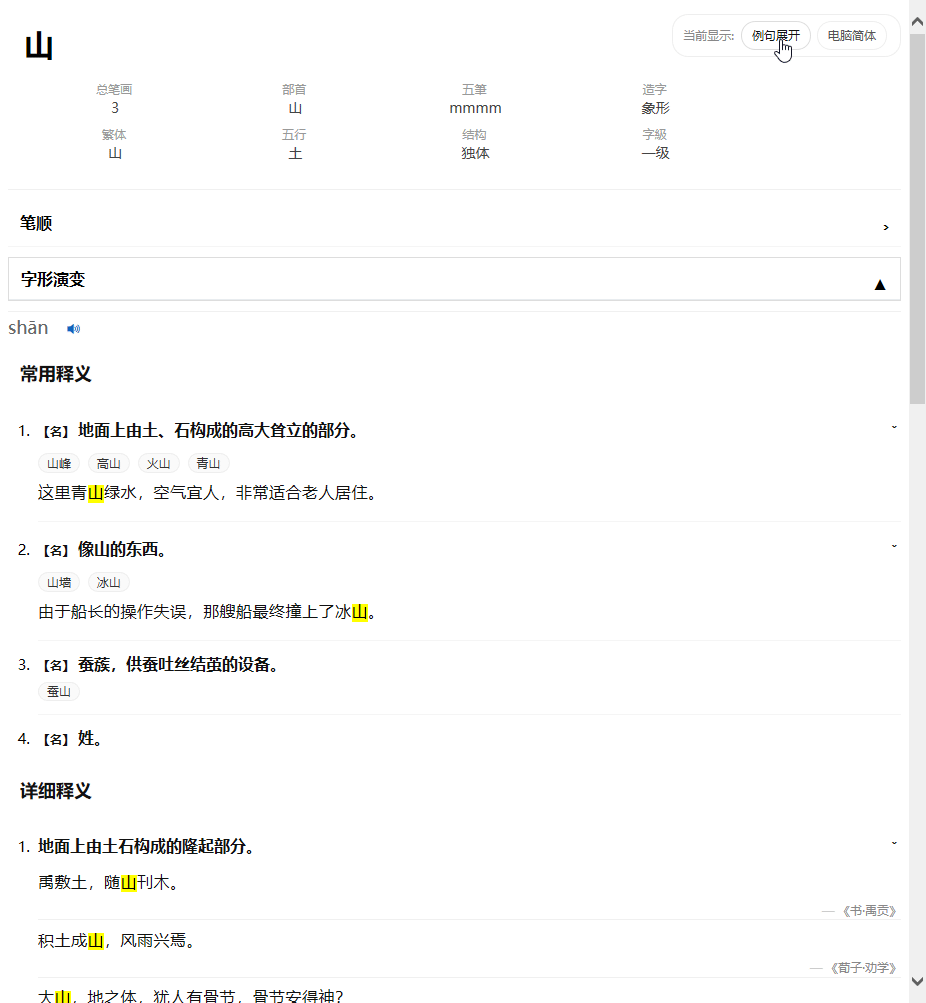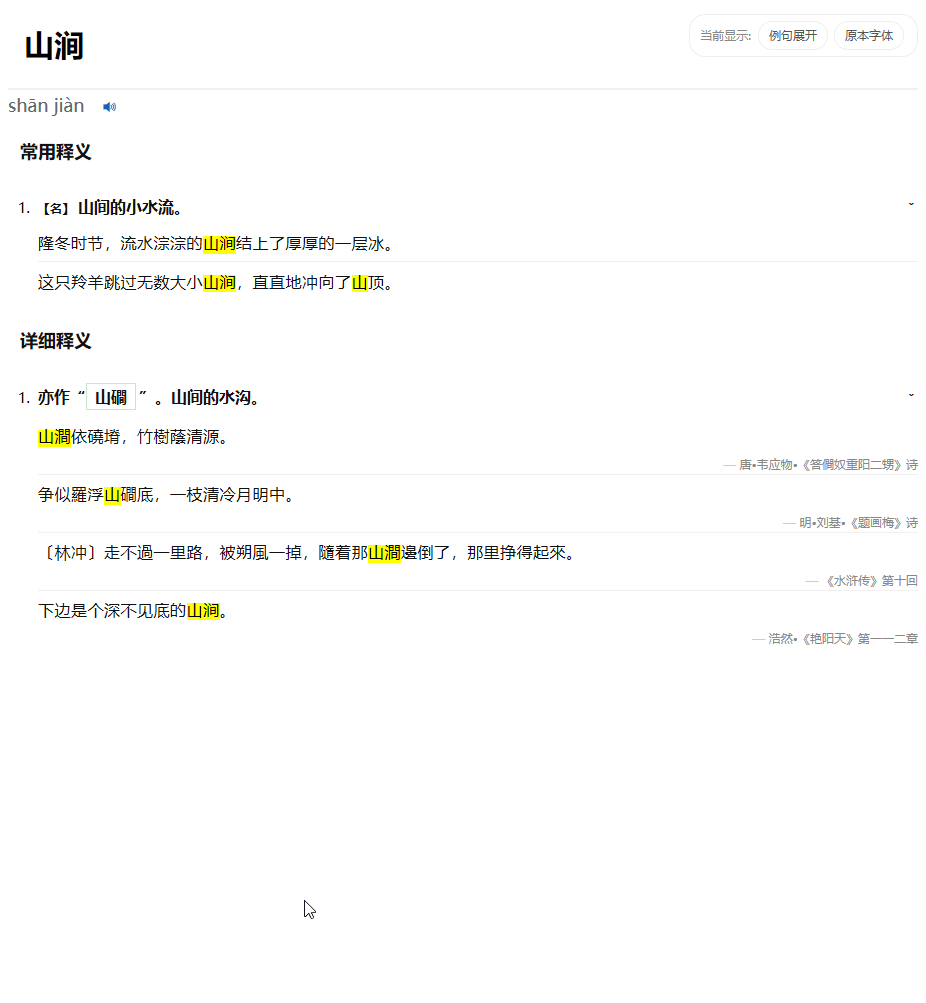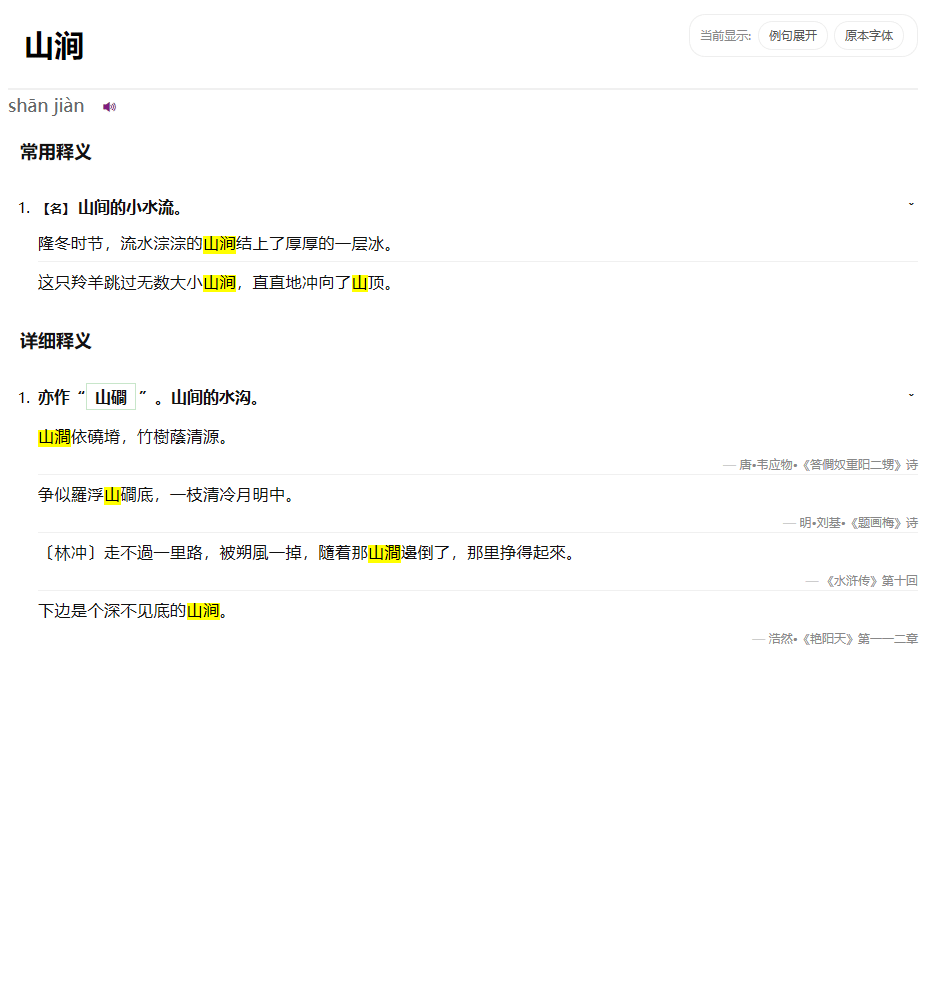
不过现在例句按钮跟着页面跑了
1 个赞

搞完了,61.67w,包含L大1700,以及所有(DocID,doc_id)
另外还有600的词必定存在,但是无法搜索,且想找的时候在列表中找不到
【汉语大词典】ID53.rar (5.7 MB)
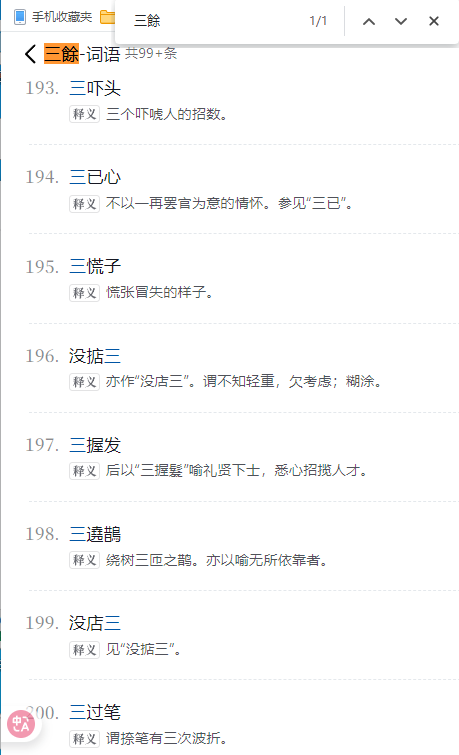
【汉语大词典】ID53.rar (5.7 MB)
ps,L大4小时找出1700个ID,要么撞库的词头比我全,例如“周公吐哺,天下归心”,我准备的123w词头不含该词头,要么chromedriver稳定性比我高,例如Unicode“𣏺”,我遍历过9.8w的Unicode16,中途有报错,未在意,要么就是基于ID的猜测算法概率比我高,我150w,7小时,产出500,较L大4小时产出1700, ![]() 告辞
告辞
因为html结构,tag和class都不一样,没法直接套用。除非用官网的js生成一样的html?
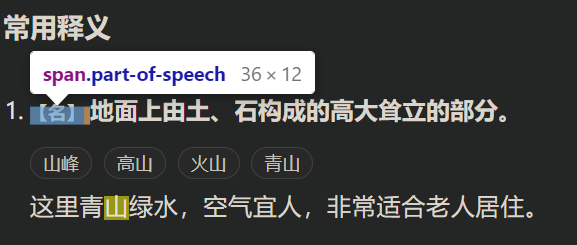
可以修补词性格式。
谢谢分享,如果完工了我加进去补最后一把。
我这边是收工了,
分享“一”的完整网页,包含css,js,json,
一.zip (1.3 MB)
1 个赞
怎么可能?一直都是给你id,加词头 ,csv.
没事,你的DocId去掉现有的和Leon的,一共4408新增的,赞。
