不大,没疯,不在乎,只看戏。只在乎善意好人。
是的,一旦成套了,就多快好省。
还是靠原始数据,以后刨根问底都得回归最原始数据,要不然类似于依靠(背后|搞人|当面)的传闻来发现真理,越传越坑。
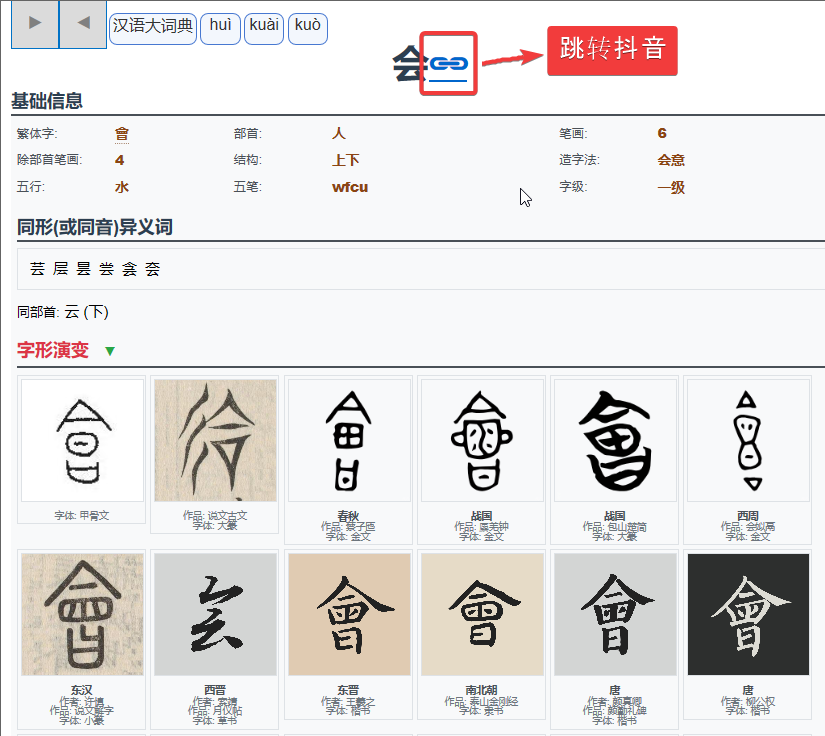
加了个链接《抖音汉语》网络版的版本,这样when in doubt, consult 抖音’s rendition。我还真不知道有这网页版本,居然和我自己闭门造车的雷同。
不大,没疯,不在乎,只看戏。只在乎善意好人。
是的,一旦成套了,就多快好省。
还是靠原始数据,以后刨根问底都得回归最原始数据,要不然类似于依靠(背后|搞人|当面)的传闻来发现真理,越传越坑。
加了个链接《抖音汉语》网络版的版本,这样when in doubt, consult 抖音’s rendition。我还真不知道有这网页版本,居然和我自己闭门造车的雷同。
更新了一下工作流程,
done
1从自带但未收录的相关词可以补词头387009-318536=68473
2从识典字典中可以补字头2.4w,之前预计的30590有部分重复,也有部分已在相关词中
3从汉大部首字表e (1).txt补 字词22个,其余为私人字,补不了,
ing
对比汉大总词目表(初步汇总).xlsx中的字词头,缺失但是可以补如“龍犧”
原装繁体xlsx,缺41776,xlsx转成简体,缺34397,先补简体,
下一步对比16w的国语词典,41w的汉语国学词典,71w的国学大师词典,9w的国学大师成语词典,缺失但是可以补如“划洋火”
不应该下载残缺的数据,抖音汉大的完整页面都没有。
一个页面一兆,字体,css,js,html,json,字体,css ,js,都是重复的,40多万的页面,400多g。
页面有已经完成的内容,何必处理json还搞js
那就没有繁简切换了
都在页面里面,删掉style, link, meta, script tags. except for that script with json data, when you save the file.
所以说还是只下json
NO!完整的内容已经在html里面,不仅仅在json里面!
我要重复几遍才懂???
站体积的是我列出来的tag,特别是style tag
ok,你的意思我懂了,现在我下json只是为了获取id,把id搞全之后要下什么你直接点菜。
体积只有1/10,你这是在省什么?

谢谢楼主的持续优化!
加dy链接基本不会增加什么新东西,原数据和dy数据应该是一致的。关键还是要补齐残缺的部分。
另外,提个建议,最好别这么大张旗鼓地提数据来源,不怕见光死?
楼主,上海辞书出版社《汉语大词典》.1.mdd 这个有什么用呢?3.89G,太占地方了。
楼主,上海辞书出版社《汉语大词典》.1.mdd里边有些什么图像?我在MDict正文页面这里按按那里戳戳,不出来图像啊?也没有什么图像按钮。我用的是苹果手机,望楼主教我。
图像的话应该是字体演变离线文件
发音的话应该是顾名思义。
上海辞书出版社《汉语大词典》.1.mdd使用中发现没有用处,已经删除了。