K大,你懂我!你这样处理,太和谐了。
其实,在17-20楼,我就提这个请求了。可惜,M大没采纳。K大,你解决了我的G点。
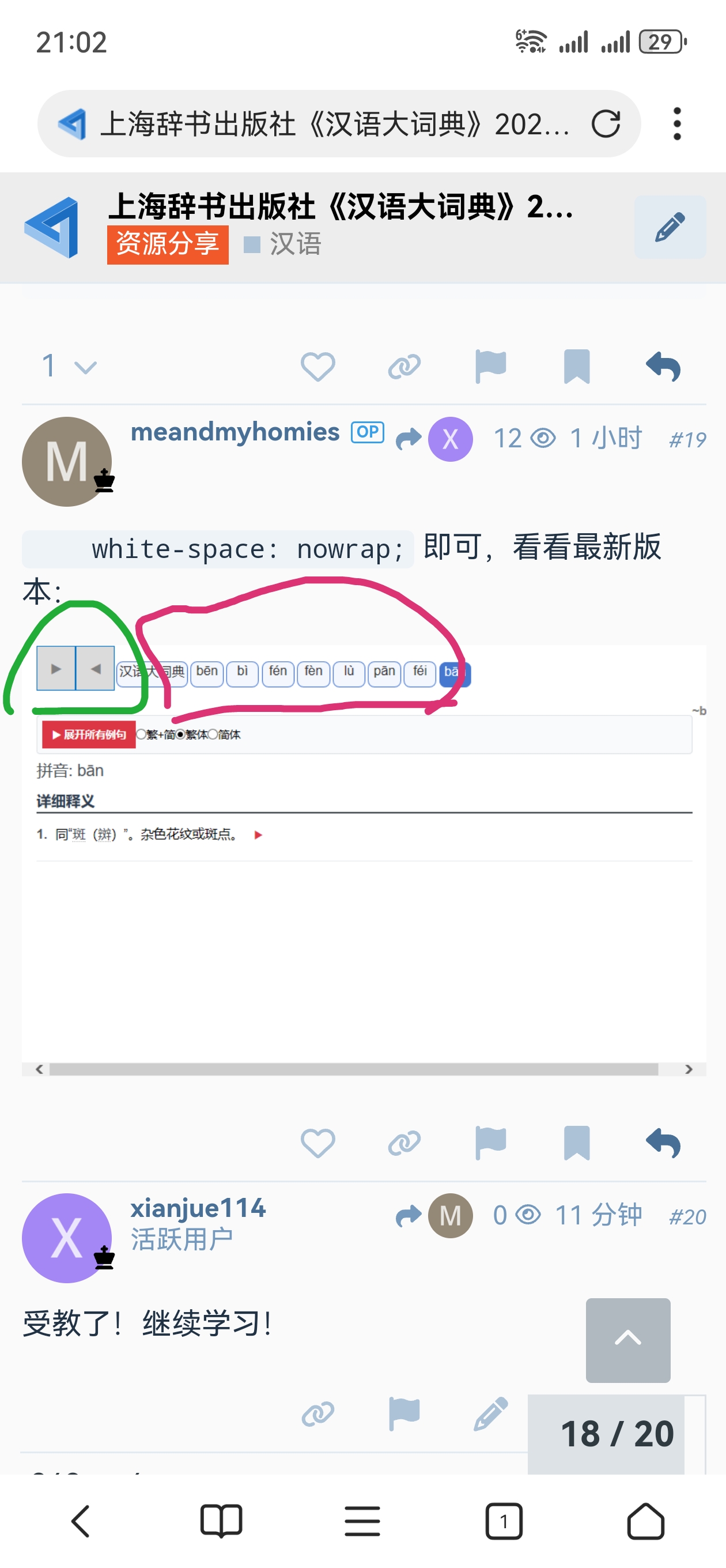
可以肯定他用了global search/replace,这是要命的。
不完全统计了23537个字中就有229个私有字,
全局仅对私有字添加括号,应该问题也不大吧
他用的是方括号【】还有backslash。
这些是不能全局替换的。
我搜【找了一个例子,
s的txt中{“type”:“text”,“text”:“有甲㒼胡,【】”,“node_id”:“”}
源数据{"type":"text","text":"有甲㒼胡,","node_id":""}
他胡搞的是加了很多\到json里面,还搞了很多前后不match的引号,不仅仅是【】。
懒得管了。少折腾。
可能用到私有字的和其他非私有字的应该分开来各做成一个mdx更好点,现在这样子有点乱的感觉。
可以了,HDC维护到现在,tab也有了,美化也有了,图片也排序了,
到时候直接上json数据,再搞
更新了,含有排序的图像,styling: 一个是原版,一个是新版(审美版).
Default原版, to allow toggles
我手头没有图片版,不知道是否也如此
对比一下其他几个版本就显而易见了,不过借你这个问题,我发现这个HDC缺一个跳转或者参见
“莅民”同“蒞民”
猜测纸质书应该是
《南齐书·武帝纪》:“經邦之寄,寔資莅民,守宰禄俸,蓋有恆准。”又:“莅民之職,一以小滿爲限。”
电子化之后,储存到数据库、json或HTML,加上各种css和正则处理,就呈现为各式各样的样貌
很多工具书前后照应不上也是有的,毕竟体量太大。就以辞海为例,辞海社长自己说的,《辞海》从第1版到第5版,均未对释文中的书证进行核查。每版出来之后,读者意见最多的也是书证中的讹误。
然后说后面组织人员进行核查了,但其实6版到现在的7版里,书证错误依然存在。
之前看到这个就有怀疑,难道只有辞海没核查书证吗,汉大也是大部头,该不会……
现在没有利益+钱的高难度的事,都没人干。
国家也不愿意拨款给字典行业。