解决了解决了感谢感谢哈哈哈,不过本站m大的汉语大字典图片没法点击打开,估计修改下css可以吧,怎么改请指教下
如果图片本身没有点击事件绑定,可以参考一下#1111 #1114 alexpeng的解决方案




我有空检查看看,字符列表文件有出现这些字吗?
应该有,用全宋体时:岠显示成了岡,岡显示成了岢,岢显示成了岣……
补充:应该说是从原字体提取字符时,部分字符的字形(形状线条)提取错了。希望没有误导楼主。
你试试单独把这几个字做成一个mdx来提取看有没有问题。
应该不是这几个字的问题。楼上提到的几个字“岠岡岢岣”,在mini字体中是连在一起的。
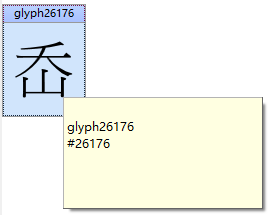
使用全宋体提取,“岙”的字码点和字形分离了。图一中“岚”的字码点其实是“岙”的。从“岙”到“岽”都错了一位。也就是说图中的“岚”是“岙”、“岛”是“岚”……最后一个“岽”有两个字码点,一个错误的一个正确的(5CBA, 5CBD)。“岙”的字形把字码点丢了(见下图二)。
后又用全宋体、屏显臻宋对“现规2”提取mini字体。(见下图三、四)
全宋体出现12个未用字形,屏显臻宋出现82个未用字形。这82个汉字的字码点与字形应该都匹配错了。查了几个字验证,确实如此。
看不出来有什么规律,应该不是哪个字的问题,似乎和字体与字典的搭配有关(纯属瞎猜……)



好,我有空测试一下
我在手机上试试几次都测试不出这个问题,果然是比较随机的问题,你或者看看转换出问题时有没有生成日志
果然有个日志,是这个吧。
log_2023-05-10.txt (8.4 KB)
日志里的错误不是字体精简器的,看来要花点时间调试了
忘记反馈了,抱歉大侠,现在阅读模式完美打开:-D
反馈【全文检索】功能里的一处问题,就是某些字下面有下划线,那么检索这些带有下划线的文本则无法识别到,详情在视频里。
你把“忽略HTML标记”的选项勾上试试
好像还是不行
看你的视频,在网页源代码里第一个字和第二个字之间应该有个空格的,你可以先看看里面的html源代码是怎么样的
解压成文字,确实文字之间有代码

只是不知道这样怎么检索
按道理说,这种应该是可以通过忽略HTML标记查到的,你方便把mdx文件发上来吗?我有空测试一下
mdx在网盘链接里链接:https://pan.baidu.com/s/1a3fJT9mL-iC_rD271QIfMA?pwd=86r1
提取码:86r1
请问阅读模式下怎么能回到主页面啊?我只会用系统自带的滑动退后,但有时在阅读模式翻了很多页,就要划很多下,而且也会丢失阅读位置。倒是可以退出软件后重新启动