哈哈,我搞错了。谢谢你的耐心解答。

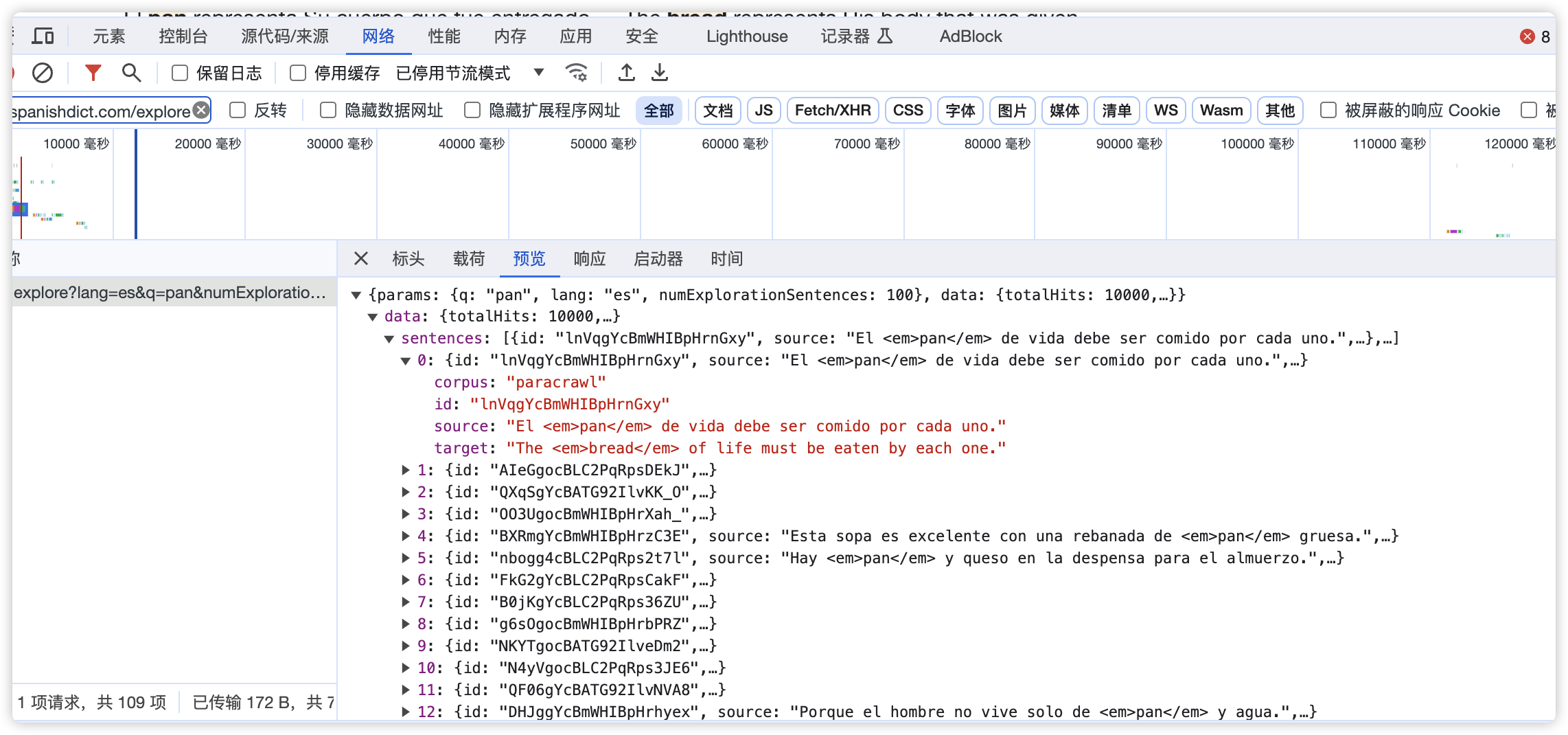
chrome分析api请求在哪里找到?是不是先获取到json然后转化为html文本内容存到example标签里的?可能是我想的太复杂了吧……
没有更便捷的方法了。找个模板引擎比如jinja2之类的,把json按照原始的样式拼接成html,然后再插入到网页文本里的对应位置。
模板引擎jinja2我整的不知道怎么做,问GPT是答非所问,可能是我不太会表述吧。
另外,每次抓取一次需要花5秒钟,如果想要提高速度会不会被识别爬虫?那怎么做呢?
main.py
# -*- coding: utf-8 -*-
import requests
from os import path
import time
for i, line in enumerate(open("address.txt")):
filename = 'output/'+str(i) + ".html" # 保存的文件名
# 检查文件是否存在,存在跳过
if path.exists(filename):
continue
cookies = {
'sd_inner_height': '405',
'sd_test_group': '64',
'sd_session_group2': '12',
'sd_locked_widget_views': '%7B%22views%22%3A%202%2C%20%22expires%22%3A%20%222023-12-10T00%3A51%3A49.651Z%22%7D',
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Sec-Fetch-Site': 'same-origin',
# 'Cookie': 'sd_inner_height=405; sd_test_group=64; sd_session_group2=12; sd_locked_widget_views=%7B%22views%22%3A%202%2C%20%22expires%22%3A%20%222023-12-10T00%3A51%3A49.651Z%22%7D',
'Sec-Fetch-Dest': 'document',
'Accept-Language': 'zh-CN,zh-Hans;q=0.9',
'Sec-Fetch-Mode': 'navigate',
'Host': 'www.spanishdict.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.2 Safari/605.1.15',
'Referer': 'https://www.spanishdict.com/translate/chino',
# 'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
}
response = requests.get(line, cookies=cookies, headers=headers)
# 打印文本行,去除前后空格换行,http状态码,响应内容长度
print(i, line.strip(), response.status_code, len(
response.text))
# 发现会返回空文件,检查响应内容长度,大于1000,再保存文件
if len(response.text) > 1000 and response.status_code == 200:
with open(filename, "w", encoding="utf-8") as f:
f.write(response.text)
# 等待5秒
time.sleep(5)
是不是先抓取整个网页,然后另一个文件将html进行处理内容存储为txt文本?
beautiful_html.py
import os
from bs4 import BeautifulSoup
# 输入文件夹路径
input_folder = "output"
# 输出文件夹路径
output_folder = "output_new"
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 遍历文件夹中的HTML文件
for filename in os.listdir(input_folder):
if filename.endswith(".html"):
# 构建输入文件的完整路径
input_file_path = os.path.join(input_folder, filename)
# 读取HTML文件内容
with open(input_file_path, "r", encoding="utf-8") as file:
html_content = file.read()
# 使用Beautiful Soup解析HTML
soup = BeautifulSoup(html_content, "html.parser")
# 找到#main-container-video元素
main_container_video = soup.select_one("#main-container-video")
# 如果找到了#main-container-video元素
if main_container_video:
# 保留指定的子元素,删除其他子元素
for index, child in enumerate(main_container_video.find_all(recursive=False)):
if index + 1 not in [1, 5, 7, 8]:
child.decompose()
# 移除<svg>标签及其内容
for svg_tag in main_container_video.find_all("svg"):
svg_tag.extract()
# 获取#main-container-video的内容,包含HTML标签
main_container_video_content = str(main_container_video)
# 构建输出文件的完整路径,将后缀改为txt
output_file_path = os.path.join(output_folder, filename.replace(".html", ".txt"))
# 将内容保存到输出文件
with open(output_file_path, "w", encoding="utf-8") as output_file:
output_file.write(main_container_video_content)
那么,如何将jinja2模板引擎在哪一个文件进行处理?
可以改成3秒试试,谨慎点比较好,被屏蔽IP了就惨了。
都可以,可以先抓取网页,保存成001.html,再抓取json保存成001.json,所有词条抓取完后再来处理jinja2。
jinja2的处理流程是,先创建jinja2模板,再用python内置的json模块读取001.json,用json填充jinja2模板,生成例句的html字符串后,读取001.html文本,直接用前面生成的字符串替换001.html的空白例句位置的文本,然后保存001.html文件。
上面只是简单描述,很多细节还要找下文章教程参考,jinja2+json的教程可以参考下这里:
如果十万个单词3秒钟爬一次,那么需要连续三四天才能爬完,有点长。有没有更好的办法?
间隔时间是没有强制说要多少的,可以改成0.5秒看看。更好的方法就是买IP代理池,挂代理跑爬虫了,这是更复杂的话题了。
动态网站爬取被识别概率低一些吧?我尝试了一下,为什么是Timeout?
address.txt内容如下:
como
que
de una
niña
bebe
¿O me equivoco?
python源代码
# -*- coding: utf-8 -*-
import os.path
from os import path
import time
from playwright.sync_api import sync_playwright
from playwright.sync_api import TimeoutError
with sync_playwright() as p:
browser = p.chromium.launch()
# 模拟高清屏,2为缩放倍率,爬取网页可以用1,制作高清的图片词典可以用2
context = browser.new_context(device_scale_factor=2)
page = context.new_page()
for i, line in enumerate(open("address.txt")):
filename = line + ".html" # 保存的文件名
line = line.strip() # 移除文本行前后空格
# 检查文件是否存在,存在跳过
if path.exists(filename):
continue
try:
# 设置50秒超时,默认是30秒,超时就跳过,下次再处理。
page.set_default_navigation_timeout(50000)
page.goto('https://www.spanishdict.com/translate/'+line)
except TimeoutError:
# 打印文本行,去除前后空格换行,错误提示
print('current: ', i, line, '[timeout]')
continue
# 等待2秒,确保动态网页也可以爬取
time.sleep(2)
# 读取网页内容
content = page.content()
# 打印文本行,去除前后空格换行,响应内容长度
print('current: ', i, line, len(content))
# 保存网页到文件
with open(filename, "w") as f:
f.write(content)
# 保存截图,方便查看效果
page.screenshot(path="screenshot.png", full_page=True)
# 保存指定选择器的截图,如果网页加密,可以方便制作图片词典
# elem = page.query_selector(".mtb")
# elem.screenshot(path="mtb.png")
browser.close()
源代码:
# -*- coding: utf-8 -*-
# 爬数据存到原html
import requests
from os import path
import time
from playwright.sync_api import sync_playwright
for i, line in enumerate(open("Spanish Dictionary Site Map/Spanish/A.txt")):
filename = 'output/' + line + ".html" # 保存的文件名
# 检查文件是否存在,存在跳过
if path.exists(filename):
continue
cookies = {
'sd_inner_height': '405',
'sd_test_group': '64',
'sd_session_group2': '12',
'sd_locked_widget_views': '%7B%22views%22%3A%202%2C%20%22expires%22%3A%20%222023-12-10T00%3A51%3A49.651Z%22%7D',
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Sec-Fetch-Site': 'same-origin',
# 'Cookie': 'sd_inner_height=405; sd_test_group=64; sd_session_group2=12; sd_locked_widget_views=%7B%22views%22%3A%202%2C%20%22expires%22%3A%20%222023-12-10T00%3A51%3A49.651Z%22%7D',
'Sec-Fetch-Dest': 'document',
'Accept-Language': 'zh-CN,zh-Hans;q=0.9',
'Sec-Fetch-Mode': 'navigate',
'Host': 'www.spanishdict.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.2 Safari/605.1.15',
'Referer': 'https://www.spanishdict.com/translate/chino',
# 'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
}
response = requests.get('https://www.spanishdict.com/translate/' + line, cookies=cookies, headers=headers)
# 打印文本行,去除前后空格换行,http状态码,响应内容长度
print(i, line.strip(), response.status_code, len(
response.text))
# 发现会返回空文件,检查响应内容长度,大于1000,再保存文件
if len(response.text) > 1000 and response.status_code == 200:
with open(filename, "w", encoding="utf-8") as f:
f.write(response.text)
# 等待5秒
time.sleep(1)
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/urllib3/connectionpool.py", line 467, in _make_request
self._validate_conn(conn)
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/urllib3/connectionpool.py", line 1092, in _validate_conn
conn.connect()
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/urllib3/connection.py", line 642, in connect
sock_and_verified = _ssl_wrap_socket_and_match_hostname(
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/urllib3/connection.py", line 783, in _ssl_wrap_socket_and_match_hostname
ssl_sock = ssl_wrap_socket(
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/urllib3/util/ssl_.py", line 469, in ssl_wrap_socket
ssl_sock = _ssl_wrap_socket_impl(sock, context, tls_in_tls, server_hostname)
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/urllib3/util/ssl_.py", line 513, in _ssl_wrap_socket_impl
return ssl_context.wrap_socket(sock, server_hostname=server_hostname)
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/ssl.py", line 501, in wrap_socket
return self.sslsocket_class._create(
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/ssl.py", line 1041, in _create
self.do_handshake()
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/ssl.py", line 1310, in do_handshake
self._sslobj.do_handshake()
ssl.SSLEOFError: EOF occurred in violation of protocol (_ssl.c:1129)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/urllib3/connectionpool.py", line 790, in urlopen
response = self._make_request(
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/urllib3/connectionpool.py", line 491, in _make_request
raise new_e
urllib3.exceptions.SSLError: EOF occurred in violation of protocol (_ssl.c:1129)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/requests/adapters.py", line 486, in send
resp = conn.urlopen(
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/urllib3/connectionpool.py", line 844, in urlopen
retries = retries.increment(
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/urllib3/util/retry.py", line 515, in increment
raise MaxRetryError(_pool, url, reason) from reason # type: ignore[arg-type]
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='www.spanishdict.com', port=443): Max retries exceeded with url: /translate/Anoche%20nos%20sentimos%20alegres.%20Mis%20primos%0A (Caused by SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:1129)')))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/howiema/Documents/Code/PycharmProjects/mdict/main.py", line 44, in <module>
response = requests.get('https://www.spanishdict.com/translate/' + line, cookies=cookies, headers=headers)
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/requests/api.py", line 73, in get
return request("get", url, params=params, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/requests/api.py", line 59, in request
return session.request(method=method, url=url, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/requests/sessions.py", line 589, in request
resp = self.send(prep, **send_kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/requests/sessions.py", line 703, in send
r = adapter.send(request, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/requests/adapters.py", line 517, in send
raise SSLError(e, request=request)
requests.exceptions.SSLError: HTTPSConnectionPool(host='www.spanishdict.com', port=443): Max retries exceeded with url: /translate/Anoche%20nos%20sentimos%20alegres.%20Mis%20primos%0A (Caused by SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:1129)')))
这个报错的原因是什么?
另外,为什么输出每一个文件的名称结尾都带问号?
timeout是网络问题。
如果用了代理的话,应该是代理的问题,可以关掉代理,或者尝试降低urllib的版本:
python3 -m pip install urllib3==1.25.11
检查下读取到line是否有问号,最好直接用文本行号做为文件名,因为有可能词条包含非法字符,无法保存成文件名:
filename = 'output/'+str(i) + ".html"
这个报错,不是IP被屏蔽了,和之前的错误一样,我提到的方案你有没有尝试?
用VPN跑,肯定没有网络问题。其他代理需要正确的配置,脚本才能使用代理的网络,很难确定问题出在哪里。
hmmmm 我的魔法流量有限制 ![]()
是不是一个一个爬取整个网站,然后进行html批量处理?
是的,所有爬完,最后再处理网页。
html文件都抓取好了,那么如何批量处理呢?
我尝试过方法
import os
from bs4 import BeautifulSoup
# 输入文件夹路径
input_folder = "output"
# 输出文件夹路径
output_folder = "output_new"
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 遍历文件夹中的HTML文件
for filename in os.listdir(input_folder):
if filename.endswith(".html"):
# 构建输入文件的完整路径
input_file_path = os.path.join(input_folder, filename)
# 读取HTML文件内容
with open(input_file_path, "r", encoding="utf-8") as file:
html_content = file.read()
# 使用Beautiful Soup解析HTML
soup = BeautifulSoup(html_content, "html.parser")
# 找到#root元素
root_element = soup.select_one("#root")
# 如果找到了#root元素
if root_element:
# 删除#root同级和上级的元素
siblings = root_element.find_parents() + root_element.find_all_next() + root_element.find_all_previous()
for sibling in siblings:
sibling.decompose()
# 保留#root下的特定子元素
valid_tags = [
'div.v0FDaSYd',
'div:nth-child(5) > div > div.jjO2Nc7v > div.mfFXfdZK',
'div:nth-child(5) > div > div.Vx8ajdmK > div',
'div.XJmTj2oN',
'div:nth-child(8) > div.MMRp6QwT',
'div:nth-child(8) > div:nth-child(4)',
'div:nth-child(8) > table'
]
for tag in valid_tags:
# 移除除了指定标签之外的所有子元素
for child in root_element.find_all(recursive=False):
try:
if not child.is_selector(tag):
child.decompose()
except AttributeError:
pass # 避免处理NoneType
try:
# 获取#root的内容,包含HTML标签
root_content = str(root_element)
except TypeError:
root_content = "" # 避免处理NoneType
# 构建输出文件的完整路径,将后缀改为txt
output_file_path = os.path.join(output_folder, filename.replace(".html", ".txt"))
# 将内容保存到输出文件
with open(output_file_path, "w", encoding="utf-8") as output_file:
output_file.write(root_content)
这不行,为什么?
output.zip (367.7 KB)
这段代码把 root_element 本身都删掉了,不需要这么做。直接 str(root_element)就不包含同级和父级元素了。
Traceback (most recent call last):
File "/Users/howiema/Documents/Code/PycharmProjects/mdict/beautiful_html.py", line 48, in <module>
if not child.is_selector(tag):
TypeError: 'NoneType' object is not callable
进程已结束,退出代码为 1
这个报错的问题怎么解决?
改成这样
import os
from bs4 import BeautifulSoup
# 输入文件夹路径
input_folder = "output"
# 输出文件夹路径
output_folder = "output_new"
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 遍历文件夹中的HTML文件
for filename in os.listdir(input_folder):
if filename.endswith(".html"):
# 构建输入文件的完整路径
input_file_path = os.path.join(input_folder, filename)
# 读取HTML文件内容
with open(input_file_path, "r", encoding="utf-8") as file:
html_content = file.read()
# 使用Beautiful Soup解析HTML
soup = BeautifulSoup(html_content, "html.parser")
# 找到#root元素
root_element = soup.select_one("#root")
# 如果找到了#root元素
if root_element:
# 保留#root下的特定子元素
valid_tags = [
'div.v0FDaSYd',
'div:nth-child(5) > div > div.jjO2Nc7v > div.mfFXfdZK',
'div:nth-child(5) > div > div.Vx8ajdmK > div',
'div.XJmTj2oN',
'div:nth-child(8) > div.MMRp6QwT',
'div:nth-child(8) > div:nth-child(4)',
'div:nth-child(8) > table'
]
for child in root_element.find_all(recursive=False):
try:
# 如果标签不在有效标签列表中,移除
if child.name not in valid_tags:
child.decompose()
except AttributeError:
pass # 避免处理NoneType
try:
# 获取#root的内容,包含HTML标签
root_content = str(root_element)
except TypeError:
root_content = "" # 避免处理NoneType
# 构建输出文件的完整路径,将后缀改为txt
output_file_path = os.path.join(output_folder, filename.replace(".html", ".txt"))
# 将内容保存到输出文件
with open(output_file_path, "w", encoding="utf-8") as output_file:
output_file.write(root_content)
输出结果不对,怎么改代码呢?
这种方式保留元素是不行的,后面的代码也是错误的。你只能删除你不要的,直接找到你不要的元素,然后删掉。