哦哦哦,看来自己不能画蛇添足吧。只能老马工具导出原始结果?
mdd命名暂且不谈,mdx内的后缀更改还是不理解。mdx别的部分都是完全正常。
图片命名其实不需要自己干预的(不然要这垃圾程序干嘛是吧),喂给程序的图片就书本的原始顺序就行,比如从0001.jpg(封面)到 8888.jpg(封底)。
这一点我发现在教程里漏了没写,难怪![]() ,我完善一下
,我完善一下

辛苦楼主了,感谢您耐心解答。我最开始也是按照顺序排列的,只是出来的结果还是乱序。我发图片来看一下:
-
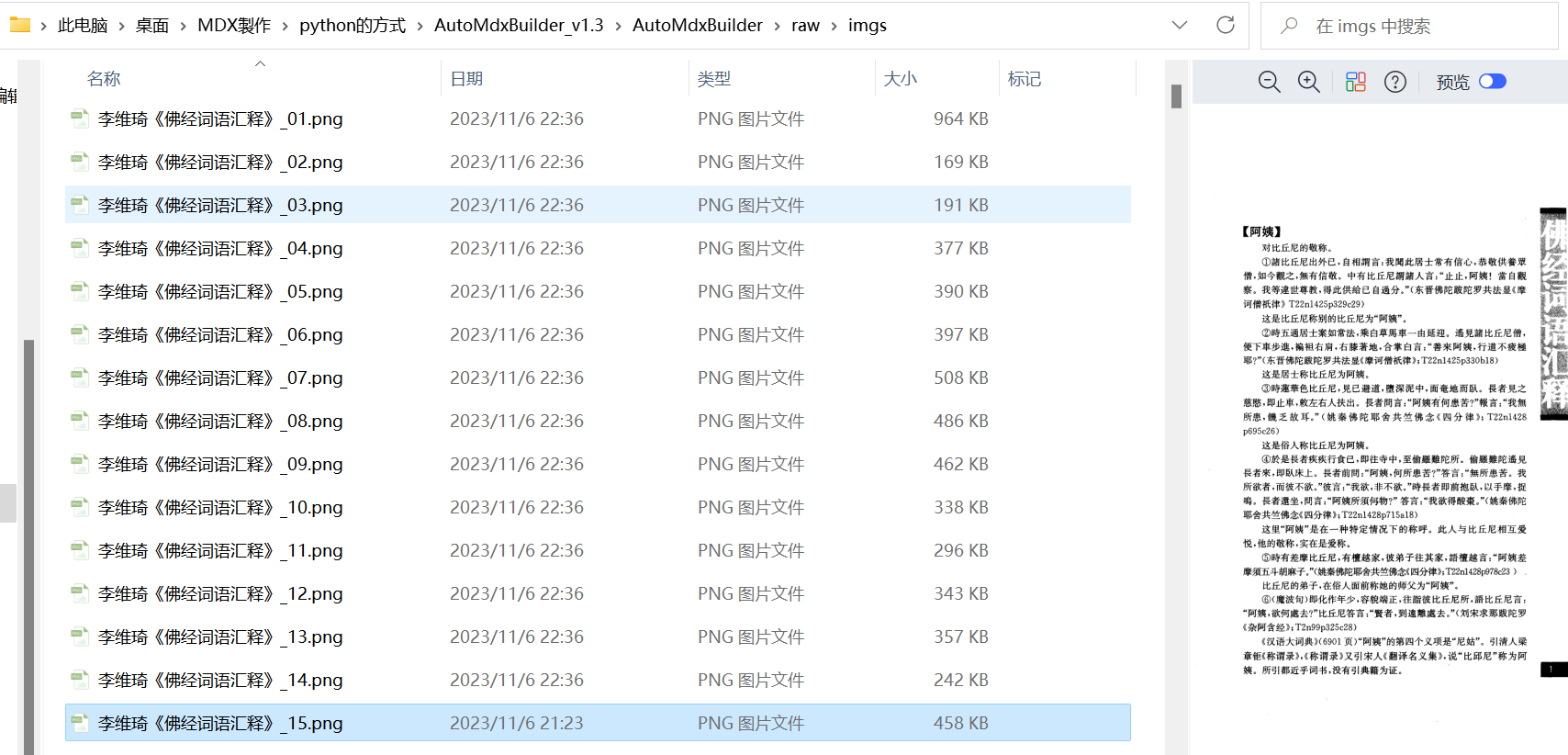
这是原始的图片档,可以看到第15页才是词头
-
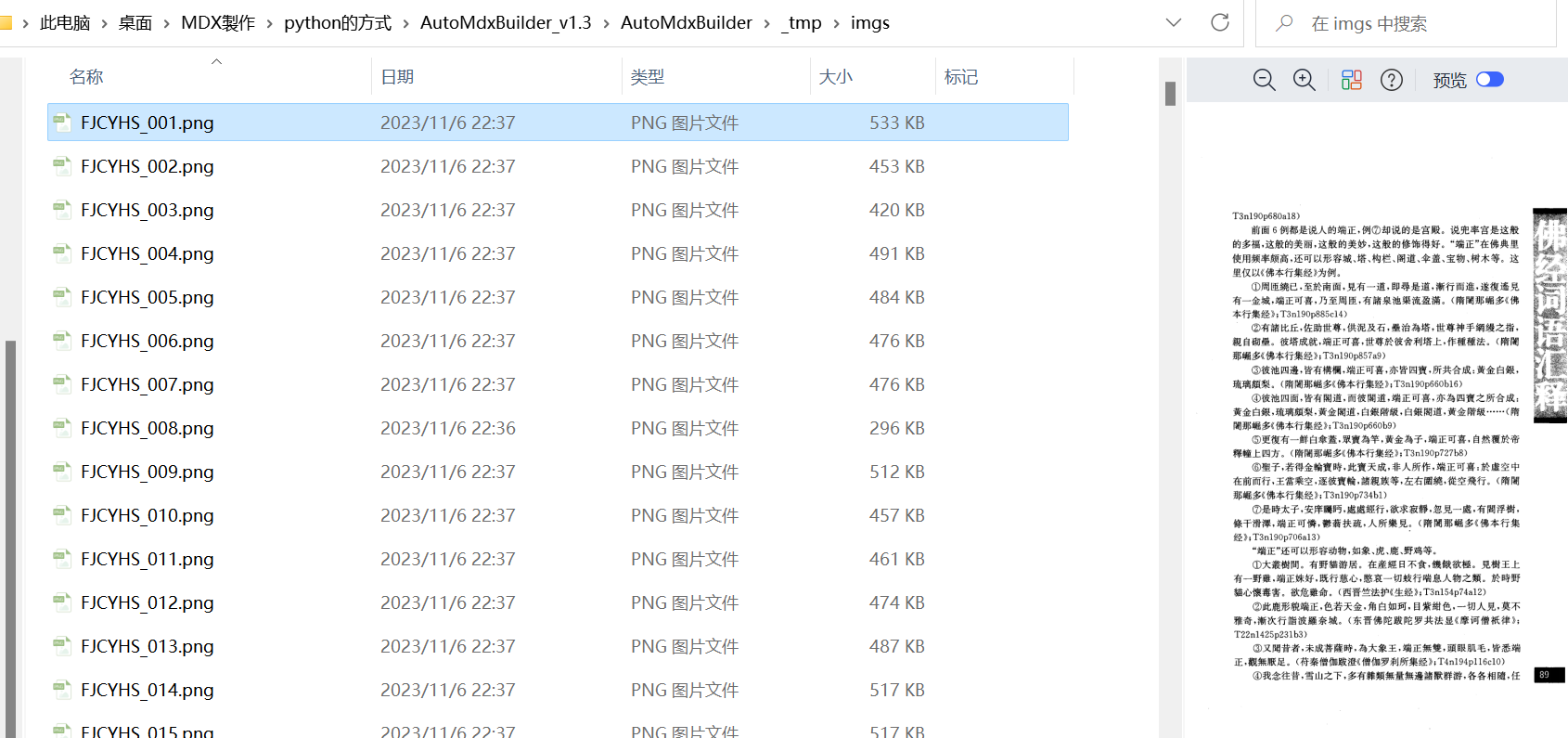
这是tmp里面,软件切出来的图片档,重新命名了,但是第1张图直接跳到了正文的第89页
-
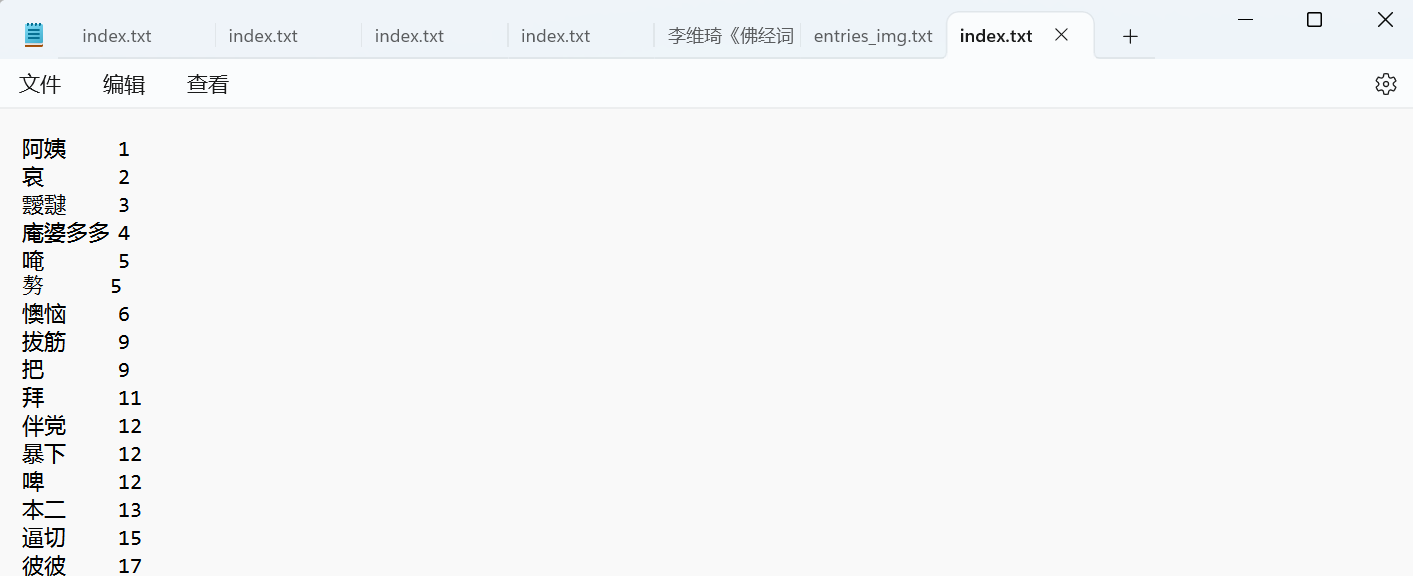
下面是我的索引,应该是没问题的:
-
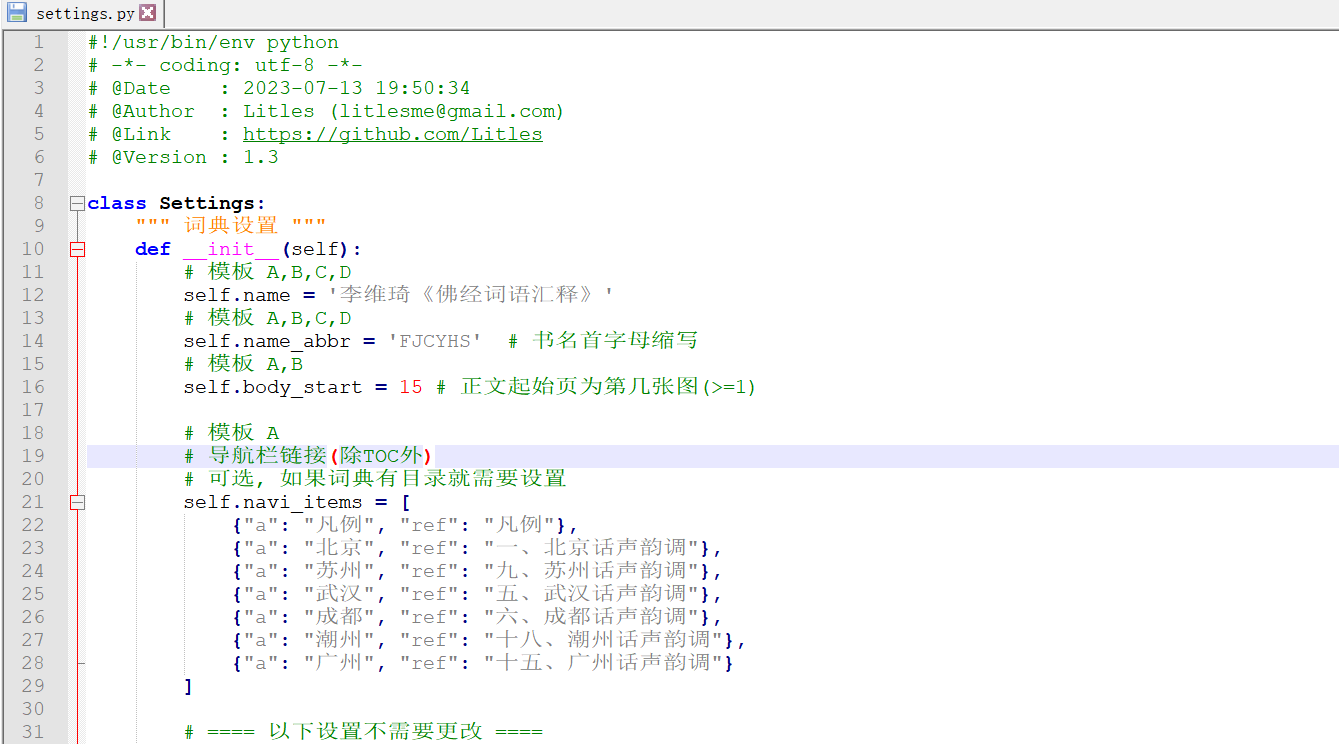
setting也基本没动:
看来没问题了,还是得按顺序来 ![]()
就是最后打包闪退报错了
File “D:\AutoMdxBuilder\img_dict_btmpl.py”, line 118, in _make_entries_with_navi
part_img = f’
<img src=“/{imgs[i][“name”]}”>
\n’~~~~^^^
IndexError: list index out of range
之前打包都没这样
不用中文,只按00001、00002、00003……这样编号呢
链接:百度网盘 请输入提取码
提取码:2ty2
–来自百度网盘超级会员V5的分享
不好意思,试了几次还是出现乱序的情况。
我试过:
- 原始图档名改为01、02、03……
- 将文件由450个图片减少为50个图片。
反复试了几次,还是出现乱序的情况。我将文件打包上传到这里了。
真抱歉占用楼主时间了,不知道是我哪里操作失误。
编号位数不一致的原因:
改成 000、001、002、……、098、099、100、101、…… 这样就可以了(重跑程序记得把 _tmp 文件夹先删了)
另外,这本书起始页应是第 16 张图,即设置 self.body_start = 16
程序没考虑到这种命名方式,后续的版本会优化兼容此种情况
这是怎么回事,是我词头设置太奇怪的原因吗,望解答
可能是 self.body_start 数值没设置正确
确实是,感谢哈
太好了!这次终于成功了。感谢楼主,谢谢您无私的奉献和耐心的指导!
重磅更新
新增
- 支持词典逆向,将 mdict 词典还原成原材料(有助于词典的二次编辑,并且不再需要备份原材料)
- 支持自动将 toc.txt 和 index.txt 合并成 index_all.txt(有助于给图像词典添加导航栏)
- 制作图像词典模板 B 时检查 index_all 索引可能存在的排序问题
- 去除模板选择环节,提升自动性
优化
- 分离配置文件和 AMB 程序,使原材料完全独立于程序;
- 提升图片命名的兼容性,对于位数不一致的;
- 优化 index_all.txt 转 toc_all.txt,减少报错
已打包成便携的 .exe 可执行程序包,无需安装 Python 环境(暂未编译 macOS平台软件包,可继续使用 Python 源码)
GitHub:AutoMdxBuilder v1.4
FM云盘:AutoMdxBuilder_xxx.zip
7 个赞
做了个简单的演示视频(也不知道会不会侵权哈哈),有兴趣的可以看看![]()
2 个赞
用AMB做词典确实简单太多,版面也漂亮,感谢M老大无私付出 ![]() 升级新版试一下
升级新版试一下
感谢楼主!测试发现这个更方便了!另外有两个反馈
-
如果imgs中的图片是中文+数字的形式,出来还是会乱序。
-
使用结束后,是否可以自动删除tmp里的内容,方便下次使用?
楼主辛苦了!造福大众。
可以的话还是建议使用纯数字,中文和数字的混合形式不好处理
_tmp 文件夹是不需要去删除,不用手动干预的;上回说要删除是因为排序乱了为彻底剔除干扰
1.4版本的材料和程序是隔离的,程序内的东西都不需要干预
3 个赞
能把位置信息带入不?直接写到样式里,好处理不。
你可以试一下,我把词头准确的位置发你测试,要是可以的话那真的简便多了,不用把文本导来导去的了,剩下就剩下专心校对词头了
那样就移动、桌面全兼顾到了
是的,程序目前的还原功能就是精准恢复(包括原始排序信息),原材料和mdict词典之间是等价转换,这样我认为才算真正的还原。
不过目前只支持还原用 AMB 制作的词典,如果只是用 AMB 打包的还不支持,这种后续也可以考虑支持恢复。