收到,会作为可选项,因为若索引本身是无序的,百分比不仅起不到定位作用反而会干扰注意力。
2 个赞
个人感觉,图片词典模板一,index.txt应该设置为可选项,在书签完备的时候不需要这个。
1 个赞
index.txt和toc.txt的合并不能有效识别无页码的书签层级,无法生成类似这样的index_all.txt。

修复了,会在 1.6 里重新
我之前用旧版打包发现会吞掉第一个词条(词条数量还在,就是会显示有这么个词条,但是点不开,查询的时候也查不到),不知道新版有没有解决。
还有这种事?我没遇到过,哪个版本有这个问题,试试 v1.5 看看
非常感谢制作这么好用的软件,我已经做了两个小本的柯林斯书籍的图片词典,非常棒!已经分享到论坛里。
遇到一个小问题,我在制作一本图片词典时,会有一个词头对应多个页面的问题,也就是一个词在多个页面中出现。我试了在index.txt文件中,重复这个词头,每个词头后都加入一个页码,可以实现检索。但在Mdict的检索框中,这个词头重复出现。不知有没有办法解决?
十分感谢!
这是 Mdict 自身的设计,无法改变。GoldenDict 里则是一次性展示同词目的所有页面。
人为的把所有页面提前拼在一起确实也可以,不过利大于弊,还是不做为好。
谢谢您!
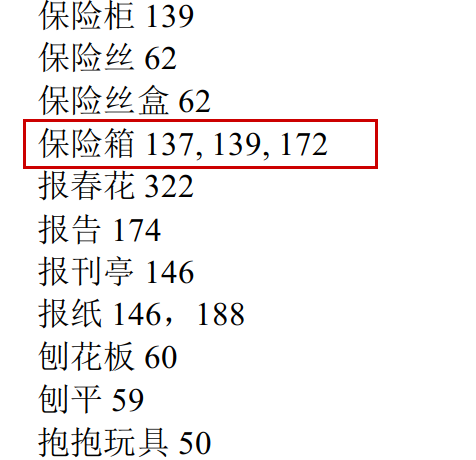
像图中的这种情况,我只能在index.txt文件中分三行重复三遍“保险箱”,然后逐一分别tab键,加上页码。像这样用逗号分隔就不行,“保险箱”就不能识别为词头了。
噢这个意思是吧。这种还是提前手动处理成符合 index.txt 的格式,可以用正则替换:
^([^\d\,]+)\s+(\d+)[,\s]+(\d+)[,\s]+(\d+)$
替换为
\1\t\2\n\1\t\3\n\1\t\4
后面我看下要不要兼容这种索引,让程序自动处理
【L0】
【L1】
【L2】
【L3】
这种可以增加支持英文格式吗,下面这样
[L0]
[L1]
[L2]
[L3]
感觉【】这两个符号输入起来,不如方便
不方便就对了![]() ,这样不容易与普通文本撞了,也比较突出,这个还是不兼容了,兼容越多越容易出 bug。
,这样不容易与普通文本撞了,也比较突出,这个还是不兼容了,兼容越多越容易出 bug。
2 个赞
说反了。
1 个赞
这个替换不太懂 ![]()
![]() ,我在word中用选择“通配符”后搜索替换,不能识别^([^\d,]+)\s+(\d+)[,\s]+(\d+)[,\s]+(\d+)$
,我在word中用选择“通配符”后搜索替换,不能识别^([^\d,]+)\s+(\d+)[,\s]+(\d+)[,\s]+(\d+)$
请问是用其他文本编辑器来搜索替换?直接替换,就能把所有上图中的情况改成类似
保险箱 137
保险箱 139
保险箱 172
这样,便可以放在index.txt里了索引,对吗?
1 个赞
如果用逗号分隔页码,是这样的情况
是的。现在还不支持逗号分隔,要提前手动处理成
保险箱 137
保险箱 139
保险箱 172
这种格式

这样的链接点进去会进入“凡例”、“目录”等非常常见的词语上,会有很多辞典冒出来,还需要再找到这本辞典才能查看,而一般都是为了查这本书的链接才点进去。
建议:【L0】、【L1】之类的超链接直接链接到一个准确的词条,如“ZGFSDCD_凡例”(辞典的简称,在build里设置),而不是直接转到“凡例”这样的普通条目上。
2 个赞
这个确实,正想优化来着,我想想怎么设计比较好。最早是为了精简词条量,就把一切词目(包括章节词目)都“普通”化了,不加任何前缀,这样做好处很明显,不过也有现在这样的副作用就是了。
全索引模式能否实现多层级的目录,具体可以参考mdxsourcebuilder制作的朗文多功能和朗文写作。多层级还可以用于汉语词典同时显示部首索引和音序索引,感觉很实用。
Longman Lexicon of Contemporary English - 词典展示合作 - FreeMdict Forum
【查询竞赛】Longman Language Activator 2nd 完美复现双解版 - 词典展示合作 - FreeMdict Forum
没太看明白,目前 模板B 不就是多层级的吗,还是说把目录的每个节点都向后展示到底?
因为担心有些词典层级枝叶太多,全部展示页面过长,并且章节也可能是词条,有对应图片,这个展示要看看怎么取舍,