应该就是这个原因了,但不一定有mac的版本。
1 个赞
ComicEnhancerPro 处理不了这种。
你现在要处理源文件这种?还是已经把红框内的切出来了(只是有些地方有多余)?
已经切出来了。不过我发现切的有些页面很有问题,比如有些页面把内容文字切掉了一部分… 可能因为之前没有纠斜。后面用 ComicEnhancerPro 纠斜一下,然后重新切试试,希望效果会更好一些,最好可以没有多余的边缘文字了 ![]()
p.s. 之前是用 Adobe Acrobat Pro 纠斜的,看起来效果很一般… 后面用 ComicEnhancerPro 试试
1 个赞
发现一个很有意思的切割软件,很适合你这样的情况,一张图片多次分割,然后导出。
同类软件很多,但这个方便,有 MAC 版。(可惜只能手工做,没有自动识别。)
BigShear-免费好用的素材分割工具 (guobasoft.com)
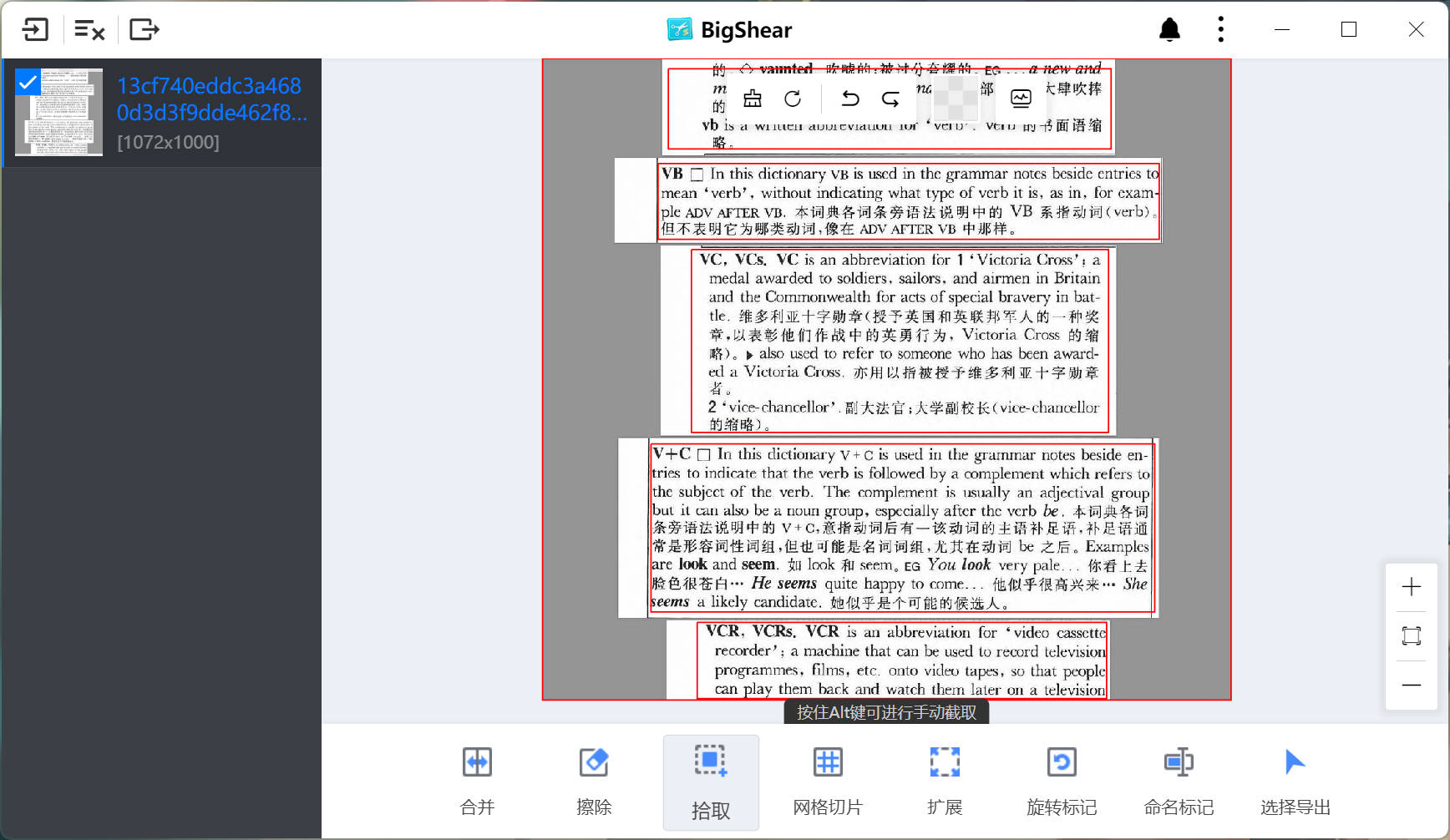
官方就有教程。
1 个赞
试了下,导入图片都很慢,可用性不太行
干掉了信息就不完整了,应该是柯林斯的吧?用切词做图片词典那个软件整条划线OCR,校对时再把语法信息放到你想放到的地方。不这么做你就单单处理这些不规则的语法信息就早早精尽人亡了。
那个软件没用过。 可以整个词条内容OCR吗?我记得只能词头OCR
可以、试过了。
我觉得你可以在OCR网站试用区OCR完了拿回那个画好线的软件里校对、那个切词软件每行每行的校对要方便的多。
要像那个软件作者裁成一条一条的话要熟练掌握那个切词软件的bate写法、就复杂了(知道了也简单)。
现在我到觉得OCR网站那些试用的接口都很好用了,没必要裁剪成条再OCR了。
去掉语法信息,就是为了OCR后尽量不需要校对,因为有语法信息的话,必然需要校对:将语法信息放在适当的位置(不想做这一步 ![]() )
)
1 个赞
近来OCR确实改善了好多相对于以前、但不校对直接拿来用的话还是个愿望,有力气先用到别的地方吧。要不到最后会玩到怀疑人生!!!
强烈建议你不要去OCR。
建议你直接用图片版。如果需要复制文字,临时来个OCR,快且容易校对。
图片太大了,找单词都不好找