多谢!暂时还不需要,期盼大作早日完善。
2 个赞
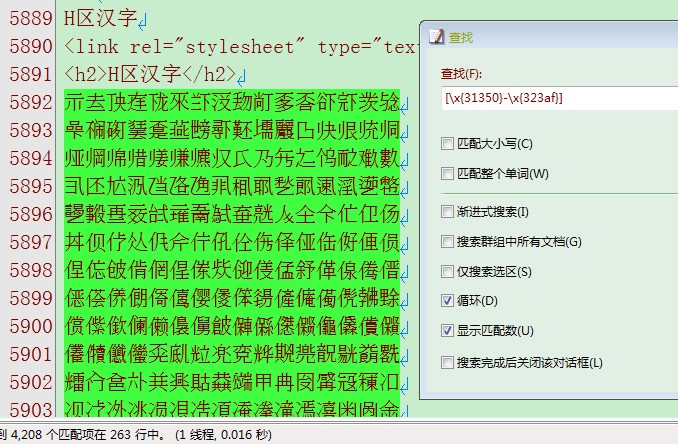
Onigmo,H区也是可以匹配到的。
[\x{31350}-\x{323af}]
1 个赞
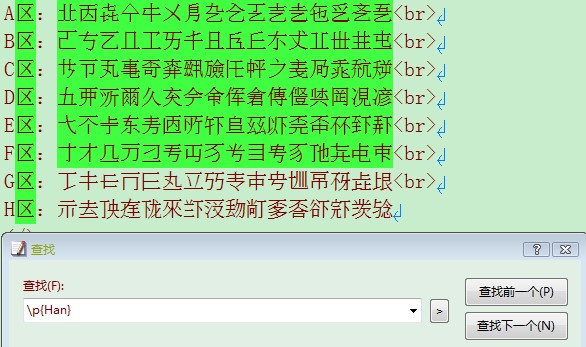
我们说的不是一回事啊,你用\p{Han}能匹配H区的汉字?
0.0.
呵,没看仔细。确实。
2 个赞
非常感谢各位的鼎力相助,热情回复,受益匪浅。
确实如 atauzki 所说,bs4会自动修复非闭合的标签
#测试1
>>> from bs4 import BeautifulSoup
>>> t = '<span class="ex"> <span class="ch">👉灯一下又亮了。<en> </span> <span class="en">After a while the lights went on again.<en> </span> <ex> </span>'
>>> BeautifulSoup(t).find(class_='ex')
<span class="ex"> <span class="ch">👉灯一下又亮了。<en> </en></span> <span class="en">After a while the lights went on again.<en> </en></span> <ex> </ex></span>
#测试2
>>> t = '<span class="ex"> <span class="ch">👉灯一下又亮了。<span class="en">After a while the lights went on again.'
>>> BeautifulSoup(t).find(class_='ex')
<span class="ex"> <span class="ch">👉灯一下又亮了。<span class="en">After a while the lights went on again.</span></span></span>
bs4的修复逻辑不一定符合你的要求
#测试3
>>> t = '<span class="ex"> <span class="ch">👉灯一下又亮了。<en> <span class="en">After a while the lights went on again.<en> </span> <ex> </span>'
>>> BeautifulSoup(t).find(class_='ex')
<span class="ex"> <span class="ch">👉灯一下又亮了。<en> <span class="en">After a while the lights went on again.<en> </en></span> <ex> </ex></en></span></span>
最好先找找有没有更靠谱的数据源,以免白做工
我以前用emeditor的时候,会用这种方法从里到外一层一层剥掉标签,
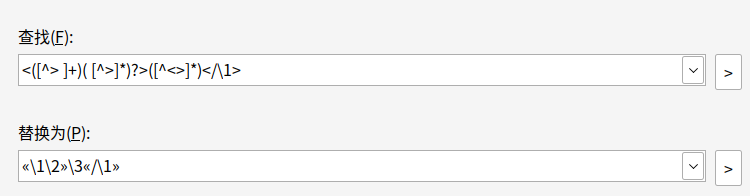
添加到批处理里面,一般执行十几次就可以,最后剩下的都是有问题的。(做这一步之前要先处理一下自闭合的标签)
3 个赞
再次感谢楼上各位,查找的方法应该了解了。同时再次感谢 @Vim @last_idol @jcz777 指点解决带出来的标签问题。
1 个赞