一起闲聊,提供一些信息。期望有人出手,做出更多成果。
提供汉字拆分信息一些其他地方。
- https://qxk.bnu.edu.cn 汉字全息构形查询
- Unihan Database Lookup
- https://babelstone.co.uk/CJK/IDS.TXT # Ideographic Description Sequences (IDS) for CJK Unified Ideographs
- 字形IDSデータ
- 汉文博士软件
- GitHub - kfcd/chaizi: 漢語拆字字典
- 【Mastameta】部件檢索(改裝)1.17更新
- https://learnm.org/ [excel拆分文件下载] https://learnm.org/static/data/ChineseCharacterMap.xlsx
- GitHub - ButTaiwan/hanseeker: Find all Han characters in Unicode by parts 其中包含文本拆分文件,如https://raw.githubusercontent.com/ButTaiwan/hanseeker/main/source/data_nosupp.txt
汉英简明解释:
如果需要汉英简释(汉英词典多如牛毛,但是收字广泛、释义简明的很少),可以考虑Unihan的释义: https://raw.githubusercontent.com/unicode-org/unihan-database/main/kDefinition.txt
疑问:关于汉汉词典,有哪个词典提供简明的释义呢?
对汉字或部首/排序:
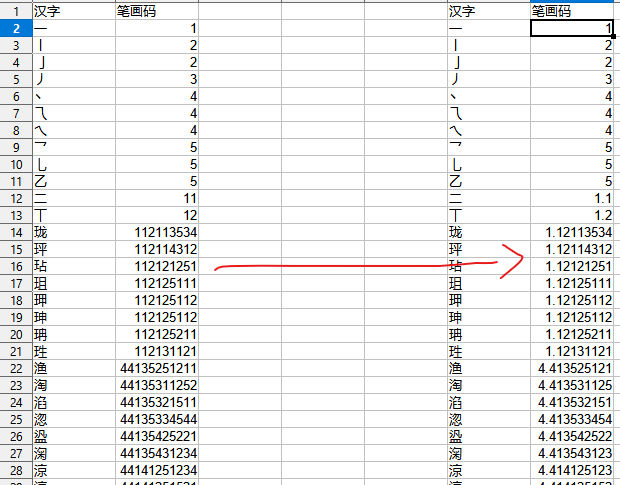
可以使用它们的笔画顺序码(横竖撇捺折分别用12345表示等等)排序。为什么需要排序?比如10画的部件,可能有几百个,如果没有排序的话,在某些场合,肉眼寻找某个部件,相当不便。一个笔画码文件:
另外,关于笔画码排序,有一个技巧:将笔画码转换成带小数点的数字,这样就更方便排序。示意:
杂想:
网络上很多拆分数据很芜杂(同一个拆分表可能出现草、艹、䒑、 艸;月,肉,⺼)。拆分理念也不同,有的把汉字多数只拆成2个部件,有的拆成很多细小的部件。不同拆分数据之间整合起来有困难。
分享一个正则:
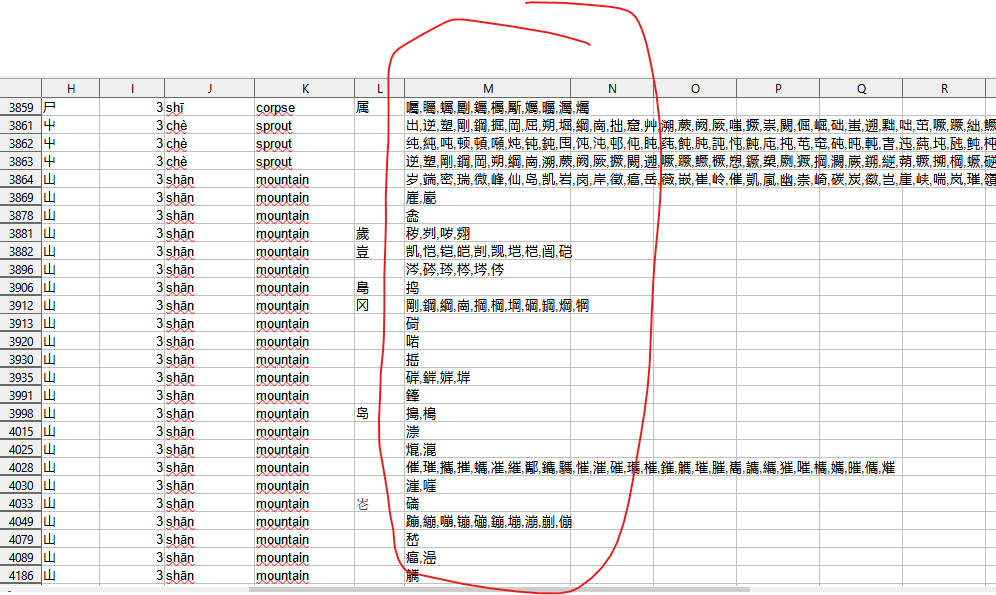
如何在给定汉字清单中删除指定的汉字?
比如下面excel表中M列,我只想保留通用字表一级汉字三千五百个汉字,如何做到?
先把这些文字复制到文本处理文件,比如emeditor,使用正则替换,然后再复制回excel表。
使用正则替换示意:[^这里输入通用字表一级汉字三千五百个汉字],替换成空白。
更好地分享的倡议:
为了更好的分享、造福社区,如果谁有什么成果,建议把源文件 、文本、过程文件、流程描述等也一并提供,方便他人再次利用。既然分享了,我们就分享地彻底些吧!