楼上我指控winter的时候,hua说的对,我是没有真凭实据的。暴露了我修养也没到家,还匿名发贴没能敢做敢当。但winter本人实在嫌疑太大了,和nonwill早期邮件的有你,在社区最先挑事的也有你,b站和v2ex上追着骂的,口吻和你也太像了。如果不是你的话,真的很抱歉。
还有楼上各位也请原谅我这个阴谋论者吧,我之前真的觉得好多贴都是来挑事的,看不惯。我保证以后再也不骚扰winter,也不给nonwill洗地了,老老实实做人,踏踏实实做事,好好修身养性。
楼上我指控winter的时候,hua说的对,我是没有真凭实据的。暴露了我修养也没到家,还匿名发贴没能敢做敢当。但winter本人实在嫌疑太大了,和nonwill早期邮件的有你,在社区最先挑事的也有你,b站和v2ex上追着骂的,口吻和你也太像了。如果不是你的话,真的很抱歉。
还有楼上各位也请原谅我这个阴谋论者吧,我之前真的觉得好多贴都是来挑事的,看不惯。我保证以后再也不骚扰winter,也不给nonwill洗地了,老老实实做人,踏踏实实做事,好好修身养性。
一直没搞懂划词和取词的区别。后来在官方GD基础上安装了论坛里那个OCR取词软件,Ctrl+右键比原来的Ctrl+C+C好用多了,配合鼠标自定义键更方便。如果能在PDF里悬停显示就更好了
划词是先选中单词后再查词。
取词是鼠标指向单词,不需要选中,即可查词。
首先我觉得小人这个词不妥,看到小人我就想到背叛和卑鄙。如果我们看到一个人得罪了小人,那我们可能且很大概率会想一下这个人是无辜的,你在开头就把 nonwill 的变化或多或少归结于得罪了某人,并将某人扣上小人的帽子,而不是关注他本身的变化,虽然你在最后说:“操作失误,难以理解”,不过这相比起小人这个帽子,还是轻了些。基于此上,我会觉得你在为他洗地。
另外本坛坛友 @winter ,我怕漏掉了什么回复,刚才又回去看了一下他的回复,他最初是非常支持 nonwill 的(链接),后来指出 nonwill 版本的问题(链接),再后来演变成了谩骂,我也私信和公开都提醒他不要言辞激烈,因为这无法解决问题。但是要搞清楚一点,winter 的谩骂是在 nonwill 挂人之后的,我也并不是说有理由的谩骂就是对的,这并不是解决问题的办法。之后你说 nonwill 的变化(失了智和社区群嘲)的起因的是得罪了某人,这个前后因果恕我愚钝,并没有想明白。
最后,它的软件安全性有没有问题,我不知道,因为这后来我没见过改过的源代码了,不过你怎么知道的,我不知道。
小人的定义,我比你更宽松,前恭后倨,有需要你帮助的时候恭维你,用不上你的时候狂踩你,表面一套背后一套的做派。@winter、@ilov 以及后文提到的 @marco,是和nonwill有邮件来往的三个人。邮件具体内容在箐典那边可以看到,但也有攻击 @hua 本人以及本社区的内容,我并不认同,各位自行分辨。至于 @winter、@ilov 的表现,是不是符合前面的定义,每个人都有自己的标准,这里不再赘述。
你觉得我在洗地,我完全理解,虽然这不是我的本意。我更关注nonwill变化的起因,人都是有两面的,经不起考验,尤其是当人性之恶被放大的时候。
下面的文字并不是给nonwill洗地,而是验尸,避免类似事件再次发生,原因:
我觉得有人来社区是故意挑事的,可能已经连续作案好几起了。
https://forum.freemdict.com/t/topic/2354/1085
早期围绕在nonwill的箐典GoldenDict++上的争议点有4个方面,分别是安全问题,搜集个人信息,GPL闭源和广告募款:
软件的安全性有没有问题,并不需要看源码,过一过在线的杀毒软件就可以了。
下面是箐典GoldenDict OCR-2A4D-Qt-5.9.9,VirusTotal的检测结果:
No security vendors and no sandboxes flagged this file as malicious 查看链接
上面的报告结果并没有发现安全问题,但箐典GoldenDict++早期是有被检测出病毒的,问题出在当时新增的取词程序上。个人开发者的软件如果用到系统函数的话,很容易会被敏感的杀毒软件报毒,而取词程序,会更容易出问题,实际上是几乎所有词典软件的取词程序都无法避免类似的情况,除非主动给安全公司交保护费。
再拿社区里 @Johnny_Van 的Ahktionary为例:
下面是Ahktionary的取词程序GdOcrTool,VirusTotal的检测结果:
6 security vendors and no sandboxes flagged this file as malicious 查看链接
结果是有6个杀毒软件报毒,再来社区里用的比较多的,AutoHotkey:
4 security vendors and no sandboxes flagged this file as malicious 查看链接
结果是有4个杀毒软件报毒。
其实上面这些都是误报,记得当时的回贴里很多人也说杀毒软件报毒是正常的,本不应该引起那么大争议,而且要不要使用取词程序,是可以自己决定的。但某些人就是揣着明白装糊涂,明知是误报,还要在社区里,在外面到处宣传箐典有病毒,要致箐典于死地。
b站(请注意,这里只提到病毒):
v2ex:
生命不息,斗争不已 ![]()
如果你觉得自己是正义的,请不要通过造谣的手段来诋毁别人,因为当人们察觉到事情真相之后,是有可能站在你的对立面的。
我那句话是平白直述,是说给看了你评论的人说的,没有指责你有造谣的行为。但如果你觉得箐典还是有安全问题,那就是吧,我没意见。
没有记错的话,这种敌视本社区的行为是半年之后的事了。这里我不想把事件的起因,和后面的结果混在一起谈,会干扰我们对这件事的认知。
这是很多人提到的事情,指控nonwill的箐典GoldenDict++搜集个人信息,但指控的根据是什么?箐典开发群里的 @LostTemple 在社区里发贴《招募箐典的软件开发志愿者》,负责移动端的开发,他在感慨箐典的用户多的时候,做出了如下描述,并附有一张截图:
原楼层里 @LostTemple 不像是来招募开发者的,反而像是专门来给 nonwill 拉仇恨的,这个时候 nonwill 应该已经开始对社区有敌意了,后面两个话题会说到。上面的招募贴文里可以看到 @endnote 提到了保护个人隐私的事,但这个时候问题还没有发酵,只是随着 @LostTemple 持续在社区里拱火,这事变质了,从提醒保护个人隐私变成了指控箐典搜集个人信息。
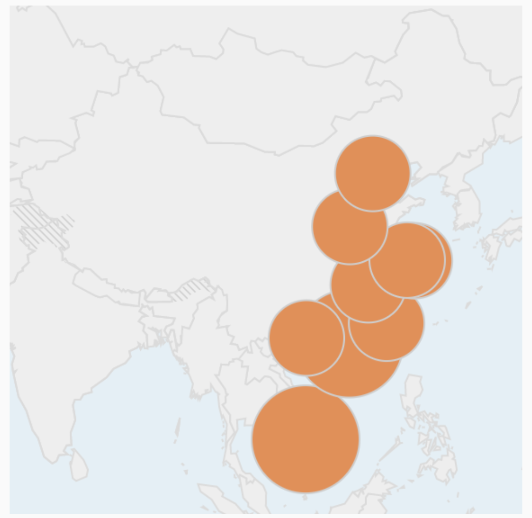
指控的根据是上文里 @LostTemple 给出的这张截图:
这是一张箐典GoldenDict++的用户分布图。用这张图指控箐典搜集个人信息,我认为是不足够的,因为只能看到用户的地理信息,而且这张截图应该是来自某个第三方的数据统计平台。这种类似google-analytics,cloudflare的数据统计平台,几乎是每个网站应用的标配,本社区的话有,隔壁社区也有,不同论坛程序也会保存用户的登录信息,但你要因此到处说本社区在收集用户的个人信息的话,我觉得这个指控过于严重了。
pdawiki:
freemdict:
箐典GoldenDict++是开源过的,后来不想被商业软件抄袭就闭源了。使用了GPL协议的代码,闭源是有原罪的,箐典有,那你眼里欧路有原罪吗?直接抄袭GoldenDict的代码。MDict有原罪吗?使用了GPL协议的压缩库。这两都是直接侵犯了GPL协议的产品,但性质真的很严重吗?那欧路和MDict为什么没人找茬?有时间再接着分析。
no。我说过闭源有原罪的,不能这么干。但为什么就他出事了。。
没能睡着,那我问个和你相关的话题啊,为什么你能这么在意GPL协议的软件版权,但对使用盗版的词典,却同样表现的这么心安理得?没有讽刺的意思。我觉得社区里大多数人是不在意版权问题的,词典的盗版资源远比正版资源要丰富的多,大家用更香的盗版资源是很正常的选择,也是我的选择,但我对其中少部份的GPL协议的圣战者实在无法理解。可以给我个答案吗?
人啊,真是矛盾的集合体。
应该说是人性的懒惰,买正版是要支持它继续发展,用盗版是因为有些盗版比正版更好用
看anonymous58的回帖,才大体了解事情的原委,其中原来这么多恩怨。
人心都有善恶,也许多换位思考,将心比心,才能抑恶扬善,多份包容。
我可以理解用盗版的,因为我自己也用,无法理解的是后者,比如前文提到的邮件里的 @marco,github上是 @GPLv3-fan,本社区也有账号,这个人是非常热心的(没有讽刺意思),经常在Goldendict的社区TG群里推广盗版词典资源,但同时他本人也是GPL的信徒。
GPL是种版权协议,GoldenDict的代码的版权就属于这种,抄袭了GoldenDict的代码的软件,无论是用什么语言实现的,根据GPL协议同样应该开源。
各种软件的版权协议其实都是非常乌托邦的,这之中的MIT协议则是最自由的一种,这份协议让开发者承诺放弃所有代码版权的同时,也极大的推动了互联网行业的蓬勃发展,极少数的头部开发者收获了名望,而更多的开发者则沦为了大公司的免费劳动力,去年还出现了3.2万stars的faker.js的作者在家中事故之后于网上乞讨的事件,faker.js这个项目他维护了十年,许多互联网大公司都使用了他的作品,但没有得到任何实际的收益,在多次募款无果之后,他删除了所有代码。
自由软件基金会撰写的GPL协议,是少数对大公司有约束力的版权协议,想使用了GPL协议的代码,要么一起开源,要么从作者那购买授权,但对中小型公司和个人开发者更多还是全靠自觉,作者维权的成本过于高昂。于国内的词典软件而言,更是不好深究的事:
在词典资源的社区,高举GPL协议打击词典软件的作者,是件非常奇怪的事。
大家手中的资源不是来自出版商的光盘破解,就是软件APP资源提取,再就是脚本爬取词典网站的条目。直白的说,社区里大多数人对版权问题是不在意的。社区里欧路的粉丝也有很多,他们无意识在社区里给侵犯GPL协议的欧路做着宣传推广工作,欧路直接抄袭了GoldenDict的代码,欧路可以在社区存在传播,但有新出的词典软件侵犯了GPL协议后就被谴责打击,这是件更奇怪的事。
PS:虽然我可以理解箐典后来的闭源举动,不想沦为商业软件的免费劳动力,但nonwill在GoldenDict项目组的捣乱行为是非常无耻的。
于现实而言:
我认为GPL协议是用来约束自己的,不宜在社区里强求别人遵守。
这里是词典资源社区,谈这个不合适。
nonwill口碑的崩盘,有别人的诱因,但主要还是他自己作死。
我没尊重版权,除了盗版好用外,最主要的是因为钱,也因为大家都在用。
论坛作为提供在线服务的平台,搜集用户IP当然正常,但并不意味着搜集的信息可以公开或者滥用。GD++作为一款本地软件,即便有联网功能,也是向内容提供方(在线词典网站)发送请求,若开发者私自获取用户IP,且未注明信息搜集,就是窃取。况且,闭源的软件,你知道它还搜集过什么?
闭源的软件,同样可以知道它搜集过什么。
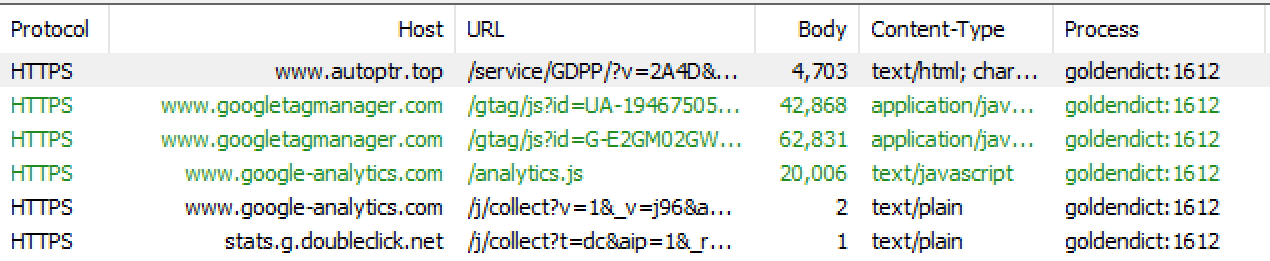
下面是Fiddle对箐典GoldenDict++的对外通信的抓包记录:
如上图所示,箐典对外请求的连接有6条,涉及到4个网址。
这里先说后面三个,googletagmanager、google-analytics以及doubleclick,这三个网址同属于Goolge官方的数据统计服务,据我所知这三个服务都看不到用户的实际的IP地址,只有用户的地理信息,而没有IP地址是不能够识别用户身份的。
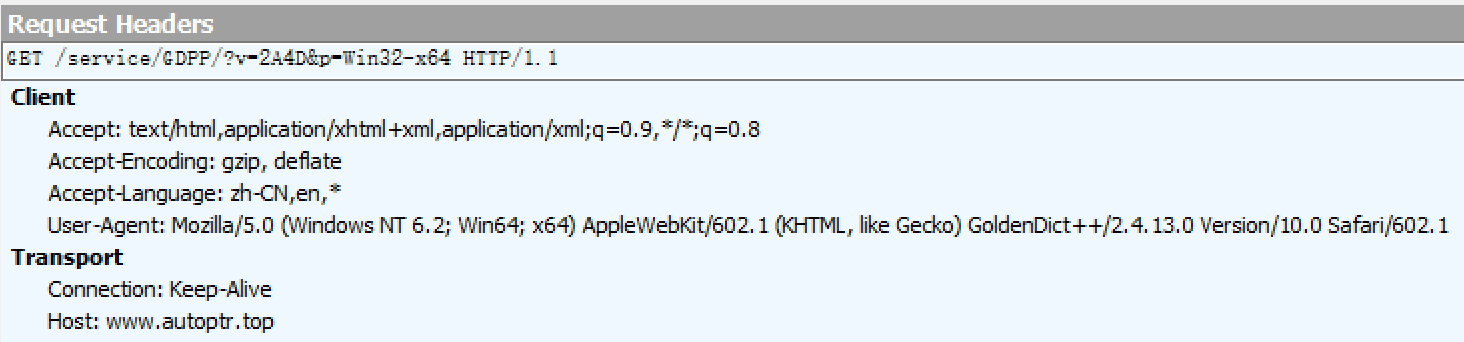
再说第一个autoptr.top,应该是箐典的软件更新服务,上传给服务器的信息的内容如下:
这是一个HTTPGet请求,传输的数据是明文的,就在链接里,有两个值:
这个请求和GoldenDict官方版本是保持一致的,每次GoldenDict启动都会发送后台请求,检查软件是否需要更新,这里2A4D,代表使用的GoldenDict的版本,Win32-x64代表GoldnDict的平台格式。
分析完箐典的对外通讯记录,我的看法是:
箐典GoldenDict++没有搜集用户的个人信息