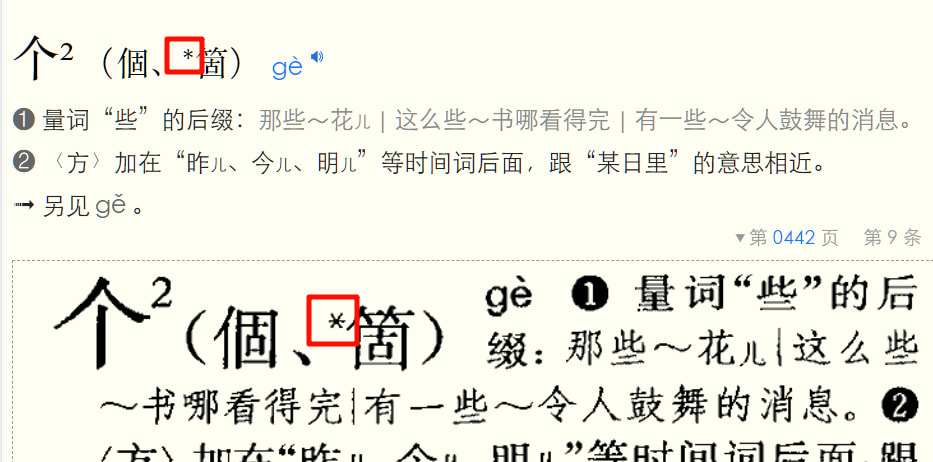
“丽”有两个音,M.C都标出来了,和图像版一致。老兄的处理程式忽略了第二个音吧?
丽(麗)
lí
❶ 丽水(Líshuǐ),地名,在浙江。
❷ 见〖高丽〗、“句1”下“高句丽”。
另见lì。
丽1(麗)
lì
❶ 好看;美丽:壮~|秀~|风和日~。
❷ (Lì)名姓。
还是我没理解老兄的意思?
我想老兄只处理了“丽”,没考虑到“丽1”的那个1?
“丽”有两个音,M.C都标出来了,和图像版一致。老兄的处理程式忽略了第二个音吧?
丽(麗)
lí
❶ 丽水(Líshuǐ),地名,在浙江。
❷ 见〖高丽〗、“句1”下“高句丽”。
另见lì。
丽1(麗)
lì
❶ 好看;美丽:壮~|秀~|风和日~。
❷ (Lì)名姓。
还是我没理解老兄的意思?
我想老兄只处理了“丽”,没考虑到“丽1”的那个1?
多谢shaoshi兄,是我唐突了,竟没想到“丽”还有另一个读音。不过也是好事,以后再见到“丽水”“高丽”,我肯定不会读错了。
发音文件需要经过诸如ābí dìyù转换成a1_bi2_di4_yu4的处理,这还只是第一层,后面要处理轻声、儿化音、音节划分等,工程还挺大。
方法可行;不过最近的那个网站上可以提取,还是wav格式,直接避免音质损失。
格式转换我已经处理完了,现在正在下载,大概五万多条。但有不少网站上没有,有些应该本来就没有,比如带外文的词条;有些可能网站缺失,比如有的儿化音。
原来兄台也在抓取,如果知道就不重复劳动了。那我把处理过的格式对照表发上来,看对老兄是否有点帮助,不过我做事比较粗糙,有些无关紧要的网站也不会有的就没有进一步处理,当然也可能还有其它错误。既然老兄出手,我就不再下载了,直接做伸手党,呵呵。
这个是怎么判断的?只要是r结尾的都是儿话音吗?
gū·niangr gu1_niang_er5
还有这个怎么拆的?我觉得你拆得挺好的。
ābí dìyù ā_bí _dì_yù a1_bi2_di4_yu4
r前非e后非元音字母就是儿化音
刚仔细一下,吓我一跳,以为niang后忘了加5呢。最终格式用最后一列。
抱歉,发现了一类重大错误!
上午在单位制作带声调字母替换表时,不小心把三声i标为4。下午在家进一步处理时才发现三声i和四声i都标成4了,也才连带知道了丽原来还有两个音。
但因为不想重制替换表,就想用正则处理,以为没问题了,刚才看下载出错的文件表时才发现有不少还是替换错了。
幸亏只有百十个,不想推倒重来,就手工一一纠错了。
果然粗心不是谦虚,又发现r类错误和元音字母开头错误,外加把阿Q改为a1_q。这次错误应该几乎没有了吧,汗
为了便于对应,第二栏没有去重。因为加密以天为单位,下载时最后从早晨开始。
现汉拼音n.txt (1.3 MB)
共下载音频文件55447。
词典中拼音有两处’应改为’,五处,应改为,。
首先感谢楼主制作维护迄今为止最完善的mdict版现汉7。今天偶然发现两处小问题。
一是“三角函数”条的一个式子不完整:
二是分数的排版可以再完善一下。目前版本的“分式”一条和官方app一样使用了PUA字,但“分数”一条没有。“分数”一条释文中有一个带分数,目前的排版方式容易引起歧义,这个地方建议还是仿照官方app使用PUA字,或者嵌入图片。
请教下,像是含有很多生僻字的汉语词典,尤其涉及到古文那些,有没有可能做成纯文本TXT格式呢。
——个人对纯文本词典有些偏执,哈哈
存为纯文本Unicore text,没有问题。
但是,你用的软件能不能应付这种文本?可能不行。看你用什么软件。
另外,无Unicode标准字的罕见字,在mdx中可以用特制私用字体的私用区字处理。这些字一存为纯文本,都会变成错字。
还有一点,你得自己动手做。别指望别人帮你做好。
手机上不起作用呢,深蓝和DictTango都一样。谢谢!
谢谢答复!
其实也不至于会查看那么偏门的生僻字。
另外,是由我自己操作,事实上也只能自己操作:因为我不是为了下载一个现成的TXT大容量包。而主要是为了自定义自己的常用词库(见到一些值得记录的生僻字就追加进去,日积月累,形成某种“字典”,所以才重点关注TXT,因为省事而且全平台嘛)
我使用的是Emacs只是为了方便迅速打开大容量TXT文件,并且有read-only模式。
老大辛苦了。新年快乐!!!
感谢大大制作分享。发现一个问题,在欧路词典安卓版,有的字后面的词语点击后无法正常跳转,显示一篇空白,如“礼”字,电脑版的欧路词典没有这种情况。不知道是软件本身的原因还是词典的原因,辛苦您看下。
参考此帖做法
这个词典我一直是放在所有词典最前面的,依旧有这个问题