据说优秀的辞书,字头跟释义用字是自成闭环的,释义中用到的每一字在本书里都能查到


300多人合作的。某人用了什么字形,其他人可能都未必知道。
新版應當修了。(小問題,需要那麼大的截圖嗎?好佔地兒哈哈)
图大,醒目 ![]()
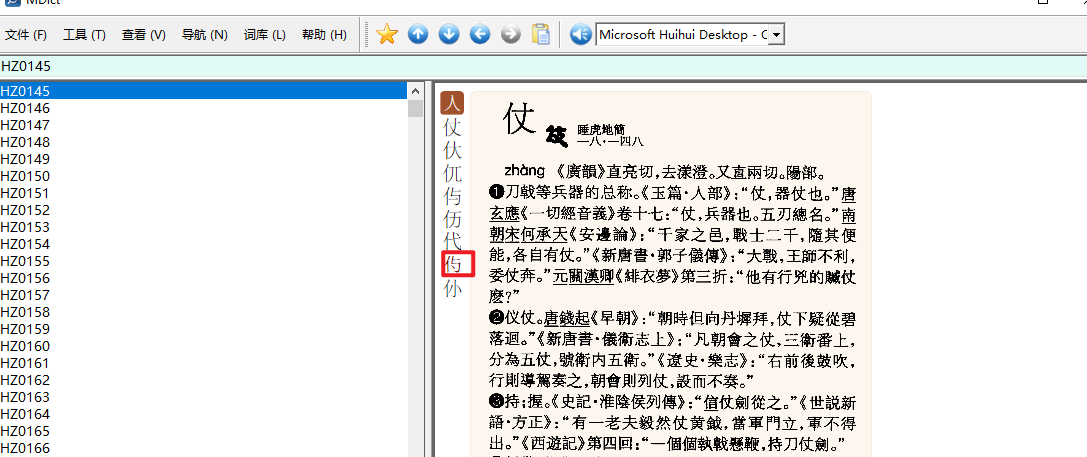
that page works normally for me. 注意:查文字版缺的字頭,會進入(或保持在)圖像板界面。
反饋一些問題:
妃:原文「通“配”」,此文字版少一「通」字。

飛:義項第 10,例證(鬼谷子‧飛箝)併入了釋義。

會:義項第 8,例證(清 蒲松齡 富貴神仙)又條誤作釋義或按語。

將:義項第 21-3,書證(孙经世 經傳釋詞補)併入了釋義。

度:義項(三)(「同“宅”」條),例證(書·堯典)誤作按語或釋義。

高:義項第 9,書證(爾雅)併入了釋義。

賽:義項第 2,例證(金 董解元 西廂記諸宫調)誤作按語或釋義。

苗:義項第 8,例證的注誤作按語。

示:義項第 8 ,例證(莊子·徐無鬼)誤作按語。

嘉:義項第 5,例證(周禮)併入了釋義。

絕:義項第 1,例證(史記·刺客列傳)誤作按語。

快:義項第 11,例證(元 佚名 百花亭)「買快探

轟:義項第 4,例證(矛盾·子夜)「高声


查询“直”字时,第3义项的例句:“不能裂肝脑”中的“脑”字的颜色与例句不同
私有區字標紅色。有點太顯眼,也許當限制於字頭。
辛苦了!
這一問題,僅見於通假,它處沒有這種情況。這應當是標點符號的使用問題,而不是區分引證與編者語的體例問題。通假的義項,其引證無非包含了通假字與本字,以證明兩者通假。只不過有時引証的材料,本字或通假字的位置或在引文中,或在後面注或解釋中,位置不定。如此一來,字頭(通假字、本子皆有可能)要麼出現在引文,要麼出現在注中,這是自然不過。字頭出現在引文,引文的語意算是完整的(從整個語境看),所以使用句號;字頭不在引文,那自然整句語意不完全,所以不當用句號,需配合後面解釋性的內容,才成一連貫完整的語意段落,故句號標在了整個引證的最後(引證不只是引文,後面的注,一般都是引證不可或缺的一部分,除非加了按語,或有明顯的編者語氣,可另作編者語看待。)這裏舉個有意思的例子,它是出現在引文中的例子,它很能說明是標點符號的使用問題。「據」義項第 12-1,引用了王氏《經義述聞》的書證材料。在《經義述聞》的引文中,標點符號的使用也是如此。

再從引證的排序標準看,也能證明它們是引證。例如,「立」字,「通「位」」一條,例證中 周禮 的引句,亦無標句號。但按引證排序看,是符合作為例證的標準的。漢語大字典先書證後例證,再分別按時間排序。所以,此條例證位於書證(篇海類編)之下,又時間皆早於論語、馬王堆等例證,故位於其上。倘若非引證,又何必嚴謹排序,我想這不是偶然~此例眾多不贅述。

還有一個有意思的例子。「瓜」字義項第 5,例證 三國志,引文與釋義沒多大的關係,同樣也不出現字頭,語意不完全,所以沒加句號。有關係的是後面的引用的注文部分。引文的作用只是說明其後面的注文是出自於該引文而已。所以,並是不是引文就是引證的主體,注文也是其相當重要的一部分,只是有時彼此重要性不同。所以應該更多地把它們作整體看待。

以上所談是一般的例子,M 兄所舉的「琘」例子,確實亦可當編者語看待。如果按照體例角度,統一當作書證處理好也不是不行,「琘」字下一書證一例證正好(一般字只有實在無書證或例證,才會缺省)。如果說它不是引證吧,但它又確實屬於引證的性質,只不過編者做了修改(我好奇本來《龍龕手鑑》本就有簡短完整的原文,他們不直接引用,非得更改,不然就不會有這種糾纏的問題。當然,這只是個別情況,大多數情況,也只是對引證作刪省)。總之,漢語大字典有些內容標準不一,兄得從整體看待。
這類問題,本來原辭書合併在一起,樣式也統一無別,魚龍混雜的,一眼看過去也似乎沒啥問題。然而一旦稍加區分開來,這些問題之“魚”都跳顯出来了![]()
確實,我本嘗試用正則處理一些內容問題,尤其是引證部分,但是原辭書自身以及數據的問題加起來,讓一切變得十分棘手~(我想您的處理方式和原則大致是對的。
這種大型辭書,向來不用文字版,只用圖像版,省心很多。只是 M 兄的製作一向嚴謹精良,不得不用![]()
人家不見得同意我的做法,但我在這問題上是有用心,不是草率弄出來的。引證標籤,開始鑽這個洞,就會注意到像你說的“魚”跳出來,甚至魚龍百變,不少怪事出現哈哈。
通過這過程發現字典的標點錯失是個好事。
原來有十幾條釋義殘缺,我試探了 OCR 文本的效果。(包括:畛11、鉦2、升7、匣4、佩2、俎2、侯2、尊2、爵2)
我之前抱著希望可以利用 OCR 文本來批量增補字條,現在結論是不可能的。每條要花太多少功夫糾正、校對,和調理標籤。雖然效果比我想象的好,錯誤還是太多了,甚至認不出李善、高誘、鄭玄等等,雖然都不是僻字。
字形有問題的字頭,我後來決定提供補充,用括號。
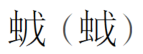

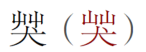
如果字形不但錯,又不符合 Unicode 標準,就一概改成正字。
𤰈 

目前针对古籍的 OCR,也许只有古联(中华书局)开发设计的最好,它甚至连稿本和手抄本都能高准确率识别,应该也能识别“正常”文本吧,我没试过。它还能提供原文与识别结果的对照,以及自动分析可疑结果并高亮显示,对校对修改十分的友好。它不过目前只是开放个人测试阶段,还不能批量识别处理。具体可见:
重磅发布丨古联OCR系统上线!
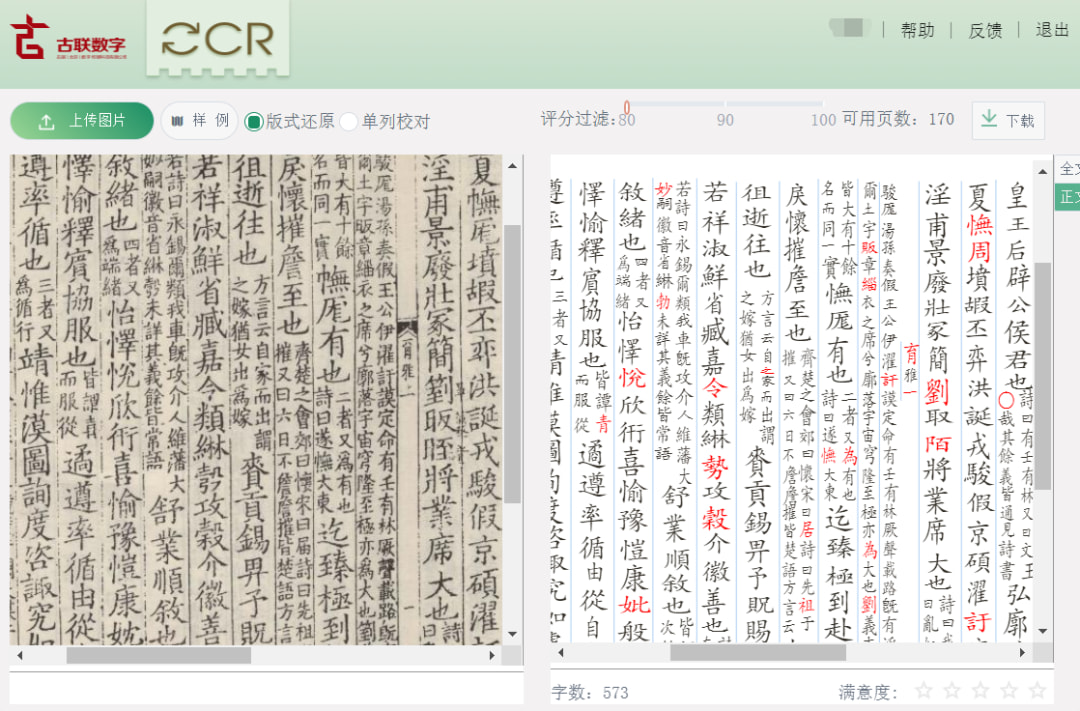
that looks cool.
感覺漢字 OCR 是個 self learning AI + big data 能解決的問題…不知道像阿里巴巴做到什麼程度了。
很多刻本都有校訂出來的 “答案”, AI 可以按照答案訓練、自學,不是嗎?
是这么一回事,只是像这种更专业层面的少有人做罢了。
阿里、腾讯、百度等都有自己的 OCR 产品,但是它们针对的领域和需求不同。虽然我没用过阿里的,但我看它们都不出日常办公和商用的范围,至于更专业的文字处理(像古籍文字这类),我是不奢望的。像中华书局这种,有实际的专业需求,才会投入精力合作研发这样的 OCR 系统。