倒沒忘記,但字型輸出到 辭源 文檔去了哈哈。腦筋清楚,眼睛花了。
順便也分辨了 朓、脁、嵒、嵓。更新了。
7 个赞

字典沒收“抑”字。這個跳轉刪了。更新了。
這個 億–抑 關係原來是從《辭源》搬過來:“億:用同 ‘抑’。”
說文的跳轉大多也搬過來用,應當有些用在《字源》不妥,可以留意。
3 个赞
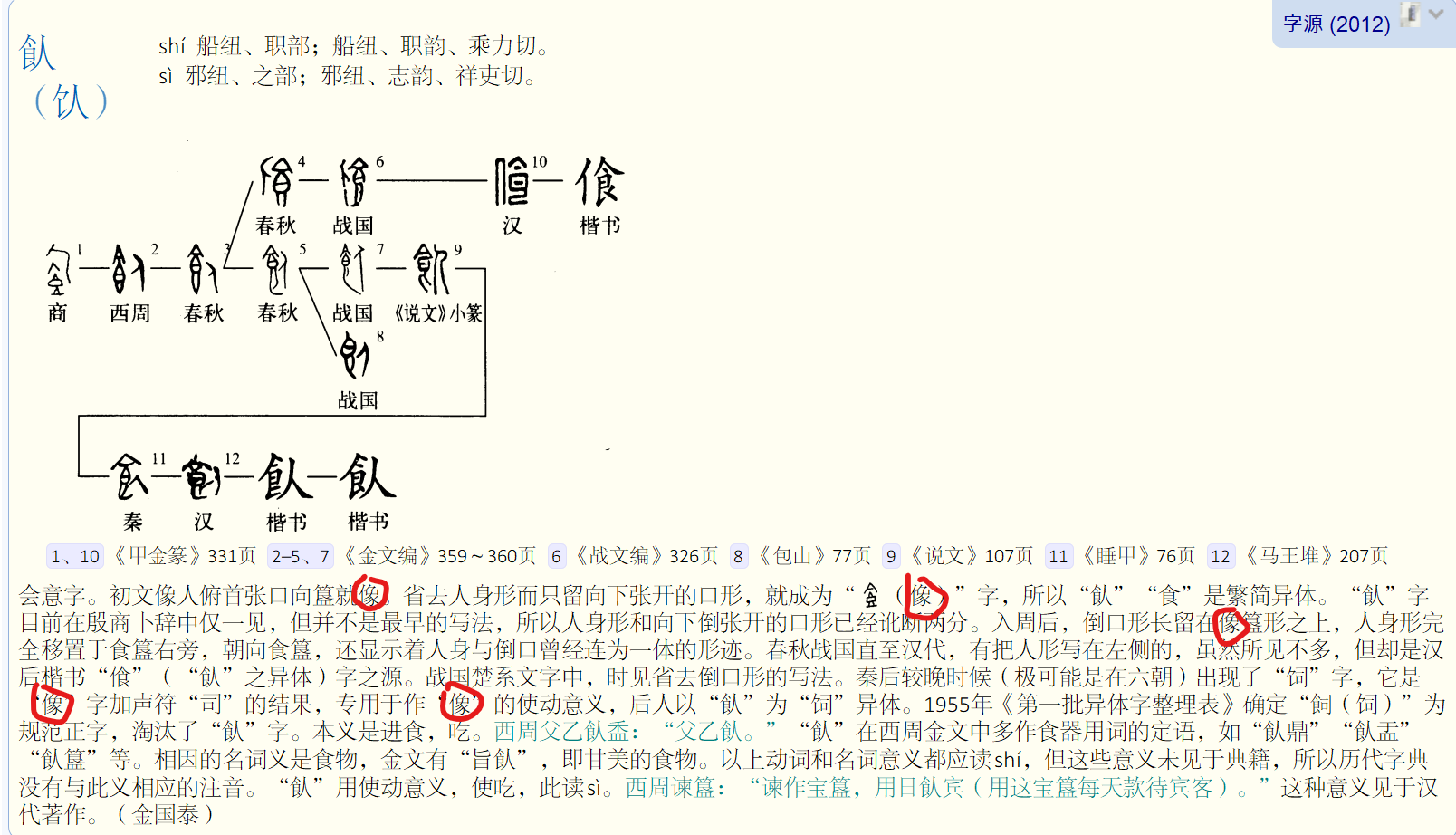

卻是奇怪。我瞧了幾個 “食” 偏旁的字條,沒看到類似問題。
就改了那些字。
请问M大,《字源》很早就有图像版,现在文字版也日益精善,有考虑过做图文综合版么
除了上面的怪問題,好像不常有對照的需求。因為原書的‘難字’,數據本來提供私有區字、或小圖片來表現 — 不像其他電子版,需要多加工才能構成原樣。據我所見,已經是挺完整的。
2 个赞


在 body font-family 加你喜歡的字型,排在 ZhongHuaSongPlane00 之前就是了。
數據配的是中華,原來就有700多中華私有區字,這部分必須用中華。
有心的人也可以在嵌入字型上加工,把線條加粗。For me, the contours are also a bit too thin, especially the horizontal lines, but I view all my dictionaries with one or two levels of zoom, in which case, it is perfectly fine. In fact, it is probably better to zoom using a thin font.
4 个赞
- 眾口難調,你要宋體,他愛黑體,我中意楷體,字體也屬於樣式風格範疇,不太可能統一的。

3 个赞
業務不同,代碼也不同,強求統一的弊端是會給前端開發者加上更大的束縛,很難保證每個開發者都認同用一套模板。
2 个赞
基本样式是可以统一的,字体字型/字重/大小、行间距、段间距等等。字体字重作者可以自由发挥,css后面自己覆盖就好了。
1 个赞
看到有网友反馈字体冲突的问题,还有修改css的解决办法。
转过来供参考:
2 个赞
更新到 Unicode 15。代表字闕的方格 PUA,都直接換成“□”。四十多處。
刪了些不合適的跳轉。
2 个赞
10.24版本更新后,不知道还需要不需要换上这个css呢
CSS應當沒變。
2 个赞
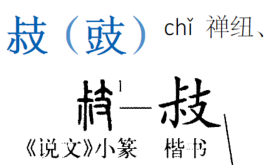
敊,在字頭和釋文都是錯字。紙本亦誤。我改成𢻃。
敊、𢻃音義不同。
5 个赞
查“巳”、“已”都显示“巳”。
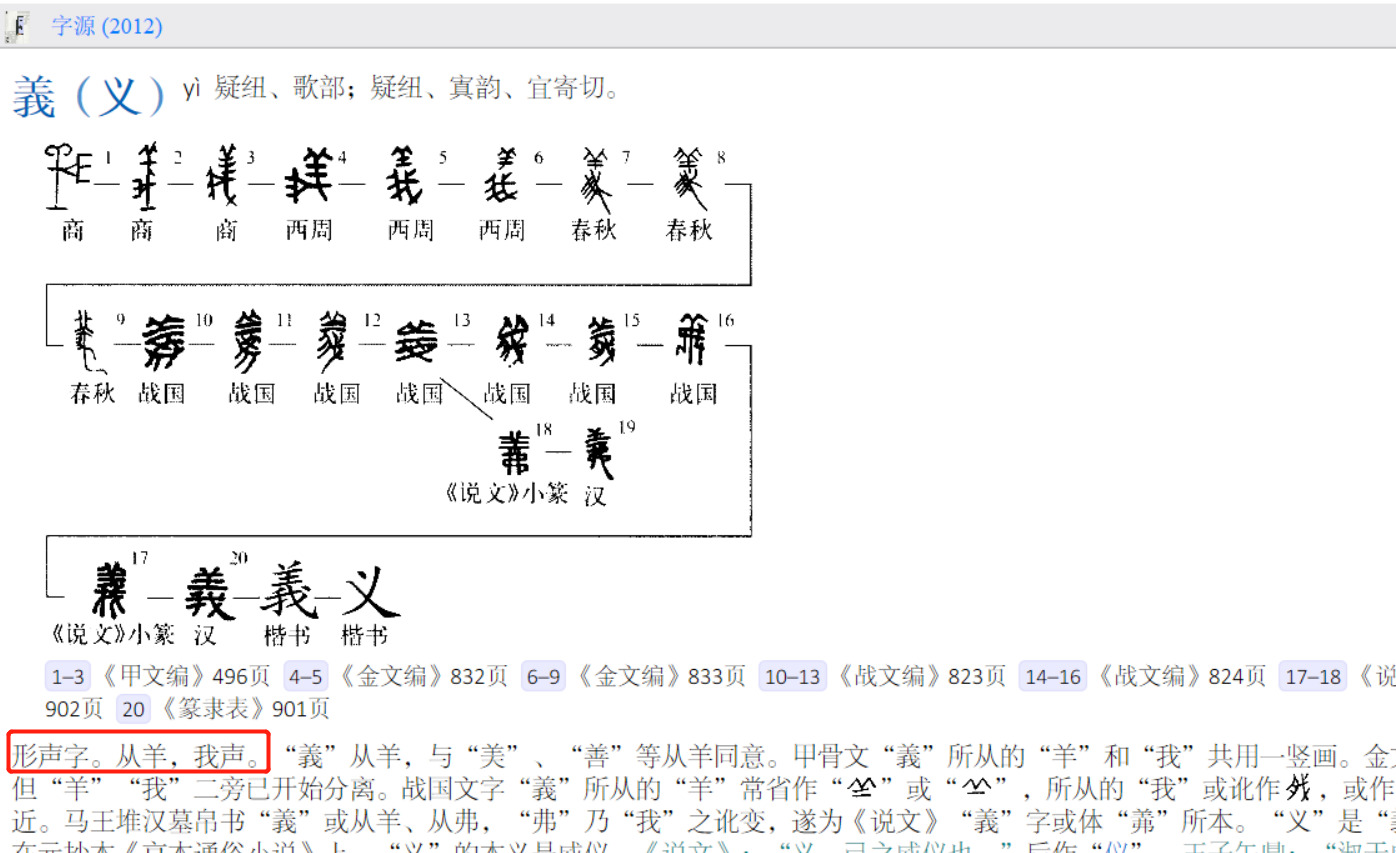

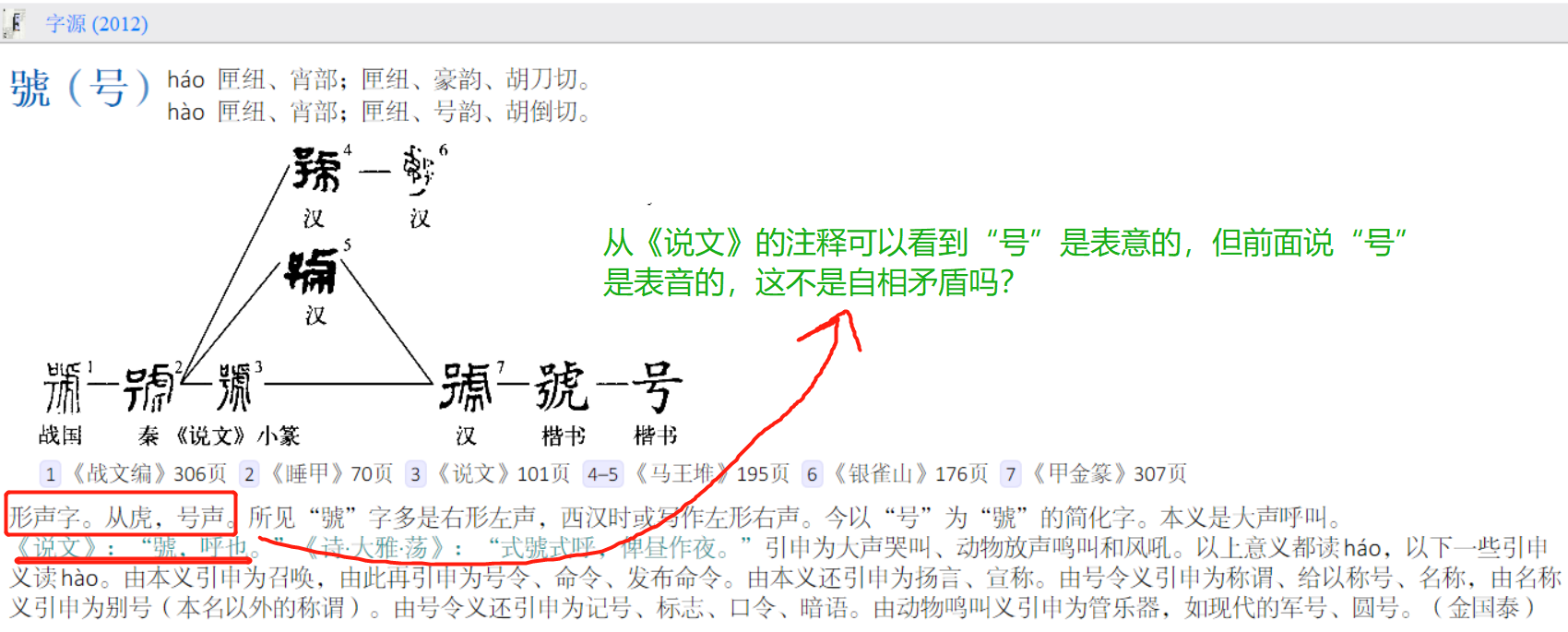
兩種說法未必互斥。說文經常有 “从A从B,B亦聲” 的分析。例如段注本:“从号,从虎”,“号亦聲”。
2 个赞