在 MDict PC 正常。那符號是用 base64 顯示的。也許那個app不支持。
我調了CSS,讓系統、全宋體當作 fallback font。
1 个赞
下载你的css问题解决了,感谢M大!
2 个赞


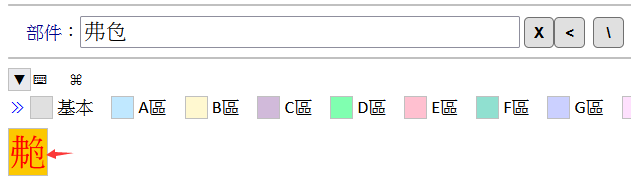
各位老师,我用的220楼大佬,链接里的2023.6.30的部件检索(里面有分割好的五个字体文件),首页面全部显示,但是在实验查“亻尔”时,黄色区域字体出现小飞碟的图标(上图),随即我用电脑也实验查询则可以全部显示,是分割的字体不是最新字体的原因,还是我手机软件(DictTango)里没有用分割的字体,但是经过实验,全宋体中的“2和F”在未分割时也可以加载到全局字体中,字体分割软件我网上找了好久没有找到可以用的,是不是我把最新字体分割后,再按照楼主说的办法修改css就可以了呢?
望各位老师指点迷津,拜谢了
翻翻楼上有弄好的适合手机的字体和CSS,不过查询过程中还有不显示的,看楼下。
1、最新的全宋体中,有3个文件需要进一步分割,你分割了吗?
2、修改css内容
我不会分割 ![]() ,只知道2和F需要分割,第三个不知道,想学分割和修改CSS,找了一圈分割软件,都不能用。不知道哪位老师可以分享这类的软件和教程,
,只知道2和F需要分割,第三个不知道,想学分割和修改CSS,找了一圈分割软件,都不能用。不知道哪位老师可以分享这类的软件和教程,
楼上分割好的不是最新的,想学学这个分割,修改CSS这样也可以按照自己的爱好修改。
2、F和X要分割,你那些没显示出来的可能是X里的。
分割我用的是FontCreator,就是按照Unicode排列后,选择一半先删除,导出后,再删掉另一半导出
研究了一天,把字体分成10个文件,照着大佬们的文件CSS修改,结果其他都显示 B区和c区不显示了,这可难死个小白了
你看看我这个分割的版本。
3 个赞

找到问题了,jcz777大佬(220楼网盘内)分解的那5个字体,和您这个,都可以显示,我用的(DictTango),是软件字体显示的问题,管理辞典-专用字体显示,这个字体必须用分解的FSung-X.tff,woff格式则不行,不知道我这是不是个例,这样操作出来两个格式的字体都可以显示。希望类似于我这种小白出现这个问题可以参考。

感谢您,用了您的css和字体,深蓝和tango都可以完美显示了
这个分割的文件里,没有FSung-m这个字体,请问是合并了,还是觉得不需要删除掉了。显示目前没有问题,再次感谢
p-调和
m-等宽(英文和数字间隔更大)
这两个文件对应的编码都是一样的,只在英文和数字上的显示有差别,你用一个就可以了
感谢,科普,最近麻烦您了
異體檢索,功能方面是完整的,但界面方面我沒空調理完,先這樣,能用。
現在沒有‘複製模式’的選項了。可以隨時複製:在搜尋結果的字“鈕”,點擊其左下角來“存字”。
3 个赞
更新力度很大,我复制一下,不方便翻墙和感兴趣的朋友可以看看
详情
異體檢字
其實「異體檢字」的想法我已醞釀多年。最早只是個模糊的概念,知道要往這方向努力,但說不上來該怎麼做、能做些什麼?直到完成了《教育部異體字字典》的字頭清理工作,這想法才逐漸清晰起來,但具體該怎麼做?仍是毫無頭緒。
隨著一次次的擴增漢字、更新字庫,我也不斷在思索,該怎麼把「異體檢字」功能融合進「部件檢索」裏?資料該怎麼安排、記錄?又該如何運算?
直到「漢字構形資料庫」的字頭清理完畢,能完整展現它的異體字表(以《漢語大字典》第一版的異體字表為基礎)後,一切時機似乎都成熟了。於是開始動手,花了一天的時間修改程式、調整操作介面,做出了一個雛形。又經過一段時間的試用、改進,終於實踐了我的想法,把「異體檢字」功能正式推上檯面。
回顧這一路走來,雖然並沒有明確地計劃,但無形中我的不成熟想法,卻似乎一路引領著我朝著特定的方向前進,結果卻像是個有系統的漸次推進,逐步完成了相關數據的收集,讓醞釀多年的想法,得以「一夕成形」。
介面調整
因應新的異體檢字功能,操作方式略有調整:
略微調動了畫面元素,讓垂直方向的版面更爲緊湊,以便有更多空間可以顯示查詢結果。
廢除了複製模式的切換,現在不管是「虛擬鍵盤」或是「查詢結果」統一都是點擊滑鼠右鍵可以直接複製。隨時點擊隨時複製,不再需要切換模式。
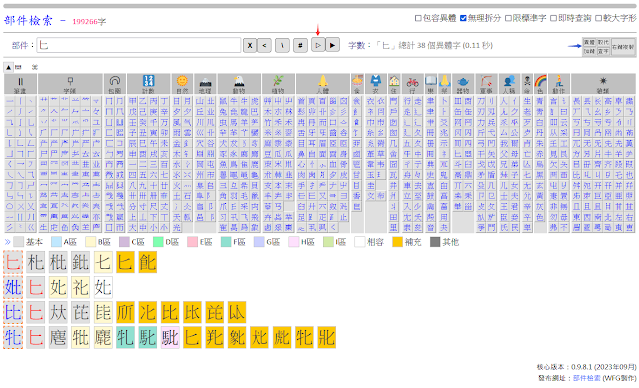
「查詢結果」的每個字塊,現在分做田字形的四個區域,左鍵點擊不同區域各有不同功能,如版面右上角的圖例所示。例如左鍵點擊字塊的左上角是查詢該字的異體字,點擊字塊的右下角預設是跳轉字統網查字。
除了原先「黑三角按鈕」的「部件查字鍵」外,新增一個「白三角按鈕」的「異體查字鍵」,可以直接在輸入框打入想查的字,再按「白三角按鈕」(或者 Shift + Enter)即可查出所有異體字。輸入框若已輸有很多字,不必消去,直接反白選擇想查的字,再按「查字鍵」即可。
異體字的查詢結果,以「正體字」領頭(橘色虛線框標示),其他異體字跟隨其後。若該字分屬於多組異體字關係,則依序折行將多組異體關係列出。
目前異體數據只是快速地粗定,《異體字字典》與《漢字構形資料庫》的異體字表有一千多組有衝突,雙方認定的正體字多有不同,必須人工一一校閱調整。尚有八百組待查,還在慢慢努力優化之中。另外簡繁漢字的異體關係也須進一步整理、增添,日後會逐步優化。
操作實例

例如要檢索「」這個字(字見於宋刊本《玉篇》):
此字右旁的部件「」略為麻煩,需拆為「⺈㔾丶」來輸入,但知道是「色」字異體,因此可以先在輸入框中輸入「弗色」兩個部件,接下來:
方法一:按一下「部件查字鍵」即可查得「艴」字。
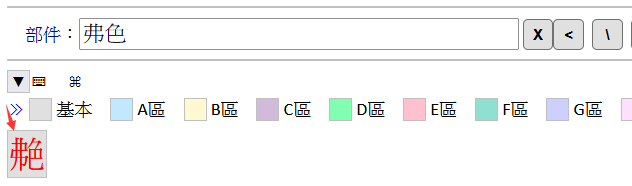
然後左鍵點擊「艴」字字塊的左上角,即可查得「艴」字的異體字「」字。
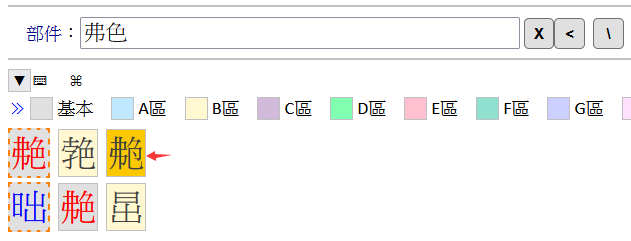
方法二:反白選取「色」字,再按一下「異體查字鍵」即可以查得「色」字的異體「」字。
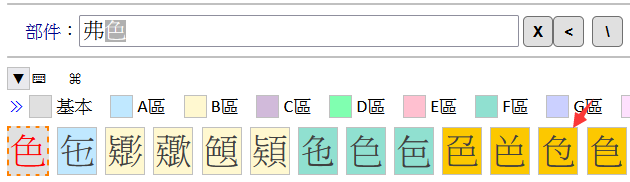
左鍵點擊「」字字塊的右上角,「」字即會替換輸入框中原先的「色」字,再按一下「部件查字鍵」即可查得「」字。
方法二的操作步驟雖然較多,但若希望能打出精確的部件時,可以用此法。只要靈活地交替使用「部件檢字」與「異體檢字」的功能,便可以快速地檢索到想要檢索的字,十方便利。"
擴展 I 區
最新的 Unicode 15.1 已經於 9 月 12 日正式發布,對於漢字來說最主要的就是新增了 622 個擴展 I 區字形。這一版的全宋體與部件檢索已經完全支援新的 I 區字形,遷碼表也已完成,共計有 229 個既有的補充字被收入擴展 I 區,也就是對「全宋體」來說實際上只有 393 個字真正屬於新增。這既有的 229 個補充字已經予以註銷,遷往擴展 I 區所定義的新碼位。我花了一天的時間將我製作的四百多部詞典全部完成遷碼,如果您的文件曾使用到這些補充字,建議您儘快利用我所提供的 I 區遷碼表完成遷碼的動作,否則一旦更新了全宋體就會導致這些字無法正確顯示。
零星增字
除了擴展 I 區之外,事實上這一版的「全宋體」還增收了一些新字。
「漢字構形資料庫」裏整理有《中文大辭典》的字頭索引,但不知何因,只收錄了 47974 個字頭,與紙本實際的 49905,短少了 1931 個。這部分八月初央請了 suns99 兄幫忙,辛苦地逐一查閱紙本,歷時一個月,把近兩千個缺漏字頭補上。我再針對缺字,新造了近二十個字形,終於補全了《中文大辭典》的所有字頭。
《全唐詩》是詩詞領域裏一部重要的彙編,這次的「全宋體」也補全了《全唐詩》的所有缺字(依據中華書局本《全唐詩》,《全宋詞》則早前即已補全),讓大家在摘錄、引用這些詩詞時,不再需要忍受缺字的痛苦。
另外論壇的 klwo 兄也提供了《古白話詞語彙釋》的詞頭缺字統計,我據以新造了 18 個字形,補足了所有的詞頭用字。此外 Mastameta 兄也陸續匯報、提供了一些缺字字形,還有就是零星補造了一些整理字書時發現的缺字。相比於上次更新,總計共增添了四百六十餘字。
字形優化
上次更新時提到「漢字構形資料庫」有 10654 個字形屬於既收字,這些字形可擇其優者替換掉「全宋體」原先質量較差的字形。這項工作前次未及完成,現在已經全部完成,共優化了數千個既收字形,提供了更好的字形品質。
優化拆分
當初向國教院申請的《教育部異體字字典》拆分數據,部件殘缺的情形十分嚴重,但由於數量龐大,一直以來我僅能邊用邊小幅度地修正,抽不出時間大規模修訂。八月中旬 Walter Pai 兄終於跳進來幫忙,協助校訂這些有瑕疵的拆分數據。九月初完成了第一批三千字的校訂,經我粗略潤飾,已經加入「部件檢索」替換掉原始的瑕疵數據,讓這三千補充字能更正確地被檢索,大幅降低了漏檢的可能性。後續大約還有一萬餘字待校,Walter Pai 兄還在努力之中,只要有新的進度,我會陸續更新給大家。
未竟之工
原本預計今年的上半年要將「漢字構形資料庫」的字頭清理完畢,下半年則開始回到「CBETA 缺字資料庫」的整理工作。前一件已如期完成,但依我目前的工作量能,十月中仍未能開始,後一件應該是難以達標了。照顧家中兩老,嚴重地壓縮了我所能支配的工作時間。不過我不會放棄,慢慢做,總有一天我能把「CBETA 缺字資料庫」的整理工作完成。
鳴謝
感謝這些原字型製作單位與作者的無私奉獻。
感謝老友 suns99 兄,總是不離不棄地與我並肩作戰。
感謝老友紫雪藍海兄,提供了許多數據,供我整理之用。
感謝好友 Mastameta 兄,陸續提供了一些勘誤與優化字形供我替換。
感謝好友 Walter Pai 兄,辛苦地協助校訂拆分數據。
感謝好友 klwo 兄,提供了許多索引數據,供我增補缺字。
2 个赞
期待大佬分割字体文件以及适配css让手机上深蓝和tango也能获得好的体验。
1 个赞