被你捉到了一个bug ![]() ,现在差不多一样了。
,现在差不多一样了。
兵贵神速哇,再次感谢楼主大大的贡献。另外还发现一个问题:查了其他的词,基本都出现了两边例句条数不一样多的现象。
非常感谢!!!
你好,手机上油猴可以简单说明一下 么
能否考虑加个来源筛选和例句长度筛选功能?
感谢楼主,词典非常好用!
与此同时我有点疑惑和想法:
- 这个全文搜索的背后使用了什么技术呢?
我自己有稍微研究过,不需要各种跨表搜索的话,PostgreSQL 加上如倒排索引优化后,速度狠不错。
而 NoSQL 的方案里最常见的就是 ES (Elasticsearch) 了,但非常消耗服务器资源。
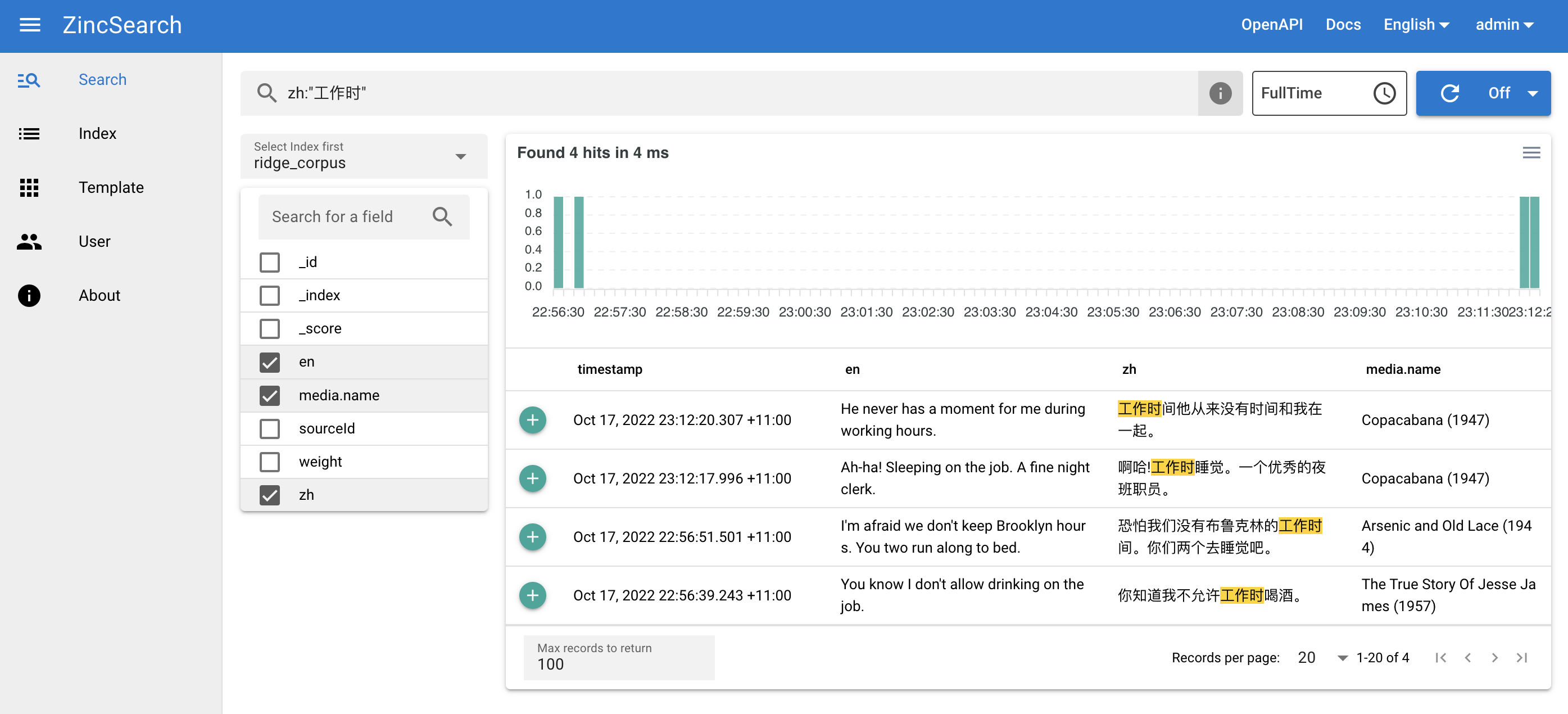
最近我发现了另一款不错的替代者,ZincSearch,用 Go 写的,非常小巧,速度很快,还兼容 ES 语法。
它还自带了一个 Vue 写的前端,这是我灌了些字幕语料后的搜索截图:
Sphinx
谢谢 hua!原来是它啊
现在用的python+sphinxsearch。不是专业开发,多亏了Google,很多条件判断,目前代码看一眼就头大了。你说的进一步优化是指代码上的,还是前端展示上的,或是更丰富的双语数据?与其优化,不如Golang之类重写,做成一个开源的全文搜索系统,Windows/Linux/MacOS也好本地部署。
明白了 搞定 谢谢啦
TIO 真的很好用,英文写作利器,再次推荐。
建议楼主有兴趣可以空闲时搜集一些行业的双语资料。比如说计算机软件的Manual、各种使用说明、介绍文章等等。说不定可以帮助程序员写他们新软件的更地道一些的英文说明哦。行业资料的好处是,一旦规模大了,也许说不定能搞成 gopilot 那样的AI翻译。
原来是这样,那你把它搭出来可真不容易!佩服!
我本人是全栈工程师,自己闲暇也在搭一个类似的项目,主攻中英字幕搜索。这是因为我有很强的地道口语查询需求,而我又担心人人词典或者欧路最后因为版权原因下线这功能。以下是一些能搜索双语字幕的产品/我想模仿的对象。
我搭到一半的时候看到你这个都已经部署了,就觉得或可一起改改?比如我上一个回复说的增加些语料,或者加入筛选功能,以便指定某本词典或者某个语料库来查询。但是你既然觉得不值得优化,那另起炉灶也没问题。
讲下我设想的技术架构吧。首先它是前后端分离的,这样每次查询不用返回一整张网页。也就是说查询只传递 payload (比如 json),这样可以节省站长的流量和服务器开销(因为服务器不用生成静态网页)。而当功能渐渐多起来后,整个网页响应也不会变慢(背后的术语是 SPA)。
前后端的话可以全部用 js 写,这样变成开源项目后,更容易让别人参与进来。原因既因为使用了同一种语言,又因为程序员中懂 js 的人非常多。(我也喜欢用 .Net 写后端,不过这不重要。)
另外,前端用一些主流的 UI 库,比如 Ant Design, Material UI 之类的,可以大大提升美观度和交互体验。
全文搜索的话,我不清楚当时为什么选择 Sphinx。或许是因为 FreeMdict 自己的全文搜索就用了它?继续用它肯定没有问题,不过我私心是想试试 Zinc。这个有许多原因。比如1)它是一个数据库+搜索引擎一体的解决方案,不需要用 SQL 存一遍数据,再在 Sphinx 里存一遍索引,反之读取也会更高效。但其实性能提升大概有限,管理上带来的方便更多吧,因为你不需要既懂 SQL 又懂 Sphinx。2)其次开发起来也更快,因为它是 NoSQL,不需要建表设键之类的,而恰好项目的主要数据就是非结构化的文本(没人想把它变成真正的结构化语料库吧,没人吧。。。)3)因为 Zinc 兼容 ES 语法,而市场上懂 ES 的程序员比 Sphinx 多不少,也有利开源。
但总之,这是个小项目,把两种全文搜索引擎都实现一遍再对比一下也废不了多少事。(偷懒图快的话,甚至后端都可以不用的。业务逻辑全部放在前端,然后直接对接全文搜索引擎的 API 就能跑了。)
哈哈,提到技术一不留神就说多了,见谅。
FreeMdict 没有自建的全文搜索。。。Zinc 的 CJK 支持怎么样?
哦。。。Zinc 已支持 CJK,内置了分词器。
新出的全文搜索都用的结巴分词。
这不好说,比如 ES 可以自己指定分词器。
emmm 你说的这些是非常专业向的需求。我理解的TIO还是比较偏泛用的。
像计算机行业的翻译,他们可以用自己的语料库或者翻译记忆库,配合CAT足够了。比如 Mozilla 基金会的 Pontoon。
当时用sphinx是因为安装使用都比较简单。20M安装包下载完就可以用,又兼容mysql语法,性能也可以,20亿字近6G的数据检索可以不超过0.1s。
现在TIO的英文演讲主要是TED,影视字幕就是上面百万字幕过滤清理过的,它的字幕有的很短,有的中英文对应不上。语料库还是要靠大家,每人贡献一点资源,贡献一点链接。