百度汉语也买了聚典数据库。
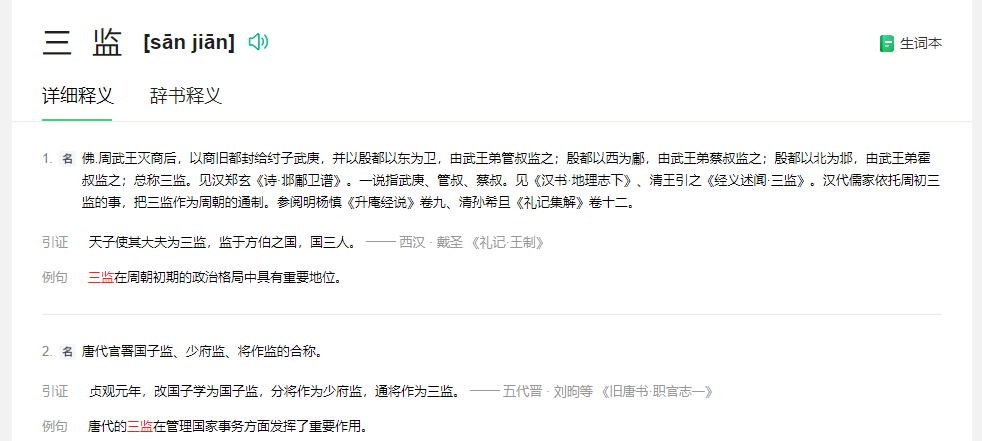
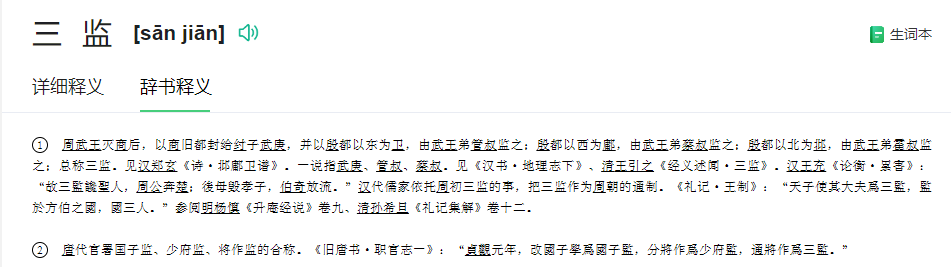
那你能帮帮我,把所有、或者尽可能多的聚点平台的网站和app的都截图放上来吗?测试的词语:性业/性業,囂浮/嚣浮,嘉应,三监/三監,划洋火,可小刀

牛,一个字9个读音,不过,其实就是湛字,汉大上湛至少也标了6个读音。
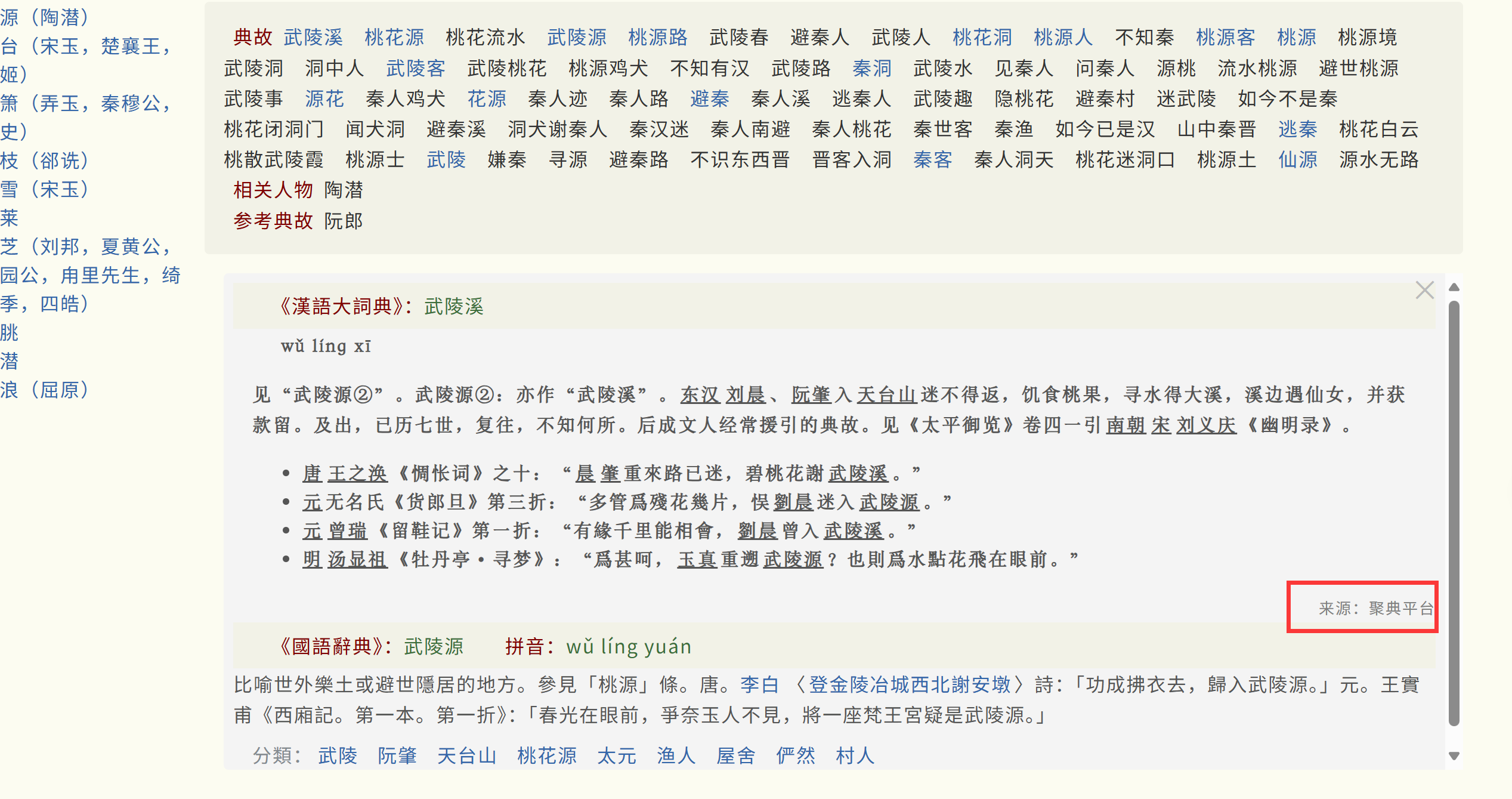
ID可以一鱼四吃,除了可以用来补全“飞地”状态的私人字词,还可以用来索引type=4的诗词,和抖音百科,抖音视频,
诗词
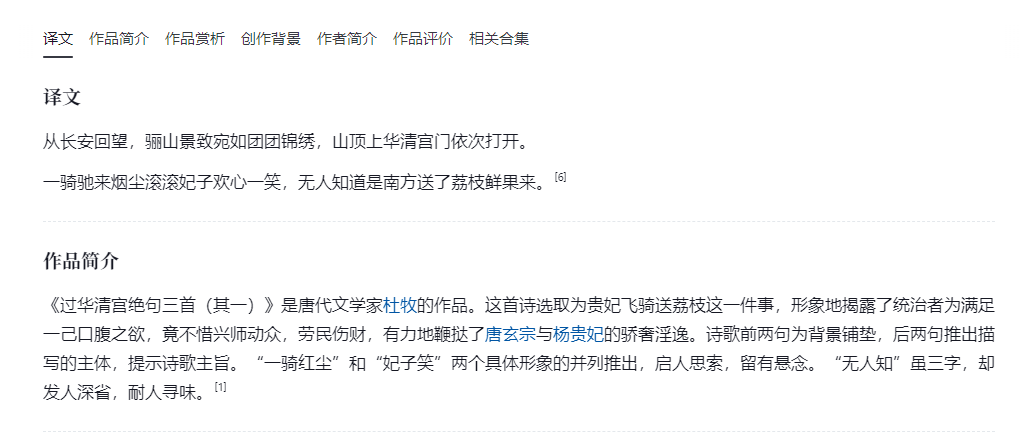
译文,简介,赏析,创作背景,都是不同的书籍,
吴鸥 . 杜牧诗文选译 . 成都 : 巴蜀书社 , 1991 . 122-123 .
杨吉元主编 . 中华经典日日诵 小学卷 5 . 杭州 : 浙江古籍出版社 , 2011-08 . 16 .
于海娣 等 . 唐诗鉴赏大全集 . 北京 : 中国华侨出版社 , 2010 . 373-374 .
萧涤非 等 . 唐诗鉴赏辞典 . 上海 : 上海辞书出版社 , 1983 . 1063-1065 .
抖音百科之杜牧
https://www.baike.com/wikiid/7182160540768206909
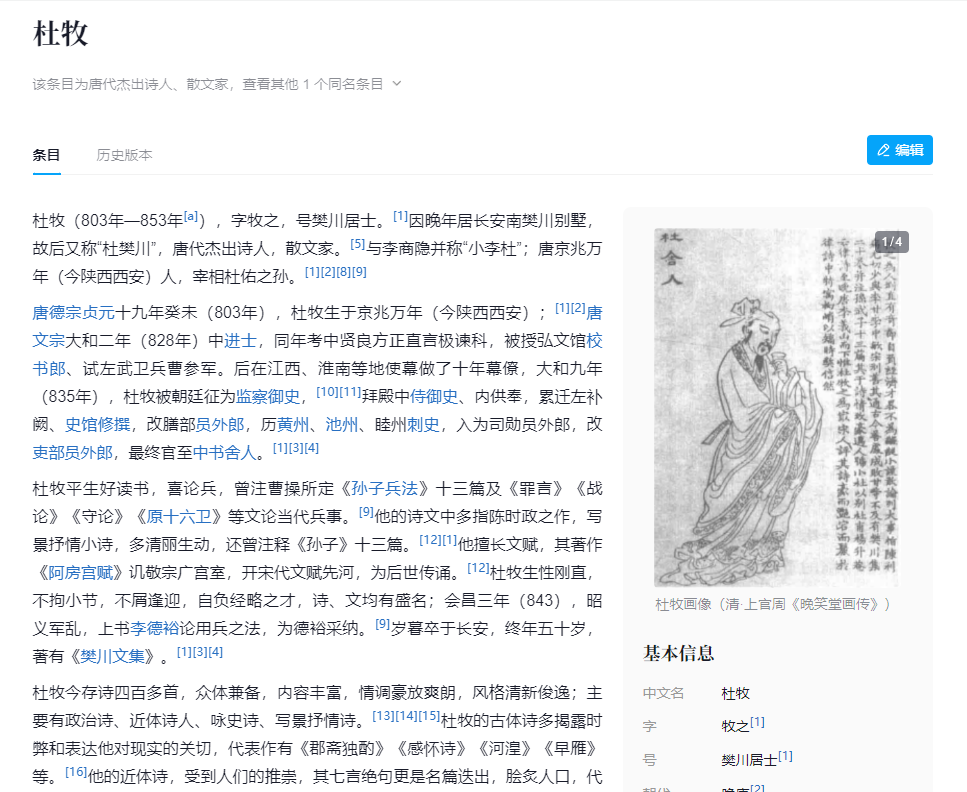
百科词条的观感也比百度的好多了,没有乱七八糟的广告,视频,
短视频之杜牧
https://www.douyin.com/video/7355450512117927204
把私人字词补齐,诗词补齐,百科补齐,岂不美哉,这一说又是大工程 ![]() 告辞
告辞
ps,思路是有的,用2.7w的汉字先走一遍之前的流程,(type=2的词,type=3的成语)过一遍type=4的诗词,此时DocID为诗词,doc_id为百科
然后百科用keyword=158w词头过一遍,
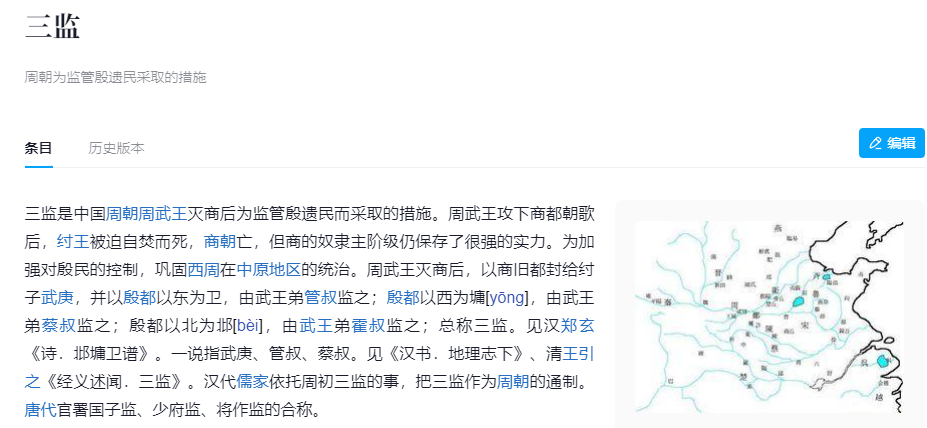
此时DocID,doc_id皆为百科,
然后左脚踩右脚,∑(DocID,doc_id)
最后就是猜测150w的ID,往私人字,诗词,百科的地址套,套中什么算什么
你补全数据我就做成mdx
现在主要就是那8000词找ID,卡住了,自动的话。成功率不是100%,手动的话眼睛看花了,让ai改代码感觉不如直接和它聊天玩, ![]()
8.24更新后,还用保留之前做的补集么。
之前的是子集,反正我已经删了
好的,那我也删。

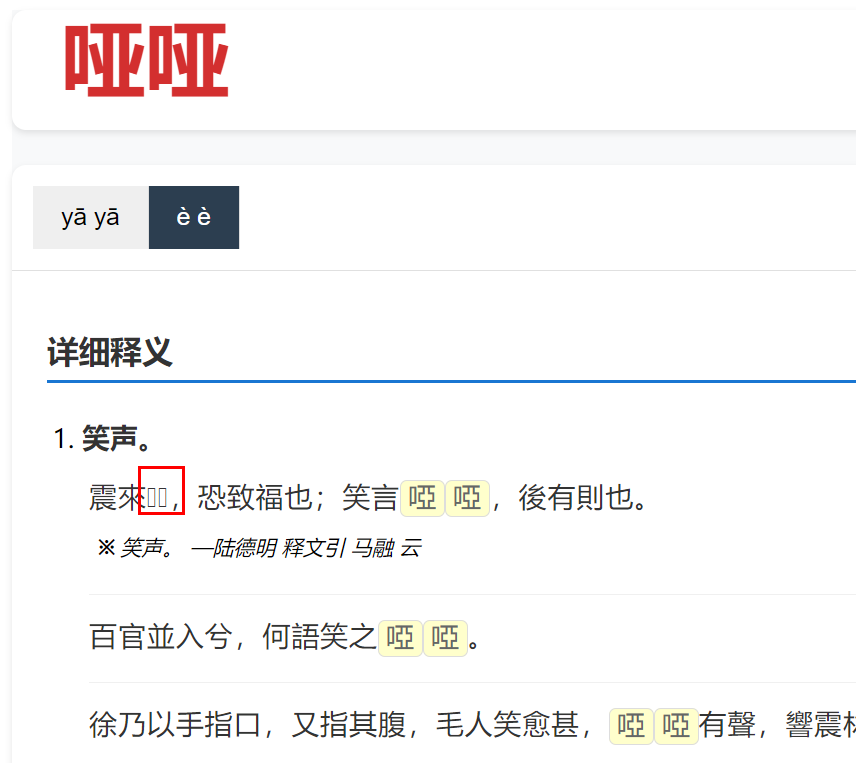

某些词头内容是全的,但是mdictpc显示为掐断的,不知为何,比如 [維嵩],新版已经修复(維嵩 - 抖音汉语)

楼上的字体文件是完整,76个字。缺少的不是字体文件,而是 Json,这76个字全部搞出来,那要抽奖。pua就是私人字,看得见搜不出来。
结构残缺,释义缺失
你打开source,内容完整的。